RF-GPT: Teaching AI to See the Wireless World
Large language models (LLMs) and multimodal models have become powerful general-purpose reasoning systems. However, radio-frequency (RF) signals, which underpin wireless systems, are still not natively supported by these models. Existing LLM-based ap…
Authors: ** - **Hang Zou** (Khalifa University) - **Yu Tian** (Khalifa University) - **B. Wang** (Khalifa University) - **Lina Bariah** (Khalifa University) - **Merouane Debbah** (Khalifa University) - **Bohao Wang** (Zhejiang University) - **Chongwen Huang** (Zhejiang University) - **Samson Lasaulce** (Université de Lorraine, CNRS, CRAN) *(소속 및 연락처는 논문 본문에 명시된 바와 동일)* --- **
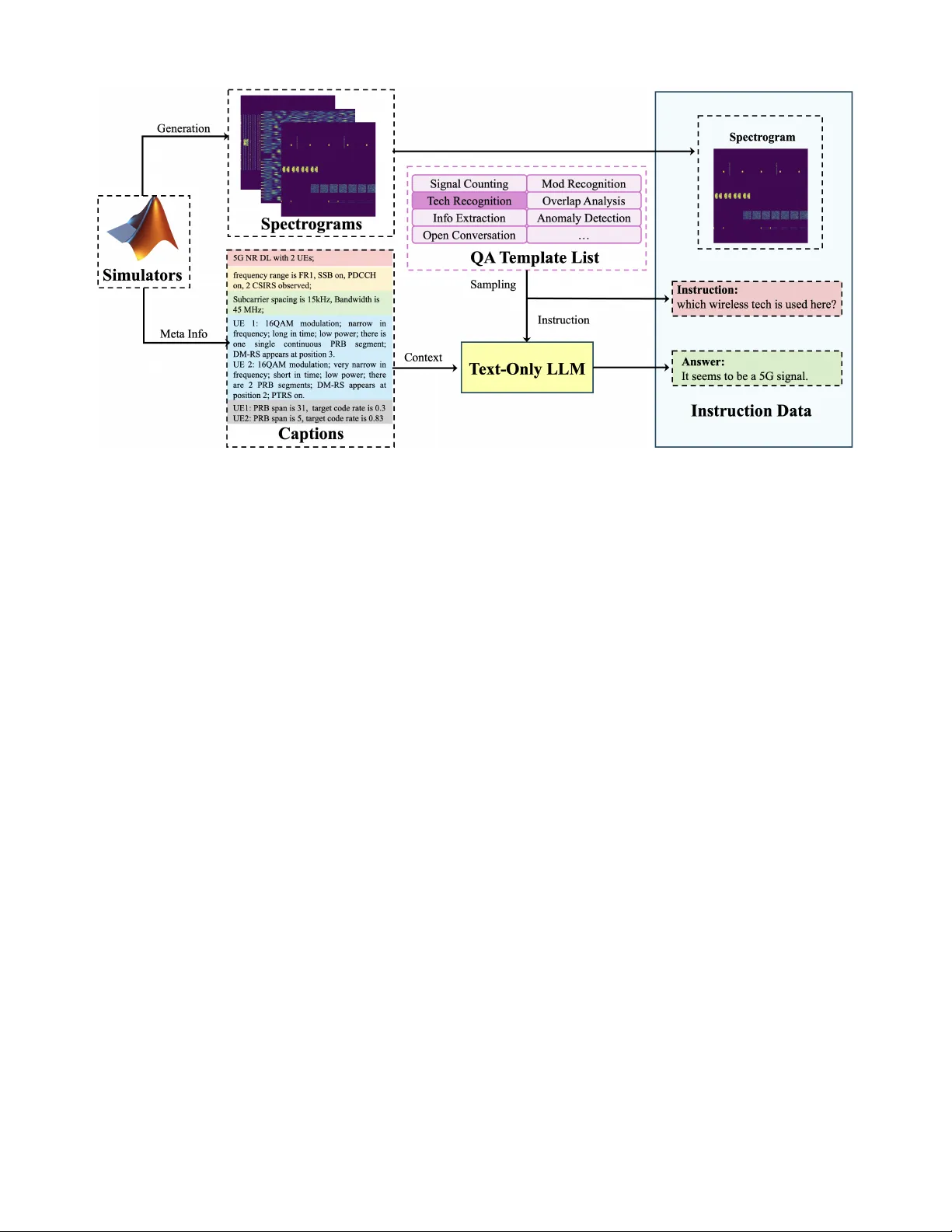
1 RF-GPT : T eaching AI to See the W ireless W orld Hang Zou, Y u T ian, Bohao W ang, Lina Bariah, Samson Lasaulce, Chongwen Huang, and M ´ erouane Debbah Abstract —Large language models (LLMs) and multimodal models ha ve become po werful general-purpose reasoning systems. Howev er , radio-frequency (RF) signals, which underpin wireless systems, are still not natively supported by these models. Existing LLM-based approaches f or telecom focus mainly on text and structured data, while con ventional RF deep-learning models ar e built separately for specific signal-processing tasks, highlighting a clear gap between RF perception and high-level reasoning. T o bridge this gap, we introduce RF-GPT, a radio-frequency language model (RFLM) that utilizes the visual encoders of multimodal LLMs to process and understand RF spectrograms. In this framework, complex in-phase/quadrature (IQ) wav eforms are mapped to time–fr equency spectrograms and then passed to pretrained visual encoders. The resulting representations are injected as RF tokens into a decoder -only LLM, which generates RF-grounded answers, explanations, and structured outputs. T o train RF-GPT , we perform supervised instruction fine-tuning of a pretrained multimodal LLM using a fully synthetic RF corpus. Standards-compliant wavef orm generators produce wideband scenes for six wireless technologies, from which we derive time–frequency spectrograms, exact configuration metadata, and dense captions. A text-only LLM then con verts these captions into RF-grounded instruction–answer pairs, yielding roughly 12,000 RF scenes and 0.625 million instruction examples with- out any manual labeling. Across benchmarks f or wideband modulation classification, overlap analysis, wireless-technology recognition, WLAN user counting, and 5G NR information extraction, RF-GPT achieves strong multi-task performance, whereas general-purpose VLMs with no RF grounding largely fail. Index T erms —Radio frequency language models, vision- language models, radio frequency signals, modulation classifi- cation, spectrograms, RF-GPT I . I N T R O D U C T I O N Large language models (LLMs) have significantly advanced natural language processing, enabling powerful capabilities in long-form generation, code synthesis, tool use, and multi-step reasoning. Multimodal systems no w extend these capabilities beyond te xt, where multimodal and vision–language models (VLMs), such as GPT -4o [ 1 ], Gemini [ 2 ], LLaV A [ 3 ], Qwen- VL [ 4 ], and InternVL [ 5 ] integrate image and text inputs to support visual reasoning, captioning, and visual question answering, among other tasks. On the other hand, in the audio domain, large transformer-based models such as Whisper [ 6 ], Qwen2-Audio [ 7 ], Minimax-Speech [ 8 ] demonstrate that mas- siv e unlabeled speech and sound corpora can be le veraged to learn robust representations for transcription, generation, and H. Zou, Y . Tian, B. W ang, L. Bariah and M. Debbah are with Research Institute for Digital Future, Khalifa University , 127788 Abu Dhabi, U AE (e- mails: { hang.zou, yu.tian, lina.bariah, merouane.debbah } @ku.ac.ae). B. W ang and C. Huang are with College of Information Science and Elec- tronic Engineering, Zhejiang University , 310027, Hangzhou, China (email: { bohao.wang, chongwen.huang } @zju.edu.cn) S. Lasaulce is with Univ ersit ´ e de Lorraine, CNRS, CRAN, F-54000 Nancy , France (email: samson.lasaulce@univ-lorraine.fr). audio understanding. Despite these advances in text, vision, and audio, radio-frequency (RF) signals, which represent the physical layer for wireless communications, radar sensing, and integrated sensing-and-communications (ISA C), have not yet been integrated into these foundation model frame works. Existing machine learning-driven RF intelligence is mainly designed based on narrow , task-specific models, for automatic modulation classification, channel estimation, beam selection, interference identification, and spectrum sensing [ 9 ], to name a few . These models are typically trained on small, heteroge- neous datasets under constrained assumptions about channel models, hardware impairments, and traffic patterns, and they are ev aluated on task-specific metrics. While such models can achiev e high accurac y , they exhibit sev eral limitations. First, each task requires its o wn architecture, dataset, and train- ing pipeline, resulting in limited reuse across tasks. Second, building di verse and well-labeled RF datasets is expensi ve and usually requires expert annotation, making large-scale supervision dif ficult. Third, models trained under particular setups experience degraded performance when deployed under different SNR ranges, channel conditions, or hardware scenar- ios. Finally , most RF models produce only labels or regression outputs, without explanations or a natural interface for hu- man interaction. Within this context, a language-model-based approach introduces a radical change in these approaches in two important ways. First, it allows multiple RF tasks to be achiev ed within a single model through instructions, rather than through separate architectures. Second, it introduces an interface for reasoning and interaction, where the model can describe what it observes, justify its predictions, and respond to follow-up questions. Instead of training a new neural net- work for each RF objecti ve, tasks can be designed as prompts that are executed ov er a shared representation. Despite recent progress on wireless and RF foundation models, such as WFM [ 10 ], L WM [ 11 ], and WirelessGPT - like channel models [ 12 ], most e xisting approaches still rely on task-specific output heads or per-task fine-tuning to achieve competitiv e performance on v arious downstream tasks. In practice, each new application (e.g., channel estimation, lo- calization, sensing, or RF classification) requires its own pre- diction head, loss design, and fine-tuning pipeline on labeled data, significantly limiting the potential of an RF foundation model . At the same time, many of these models are relatively small and optimized for a small set of benchmarks, making it difficult to balance performance across heterogeneous tasks or to scale them according to the famous scaling law [ 13 ]. In parallel, the 6G research roadmap en visions AI-nativ e networks that integrate sensing, communication, computing, and control, with autonomous, intent-dri ven operation across the radio access and core network [ 14 ]–[ 16 ]. Within this vision, LLMs have been proposed as unified interfaces for 2 knowledge access, reasoning, tool orchestration, and policy optimization, enabling automated fault diagnosis, configura- tion generation, and closed-loop network management. Early work on LLM4T elecom has explored network and service management assistants, domain-specialized instruction-tuned models, and agentic workflo ws that connect LLMs to mon- itoring systems, operations support systems (OSS) and busi- ness support systems (BSS) data [ 17 ]–[ 21 ]. T elecom-specific LLMs, such as T elecomGPT [ 22 ], inte grate domain kno wledge directly into the language model to improve its reasoning capabilities over alarms, KPIs, logs, and configuration data. Howe ver , it is important to emphasize that the integration of LLMs into telecom networks is largely te xt-centric . Existing T elecom LLMs are primarily designed to process human- readable data, including tickets, log messages, configuration tables, and structured KPIs. They do not directly process observations pertinent to the physical layer, such as RF wav e- forms, spectrograms, or channel estimates. Subsequently , this modality gap prev ents the use of LLMs in advanced RF- based tasks that require direct access to the RF spectrum, such as identifying coe xisting technologies, detecting inter - ference, analyzing occupancy patterns, or validating standard compliance at the signal le vel. Having said that, future AI- nativ e networks are not en visaged to support reasoning o ver text and structured data only , but will require as well deep RF perception capabilities that are explainable, queryable, and integrated with higher -lev el decision making. These limitations motiv ate the de velopment of radio- fr equency language models (RFLMs), which are foundation models that can process RF data and respond in natural language. In principle, an RFLM is a conditional language model grounded on RF tokens. Given an RF recording, it should be able to answer questions such as “Which modu- lations and technologies are present in this band?”, “ Are there ov erlapping transmissions and what is their time–frequency relationship?”, or “Is this behavior compliant with the relev ant wireless standard?”. Beyond simple classification, an RFLM can provide textual explanations, structured JSON summaries for do wnstream controllers, and interacti ve dialogue with RF engineers or higher-lev el LLM agents. This language interface is aimed for practical reasons, including providing a unified instruction-following interface that comprises a wide range of RF downstream tasks, facilitating the integration of domain knowledge (e.g., ITU/3GPP standards, link-budget formulas, antenna constraints) and human feedback, as well as allowing human operators and autonomous agents to query , inspect, and manage RF behavior using plain language. In this sense, RF modeling becomes more flexible and interactive, rather than isolated predictors. RF systems inherently generate large amounts of data (wideband monitoring, SDR deployments, cellular logs), and realistic simulators can produce vast amounts of labeled or semi-labeled signals under controlled conditions. This makes RF a promising candidate for self-supervised and synthetic pretraining. Using realistic wa veform generators, we can gen- erate signal-metadata samples, with accurate ground truth, such as modulation type, SNR, bandwidth, or resource alloca- tion. Such a pipeline reduces the reliance on expert annotations and enables lar ge-scale pretraining and instruction tuning. A pretrained RFLM can then be compressed or adapted for deployment across different RF scenarios, and can serve as an RF reasoning module across O-RAN, non-terrestrial networks, and ISA C scenarios, among other scenarios. Howe ver , it is worth emphasizing that realizing such an RFLM is challenging. Unlike images and audio signals, RF wa veforms are time-series, complex-v alued signals sampled at very high rates, and understanding them depends on un- derstanding time–frequency structure, protocol standards, and propagation ef fects. T o the best of the authors’ knowledge, large-scale datasets of real RF signals in diverse en vironment with expert textual annotations do not exist in the literature. Building such a dataset requires long-term RF measurements, specialized hardware, and domain experts for labeling. Over - the-air data collection also raises priv acy concerns, and typical RF en vironments are highly imbalanced, with rare but critical scenarios, such as extreme interference or unusual coexistence, being difficult to capture. In this paper , we propose RF-GPT , a radio-frequency language model that integrates RF spectrograms into a multimodal LLM. T o achiev e our objectiv es, we treat RF spectrograms as visual inputs and reuse the visual compo- nents of advanced vision–language models. Specifically , we first con vert complex in-phase/quadrature (IQ) samples into time–frequency spectrograms using STFT . These spectrograms are mapped to pseudo-RGB or grayscale images and encoded by a pretrained vision encoder to produce RF tok ens. The tokens are then projected into the language-model embedding space through a lightweight adapter, after which a decoder- only LLM generates RF-grounded text conditioned on this RF prefix. T o ov ercome the lack of RF–text pairs, we b uild a large synthetic spectrogram–caption dataset using realistic wa veform generators for wireless technologies, record full configuration metadata, conv ert it into technical captions using a deterministic captioning pipeline, and then use a strong text-only LLM to synthesize div erse instruction–answer pairs (descriptions, counting, ov erlap analysis, structured JSON). W e then perform RF-grounded supervised fine-tuning on multimodal LLM backbones (e.g., Qwen2.5-VL [ 4 ]) on this synthetic RF instruction set, without any human-annotated spectrogram labels. At inference time, RF-GPT takes an RF wav eform/spectrogram and a natural-language query and returns explanations, predictions, or structured outputs that reflect RF-aware reasoning. W e ev aluate the model on a benchmark suite cov ering wideband modulation classification, ov erlap analysis, wireless-technology recognition, WLAN user counting, and 5G NR information extraction. The main con- tributions of this paper are summarized as follows: • W e formulate the notion of a radio-frequency language model (RFLM) as a conditional language model grounded on RF tokens, and realize this concept through RF-GPT , which inte grates RF spectrograms into a multimodal LLM via a vision encoder and a lightweight modality adapter through simple linear projection. • W e design standards-compliant pipelines to synthesize a large RF spectrogram corpus for wideband settings and six wireless technologies, including 5G NR, L TE, 3 UMTS, WLAN, D VB-S2, and Bluetooth, and introduce deterministic captioning schemes that con vert signal-le vel attributes into structured textual descriptions. • W e propose an automatic instruction-synthesis frame- work that con verts RF captions into a di verse set of RF-grounded instruction–answer pairs, including explanation-style questions, quantitativ e queries (e.g., counts, overlaps), and structured JSON outputs, and we construct benchmarks that e v aluate component recogni- tion, overlap reasoning, technology identification, user counting, and NR-specific attrib ute extraction. • W e fine-tune pretrained multimodal LLMs on these syn- thetic RF instructions to obtain RF-GPT and demonstrate that RF grounding enables them to perform a range of RF understanding tasks on RF signals, including modulation classification, technology recognition, ov erlap analysis, and free-form RF question answering, while generic VLMs without RF grounding fail on the same benchmarks. I I . P R O B L E M F O R M U L AT I O N A N D R F - G P T A R C H I T E C T U R E In this section, we present the RF-GPT architecture adopted in this work. Let x ∈ C T denotes a complex baseband IQ sequence of length T samples, and let y = ( y 1 , . . . , y N ) denote a text sequence of N tok ens from a vocab ulary V . This text sequence is generally rele vant to the RF signals, e.g., a description of their characteristics or intents associated with them. W e denote by ϕ RF an RF encoder that maps the raw IQ sequence into a sequence of M RF tokens in a latent space, ϕ RF : C T → R M × d , (1) where d is the embedding dimension of each RF token. In our formulation, an RFLM is a conditional language model that generates a token sequence y gi ven an RF input x that has been encoded into a sequence of RF tokens ϕ RF ( x ) . The model defines the autore gressiv e conditional distrib ution as P Θ ( y | ϕ RF ( x )) = N Y t =1 P Θ y t | y 0 is a small constant for numerical stability . The resulting time–frequency matrix is normalized and mapped to an image I ∈ R H × W × C , where H and W are the image height and width and C is the number of channels. W e either consider A dB as a single-channel grayscale image ( C = 1 ) or apply a fix ed colormap (e.g., viridis) to obtain a pseudo- RGB image ( C = 3 ). This yields an RF spectrogram image that can be processed by a standard vision encoder E v . W e define the complete RF encoder ϕ RF as the composition of the spectrogram pipeline and the vision pipeline, as ϕ RF ( x ) = E v (I) = E v (Sp ec( x )) , (5) where Sp ec( · ) denotes the spectrogram pipeline (STFT + magnitude/dB + colormap). Patch embedding . The spectrogram image I is partitioned into a re gular grid of non-ov erlapping patches of size P × P pixels, where both H and W are divisible by P . The number of patches (and thus RF tokens) is M = H P · W P . Let x i ∈ R P 2 C denote the vector obtained by flattening the i - th patch (row-major order), for i = 1 , . . . , M . Each patch is linearly projected to a d -dimensional embedding using a learnable matrix E ∈ R d × ( P 2 C ) , e i = Ex i ∈ R d , i = 1 , . . . , M . (6) This patchification and linear projection step acts as an RF tokenizer , turning each spectrogram into a sequence of M RF tokens that the language model can consume. W e also use a learnable positional embedding p i ∈ R d for each patch index i , which encodes its 2D location on the spectrogram grid (time–frequenc y position). The input token sequence to the transformer encoder is then gi ven by z (0) i = e i + p i , i = 1 , . . . , M , (7) and we stack them into Z (0) = ( z (0) 1 ) ⊤ . . . ( z (0) M ) ⊤ ∈ R M × d . (8) Unlike some V iT variants [ 24 ], [ 25 ], we do not prepend a special classification token, instead, all M patch tokens are treated as RF tok ens and later passed to the language model. T ransformer encoder layers. The matrix Z (0) is processed by L stacked transformer encoder blocks. Each block consists 4 Fig. 1: Basic structure of RF-GPT , comprising a visio-based radio-frequency (RF) encoder (implemented by a vision encoder on RF spectrograms), an RF adapter (linear projection) that projects RF embeddings to the LLM dimension, and a decoder-only LLM. STFT stands for short-time F ourier transform. of multi-head self-attention (MHA) followed by a position- wise multi-layer perceptron (MLP), both wrapped with resid- ual connections and layer normalization. Given Z ( ℓ ) ∈ R M × d as the input to layer ℓ ( ℓ = 0 , . . . , L − 1 ), the output Z ( ℓ +1) is obtained as e Z ( ℓ ) = Z ( ℓ ) + MHA LN( Z ( ℓ ) ) , (9) Z ( ℓ +1) = e Z ( ℓ ) + MLP LN( e Z ( ℓ ) ) , (10) where LN( · ) is layer normalization and the MLP is a two- layer feed-forw ard network (FFN) with nonlinearity , applied row-wise as MLP( z ) = σ zW 1 + b 1 W 2 + b 2 , (11) for learnable weights W 1 , W 2 and biases b 1 , b 2 , and activ a- tion function σ ( · ) (e.g., GELU). The multi-head self-attention (MHA) operates as follows. For a given input U ∈ R M × d , the h -th attention head computes Q h = UW Q h , K h = UW K h , V h = UW V h , (12) A h = softmax Q h K ⊤ h √ d k , H h = A h V h , (13) where W Q h , W K h , W V h ∈ R d × d k are learnable projection matrices (query , ke y , and value for head h ), d k is the head dimension, and softmax is applied row-wise ov er the attention scores. The outputs of all heads are concatenated and linearly projected, as follows MHA( U ) = H 1 ∥ H 2 ∥ . . . ∥ H H W O , (14) where W O ∈ R ( H d k ) × d is the projection matrix and H represents the number of attention heads. After L layers, the final patch embeddings are represented as h i = z ( L ) i ∈ R d , i = 1 , . . . , M . (15) These vectors form the RF-grounded latent sequence h 1: M used for downstream conditioning. Remark. In our frame work, the vision encoder serves as the RF encoder by treating the spectrogram as an image and encoding time–frequency patterns such as modulation structure, resource allocation, interference, and coexistence into a sequence of latent RF tokens. There are two main motiv ations for transforming a vision encoder into an RF encoder , namely , (i) RF signals span very different carrier fre- quencies, bandwidths, and sampling rates across technologies, making it dif ficult to design a single raw-IQ tokenizer that is simultaneously efficient and robust for narrowband, wideband, and multi-standard scenarios, and (ii) the STFT serves as an effecti ve RF feature extractor , while a vision encoder pretrained on lar ge-scale image datasets can extract universal semantic structure from images, including spectrograms. A k ey design decision in RF-GPT is to operate on magni- tude spectrograms rather than ra w IQ signals. From a time– frequency analysis viewpoint, the spectrogram is a smoothed energy distribution associated with the signal, and can be seen as a windowed version of W igner –V ille type representations [ 26 ]. As such, many RF attrib utes of interest, e.g., occupied bandwidth, center frequency and Doppler shifts, burst timing, time–frequency sparsity patterns, and ev en modulation struc- ture, are encoded geometrically in the spectrogram and are therefore accessible to a vision encoder . It is important to distinguish between two regimes. First, true phase r etrie val aims to reconstruct the entire complex baseband wav eform from magnitude-only measurements (e.g., STFT magnitude). This problem is nontri vial, but the phase- retriev al literature shows that, under suitable redundancy and support assumptions, a signal can be uniquely determined (up to a global phase) and stably reco vered from such magnitude data; see, e.g., work on STFT phase retriev al [ 27 ] and conv ex formulations such as PhaseLift [ 28 ]. Second, in our setting we do not attempt to reconstruct x [ n ] itself, but only to infer task-relev ant attributes such as modulation family , technology , SNR regime, or o verlap structure. These tasks are man y-to-one mappings of the waveform and depend primarily on the time– frequency ener gy patterns, not on the exact sample-wise phase. 5 RF-GPT therefore uses magnitude-only spectrograms as a rich but lossy front-end representation. While they are not sufficient for all possible RF tasks (e.g., those requiring absolute phase information or precise multi-antenna phase relationships), they retain enough structure to support the perception-oriented tasks considered in this work. In Sec. IV we empirically v alidate that this spectrogram-based approach allows the model to recov er the RF attributes required by our benchmarks with high accuracy . W ith the RF encoding pipeline established, we no w describe how the resulting RF tokens are used to condition the language model and ground its predictions in RF information. B. Languag e Model Ar c hitecture and RF Conditioning The backbone of RF-GPT is a decoder-only T ransformer language model with parameters Θ LM , which are part of the ov erall parameter set Θ . The LLM operates on a sequence of token embeddings u 1:( M + N ) ∈ R ( M + N ) × d LM , where d LM is the model dimension of the LLM. W e add standard positional embeddings e.g., rotary position embeddings (RoPE [ 29 ]) to u 1:( M + N ) before passing them to the decoder layers. First, the RF encoder produces M visual tokens h 1: M = E v ( I ) , with h i ∈ R d as defined in the previous subsection. An RF adapter through simple linear projection maps these to the LLM dimension, r i = W pro j h i + b pro j ∈ R d LM , i = 1 , . . . , M , (16) where W pro j ∈ R d LM × d and b pro j ∈ R d LM are trainable pa- rameters. This linear layer plays the role of a visual–language adapter , similar to the projection modules used in LLaV A-style models [ 3 ], mapping the vision-encoder features (which en- codes RF information) into the LLM embedding space. T ext tokens y t are embedded via a standard lookup table E tok ∈ R |V |× d LM : e t = E tok [ y t ] ∈ R d LM , t = 1 , . . . , N , (17) with |V | the v ocabulary size of the LLM backbone. W e then form a single joint sequence by concatenating RF and text embeddings: u 1:( M + N ) = r 1 , . . . , r M , e 1 , . . . , e N . (18) Let U (0) ∈ R ( M + N ) × d LM be the matrix whose rows are u 1 , . . . , u M + N . The sequence is processed by L LM stacked decoder layers. Each layer follows a modern pr e-normalized T ransformer design with root mean square (RMS) normaliza- tion, grouped-query attention (GQA) with a causal mask, and a gated Up/Do wn MLP , as adopted in recent Qwen-series LLMs. For layer ℓ = 0 , . . . , L LM − 1 we write e U ( ℓ ) = U ( ℓ ) + GQA causal RMSNorm U ( ℓ ) , (19) U ( ℓ +1) = e U ( ℓ ) + MLP gated RMSNorm e U ( ℓ ) , (20) where RMSNorm( · ) is root-mean-square layer normalization [ 30 ], GQA causal is grouped-query self-attention [ 31 ] with a causal mask, and MLP gated is a gated feed-forward block (Up/Down MLP) [ 32 ]. Since decoder-only transformers and these building blocks are not yet standard in RF modeling, we briefly recall their definitions. RMS normalization. For a token vector x ∈ R d LM , RMSNorm is defined as RMSNorm( x ) = γ ⊙ x q 1 d LM ∥ x ∥ 2 2 + ε , (21) where γ ∈ R d LM is a learned scale, ε > 0 is a small constant, and ⊙ denotes element-wise multiplication. RMSNorm sta- bilizes activ ations while being slightly simpler than standard LayerNorm. Grouped-query Attention (GQA). Let U ∈ R ( M + N ) × d LM denote a generic layer input. Grouped-query attention uses H q query heads and H k key–v alue heads with H q ≥ H k . W e first compute Q = UW Q , K = UW K , V = UW V , (22) where W Q ∈ R d LM × H q d k and W K , W V ∈ R d LM × ( H k d k ) are learnable projection matrices, and d k is the head dimension. T o facilitate grouped-query computation, we reshape Q into H q separate heads and K , V into H k groups. Formally , let Q h ∈ R ( M + N ) × d k denote the h -th query head for h ∈ { 1 , . . . , H q } , and let K g ( h ) , V g ( h ) ∈ R ( M + N ) × d k represent the key and v alue heads shared by the group associated with query head h . The grouping is determined by the index function g ( h ) = ⌊ ( h − 1) /r ⌋ + 1 , where r = H q /H k is the group size, mapping the h -th query head to its corre- sponding key-v alue group index. W ith a causal attention mask M causal ∈ R ( M + N ) × ( M + N ) (entries 0 for allo wed positions and −∞ otherwise), GQA is A h = softmax Q h K ⊤ g ( h ) √ d k + M causal ! , H h = A h V g ( h ) , (23) and the heads are concatenated and linearly projected back to d LM : GQA causal ( U ) = H 1 ∥ . . . ∥ H H q W O , (24) with W O ∈ R ( H q d k ) × d LM . The causal mask enforces that po- sition t attends only to positions ≤ t , ensuring autoregressiv e generation. Gated Up/Do wn MLP . The feed-forw ard block uses a gated Up/Down structure (often instantiated with a SwiGLU-style activ ation) instead of a plain two-layer MLP . For an input matrix X ∈ R T × d LM , we compute U up = XW up + b up , (25) U gate = XW gate + b gate , (26) where W up , W gate ∈ R d LM × d ff project into a larger hidden dimension d ff , and b up , b gate ∈ R d ff . A pointwise nonlinear gating (e.g., SwiGLU) is then applied: G = ϕ SwiGLU ( U gate ) ⊙ U up , (27) MLP gated ( X ) = GW down + b down , (28) with W down ∈ R d ff × d LM and b down ∈ R d LM . The gating mechanism improves expressi vity at similar or lower compu- tational cost than a standard two-layer MLP . 6 Finally , the last decoder layer produces U L LM ∈ R ( M + N ) × d LM . W e take the final N positions corresponding to the text tokens (indices M + 1 to M + N ) and apply a linear output head and softmax to obtain the conditional distribution P Θ ( y | ϕ RF ( x )) in ( 2 ). Apart from the RF tokens being concatenated as a prefix, the LLM follo ws a modern architecture of LLMs with grouped-query attention, RMSNorm, and gated MLPs (e.g., Qwen- and LLaMA-style models). C. RF-Gr ounded Supervised F ine-T uning W ith the model structure of RF-GPT in place, we now discuss ho w to inject kno wledge of RF signals into it. T o adapt a generic VLM into an RFLM, we perform RF-grounded supervised fine-tuning (SFT) on a synthetic instruction dataset built from standards-compliant wa veform generators. W e as- sume access to a dataset D RF = ( x ( i ) , q ( i ) , y ( i ) ) K i =1 , (29) where x ( i ) is an RF wav eform (IQ samples) that can be con verted into a spectrogram image as described in Sec. II-A , q ( i ) is a natural-language instruction or question about the corresponding spectrogram (e.g., “Describe the signal types and overlaps in this RF scene. ”), and y ( i ) is the desired answer (e.g., a caption, explanation, or JSON summary). These triplets are constructed in two stages, namely , RF spectrogram captioning and RF instruction synthesis (see Sec. III ). Gi ven this dataset, RF-GPT is trained to minimize the standard autoregressi ve cross-entropy loss ov er the answer tokens, conditioned on both the RF tokens and the instruction, as follows L (Θ) = − X ( x , q , y ) ∈D RF | y | X t =1 log P Θ y t y 0 , o f ( A, B ) = 1 | F A ∩ F B | > 0 , (33) indicating whether they overlap in time and frequency , respec- tiv ely . The pairwise overlap type L type ( A, B ) is then L type ( A, B ) = neither , o t = 0 , o f = 0 , time-only , o t = 1 , o f = 0 , frequency-only , o t = 0 , o f = 1 , both , o t = 1 , o f = 1 . (34) 1 As noted in the T orchSig documentation, setting the co-channel overlap probability to zero does not completely eliminate overlapping signals. Easy (global overlap estimate): The easy WBOD task asks for a single label describing the ov erall ov erlap situation in the spectrogram (“neither”, “time-only”, “frequenc y-only”, or “both”). W e compute L type ( A, B ) for all unordered pairs ( A, B ) and aggregate as follows: • If any signals pair has L type ( A, B ) = both, the global label is both . • Else if there exists at least one pair with L type = time-only and at least one pair with L type = frequency-only, the global label is also both . • Else if there is at least one pair with L type = time-only, the global label is time-only . • Else if there is at least one pair with L type = frequency-only, the global label is frequency-only . • Otherwise, the global label is neither . The model is prompted with an instruction such as “Describe whether any signals overlap in time and/or frequency” and its answer is compared against this global label. Medium (pairwise overlap estimate): The medium WBOD task focuses on specific signal pairs. The instruction identifies two signals (e.g., by index or description), and the model must output one of the four overlap types. Ground truth is simply L type ( A, B ) as defined above. Accuracy is the fraction of correctly predicted types o ver all ev aluated pairs. Hard (overlap strength estimate): The hard WBOD task asks not only whether two signals overlap, but also how str ongly they overlap along each axis. For a pair ( A, B ) , we define time- and frequenc y-overlap ratios r t ( A, B ) = | T A ∩ T B | | T A ∪ T B | , r f ( A, B ) = | F A ∩ F B | | F A ∪ F B | , (35) with r t , r f ∈ [0 , 1] . W e quantize each ratio r into one of four lev els via ℓ ( r ) = none , r < 0 . 01 , slightly , 0 . 01 ≤ r < 0 . 3 , considerably , 0 . 3 ≤ r < 0 . 6 , almost fully , r ≥ 0 . 6 . (36) The hard label for a pair is therefore the ordered pair ℓ ( r t ( A, B )) , ℓ ( r f ( A, B )) encoding the strength of overlap in time and frequency separately . The model is asked to describe the o verlap strength (e.g., “time: slightly , frequency: almost fully”), hence, we parse its output and compute accu- racy as the fraction of pairs for which both components match the ground-truth labels. In practice, WBOD-Easy asks about ov erlap in the entire scene, WBOD-Medium tar gets specific signal pairs, and WBOD-Hard quantizes the degree of overlap in time and frequency separately into four lev els. T o keep the task well-posed and a void ambiguous references in cro wded scenes, WBOD-Medium/Hard only consider adjacent signals in the time- or frequency-sorted order . This focuses ev aluation on the most visually relev ant local interactions (where overlap is actually likely) and av oids turning WBOD into a combina- torial “find any pair” search that w ould entangle it with the modulation-recognition task, i.e., WBMC. Similar to WBMC, there are 2000 VQAs for each lev el of difficulty based on RF 10 samples with co-channel overlapping probability 0 . 6 and SNR varying from 10 - 50 dB. 3) W ireless T echnology Recognition (WTR): For WTR, an RFLM is required to identify the wireless technology present in a spectrogram and, when applicable, the link direction (downlink vs. uplink). The label space consists of technology–direction pairs derived directly from the waveform generator configuration for technologies including NR, L TE, and WLAN. Performance is reported as standard top-1 classi- fication accuracy over the test set. The test set contains 1000 samples for each of D VB-S2, Bluetooth, UMTS, and L TE, 1000 NR downlink and 1000 NR uplink signals, and 1000 WLAN-AX (11ax) and WLAN-BE (11be) signals. 4) WLAN Number of User s Counting (WNUC): WNUC ev aluates an RFLM’ s ability to estimate the number of simulta- neous users present in a wideband WLAN spectrogram. Each sample is labeled with the ground-truth user count U , denotes the number of distinct WLAN users that are acti ve within the time–frequenc y windo w represented by the spectrogram. This can be obtained from the WLAN configuration metadata. Instead of predicting the exact number of users, we formulate an easier classification task by grouping user counts into fixed- size intervals. Hence, we define three difficulty lev els: • Easy (15-user buck ets): classification over coarse bins of size B = 15 . The label is the bucket interval [ s, e ] where s = U − 1 B B + 1 , e = s + B − 1 . (37) For e xample, with B = 15 and U = 17 , we obtain [ s, e ] = [16 , 30] . • Medium (10-user buckets): identical to Easy b ut with B = 10 . For instance, with B = 10 and U = 17 , we obtain [11 , 20] . • Hard (numeric with rounding): the model outputs a single integer ˆ U . If U < 10 , the correct answer is the exact count. If U ≥ 10 , the correct answer is the nearest multiple of 10 (standard rounding): ˆ U ∗ = ( U, U < 10 , 10 · round( U / 10) , U ≥ 10 . (38) For easy and medium le vels, we report b ucket-le vel accu- racy (predicted interval matches the true interval). For hard lev el, we report the fraction of examples where the predicted integer equals ˆ U ∗ . Our benchmark test set consists of 1000 WLAN-AX samples and 1000 WLAN-BE samples. 5) New Radio Information Extraction (NRIE): NRIE fo- cuses on interpreting 5G NR spectrograms because (i) NR is a dominant cellular standard and (ii) its time–frequency struc- ture encodes rich PHY -layer information. Each NRIE sample presents a single NR spectrogram (e.g., a 10 ms window) and asks the model to answer one question about a specific attribute. The e valuated attributes are: • Number of UEs: estimate ho w many distinct UE trans- missions are present. The response is a single integer , deriv ed from the model’ s te xt output. • Subcarrier spacing (SCS): classify the SCS in kHz from a discrete candidate set (dataset-specific). The response must be one of the listed numeric labels (e.g., “15”, “30”). • SSB patter n (DL only): identify the SSB pattern (e.g., A/B/C/...) for downlink spectrograms. If no SSB is present, the label is “N/A ”. • CSI-RS count (DL only): count the number of distinct CSI-RS resources configured in downlink. The response is a single inte ger . • SRS count (UL only): count the number of distinct SRS resources in uplink, the response is a single integer . NRIE therefore ev aluates a model’ s ability to e xtract ke y NR parameters from visual e vidence alone, with some questions conditioned on link direction (DL/UL). For all NRIE tasks, we report exact-match accuracy between the parsed model output and the ground-truth label. Our test set for NRIE consists of 1000 DL samples and 1000 UL samples. More fine-grained NR features, such as PTRS and per-UE DMRS patterns or detailed PDCCH/PUCCH and CORESET configurations, will be considered in future work. It is worth noting that the hard- lev el benchmarks are designed to require a certain degree of reasoning capability , such that they can serve as meaningful indicators for future RFLMs. I V . E V A L UAT I O N S A. Experimental Settings W e build RF-GPT on top of Qwen2.5-VL with 3B and 7B parameters, denoted as RF-GPT -3B and RF-GPT -7B, re- spectiv ely , each of which is fine-tuned on the synthetic RF instruction dataset. As baselines, we ev aluate the off-the- shelf Qwen2.5-VL-3B-Instruct, Qwen2.5-VL-7B-Instruct, and GPT -5 without any RF-specific fine-tuning. W e fine-tune both models, RF-GPT -3B and RF-GPT -7B, with 3 epochs using AdamW [ 35 ] with learning rate 2 × 10 − 4 , global batch size 256, 5% w arm-up and a cosine decay schedule. All models are trained with mixed precision (BF16) in PyT orch on 8 NVIDIA H200 GPUs with 140 GB video memory . For all experiments, complex baseband IQ sequences are conv erted into spectrograms using an STFT with a Blackman window (no centering, FFT shift along the frequency axis), FFT size 512, windo w length 512 samples, and hop size 512 samples. The magnitude spectrogram is con verted to dB, clipped to a fixed dynamic range, and resized to 512 × 512 pixels, the vision encoder processes non-overlapping 14 × 14 patches, yielding 1369 RF tokens per spectrogram. All RF instructions are generated following the procedure e xplained in Sec. III with GPT -OSS-120B [ 36 ]. In total, our synthetic pipeline generates approximately 12,000 distinct RF scenes and 0.625 million RF-grounded instruction–answer pairs. B. General-Purpose VLMs Have No RF Priors T o further moti vate RF-GPT frame work and sho wcase its potential, we first study whether existing general-purpose VLMs possess any useful RF prior . First, we compare the response of RF-GPT -7B and its base model Qwen2.5-VL-7B- Instruct for a concrete 5G DL signal in Fig. 5 . W e can observe that the response of general-purpose VLM is shallow and does 11 not provides any meaningful information. On the other hand, RF-GPT provides a grounded and accurate answers including SSB patterns, e xistence of CSI-RS, number of UEs and their time/frequency occupancy . Then, we ev aluate Qwen2.5-VL-3B-Instruct, Qwen2.5-VL- 7B-Instruct, and GPT -5 directly on our RF benchmarks, using carefully designed prompts that: • explicitly state that the input image is an RF spectrogram, • describe the axes as time (horizontal) and frequency (vertical), • and ask for concrete, machine-parsable answers (modu- lation labels, overlap categories, counts, etc.). Despite the well-designed prompt, the scores of these models are close to random guessing, where models either limit their output to a few frequent labels, or or distribute their predictions almost uniformly across the candidate options, indicating a lack of meaningful RF priors. On WBMC (Fig. 6 ), general- purpose models’ accuracies are within a few percent of random guessing, and they almost ne ver predict the correct number of signals (below 5%). Howe ver , RF-GPT models scored exceptional accuracy performance exceeding 97%. On WBOD (Fig. 7 ), the performance of general-purpose ones when tested on easy , medium, and hard overlap tasks is similarly low (typically in the single-digit to lo w-teens percentage range), again emphasizing chance-lev el prediction. On WTR (Fig. 8 ), the tested models exhibit biased predictions, frequently ov er- predicting L TE downlink and underperforming on most other technologies and link directions. For WNUC and NRIE (Fig. 10 and Fig. 11 ),performance remains low . In many cases, predictions appear to rely on simple heuristics, or the models produce free-form outputs that cannot be reliably parsed and are therefore marked as incorrect. These results confirm that current general-purpose VLMs hav e no RF prior , any non-zero scores are stemmed from random guessing and not from real RF understanding. This moti vates RF grounding and specialized instruction tuning, as done in RF-GPT . C. Benchmark Results: RF-GPT vs. Gener al-purpose Models Here, W e present the performance of RF-GPT on the proposed benchmarks and compare it against general-purpose VLMs. Across all tasks, RF-GPT dramatically outperforms the baseline models, validating the ef fecti veness of spectrogram- based RF grounding. This was clearly demonstrated through the scores of general-purpose VLMs, where their predictions behav e lik e dif ferent forms of randomness, depending on the prompt and model. Therefore, the scores of general-purpose VLMs serve as a comparison reference only . WBMC: Fig. 6 presents the WBMC results. General- purpose VLMs achiev e at most 7% accuracy on the easy task and close to 0% on the hard task, with an av erage score below 2% . These extreme low scores are due to our strict time- order awareness and number matching criteria. In fact, most of general-purpose VLMs fail to predict the number of signals presented in the spectrogram. In contrast, RF-GPT -3B reaches 80 . 0% / 71 . 4% / 43 . 7% accuracy on Easy / Medium / Hard, and RF-GPT -7B further improves the accuracy performance to 82 . 4% / 74 . 2% / 47 . 8% , with respect to the same levels. The An Example of 5G NR Do wnlink Spectrogram with One UE User: Describe what do you observ e in this RF scene. Qwen-2.5-VL-7B-Instruct : This spectrogram displays a v ariety of radio-frequency (RF) signals. In the central region, there are se veral prominent v ertical lines, sug- gesting strong, narro wband transmissions that could be from specific transmitters such as amateur radio stations, radar systems, or other point-to-point communication devices. T o the right, there are fainter , more dispersed lines, which might indicate lower po wer transmissions or background noise. The overall pattern suggests a mix of acti ve and passi ve RF activity within the observed frequency range. RF-GPT -7B : The spectrogram shows a single-UE 5G-NR do wnlink capture in the FR2 band. A SSB is present, following the Case D transmission pattern, and the PDCCH is also active. No CSI-RS traces are visible, confirming that CSI-RS transmission is disabled for this capture. The data payload occupies one continuous block of PRBs. The occupied bandwidth is moderate. In the time dimension the burst is short , lasting only a few symbols before the signal fades. The overall power lev el of the b urst is low , giving the spectrogram a faint intensity compared with typical high-power carriers. Fig. 5: Comparison between general-purpose VLM and RF- GPT on a 5G DL spectrogram with only one UE. General- purpose VLM such as Qwen2.5-VL-7B has no RF prior and fails to extract any useful information from the spectrogram. av erage score increases lar gely after RF-grounded finetuning of both 3B and 7B models. Importantly , RF-GPT correctly identifies the number of signals in around 98% of the cases, while general VLMs almost f ail all the cases. These results indicate that RF-GPT can both estimate the number of acti ve signals and correctly identify their modulation types in com- plex wideband input. WBOD: WBOD results are shown in Fig. 7 . General- purpose VLMs perform marginally abov e chance. Their easy-lev el accuracies range from approximately 23 – 25% , medium-lev el accuracies remain around 30% , and hard-level time–frequency overlap classification drops to 5 – 12% , re- sulting in ov erall av erage scores of roughly 11 – 16% . These 12 WBMC-Easy WBMC-Medium WBMC-Hard 0 20 40 60 80 100 Accuracy / Percentile (%) 0.5 0.1 0.0 4.0 1.3 0.1 7.0 5.3 3.0 80.0 71.4 43.7 82.4 74.2 47.8 Qwen2.5-VL-3B-Instruct Qwen2.5-VL-7B-Instruct GPT-5 RFGPT-3B RFGPT-7B Fig. 6: Benchmark scores on the wide-band modulation clas- sification (WBMC) tasks. RF-GPT can classify modulation presented in a spectrogram in coarse modulation family while general-purpose VLMs hav e almost no knowledge on RF modulations. In fact, most of the time these models fail to identify the number of presented RF signals. WBOD-Easy WBOD-Medium WBOD-Hard 0 20 40 60 80 100 Accuracy / Percentile (%) 22.9 31.0 3.4 24.7 30.9 12.9 25.0 28.9 20.1 91.2 85.2 65.0 91.5 87.6 71.7 Qwen2.5-VL-3B-Instruct Qwen2.5-VL-7B-Instruct GPT-5 RFGPT-3B RFGPT-7B Fig. 7: Benchmark scores on the wide-band ov erlap detection (WBOD) tasks. RF-GPT can perform overall and per-pair ov erlap detection in both time and frequenc y domains, whereas general-purpose VLMs behave close to random. numbers are partly influenced by a biased prediction pattern in which the models frequently select the “none” label, ev en though only a small fraction of signal pairs exhibit no overlap in either time or frequenc y . In contrast, RF-GPT -3B achie ves 91 . 2% (Easy), 85 . 2% (Medium), and about 65 . 0% accuracy on the hard joint time–frequency overlap task. RF-GPT -7B further improves the hard-task accuracy to 71 . 7% , with similar or slightly better performance on the easy and medium tasks. These results indicate that RF-GPT can reason coherently about whether signals ov erlap in time and frequency and to what e xtent, whereas generic VLMs produce essentially random overlap labels. WTR: Fig. 8 summarizes WTR performance. Qwen2.5-VL series achiev e a joint technology+link accuracy of only 5 . 01% (3B) and 4 . 98% (7B), with highly inconsistent behavior across technologies. For e xample, Qwen2.5-VL-3B-Instruct predicts L TE reasonably often but almost nev er identifies NR, UMTS, WLAN, or D VB-S2 correctly , and its link-direction predic- tions are heavily biased (e.g., alw ays “DL ”). GPT -5 does not Technology Link Direction Joint Accuracy 0 20 40 60 80 100 Accuracy / Percentile (%) 11.8 29.8 5.0 14.1 56.5 5.0 29.1 32.5 12.0 99.8 99.5 99.4 99.9 99.6 99.6 Qwen2.5-VL-3B-Instruct Qwen2.5-VL-7B-Instruct GPT-5 RFGPT-3B RFGPT-7B Fig. 8: Benchmark results for wireless technology recognition (WTR) benchmark. RF-GPT nearly perfectly identifies wire- less technologies and link directions, while general-purpose VLMs collapse on most classes. Bluetooth DVB-S2 LTE NR UMTS WLAN Predicted Technology Bluetooth DVB-S2 LTE NR UMTS WLAN True Technology 999 0 0 1 0 0 0 999 1 0 0 0 0 1 995 4 0 0 3 1 3 1993 0 0 0 0 0 0 1000 0 0 0 2 0 0 1998 0 500 1000 1500 Fig. 9: Confusion matrix of WTR task. RF-GPT is capable of identifying dif ferent technologies with almost perfect accuracy . produce any consistent correct predictions under our parsers. In contrast, RF-GPT -3B achie ves 99 . 42% joint accuracy , with almost perfect per-technology and per-link scores ( ≥ 99 . 5% on most classes). RF-GPT -7B further impro ves to 99 . 64% joint accuracy and close to 100% on most individual technologies and link directions. This shows that RF-GPT has learned a highly reliable RF taxonomy across heterogeneous standards. WNUC: WNUC results are presented in Fig. 10 . General- purpose VLMs achie ve average accuracies of 23 . 97% (3B) and 22 . 83% (7B) across all difficulty levels and both WLAN standards (11ax/11be). The y struggle particularly on the hard (numeric) task, where accuracies are around 13 – 14% . After RF grounding, the same backbones achiev e much higher scores, where the 3B model attains an a verage of 65 . 43% , and the 7B model reaches 70 . 17% . In particular , both model variants exhibit consistent higher performance in the 802.11be standard compared to 11ax. For RF-GPT -3B, we observe absolute accuracy gains of 13 . 7% , 6 . 6% , and 6 . 1% for the easy , medium, and hard difficulty le vels, respecti vely . Simi- larly , for the larger RF-GPT -7B model, the gains are 12 . 2% , 13 6 . 6% , and 4 . 2% , respectively . This performance difference is stemmed from the different resource mapping strategies used during data generation. While 11be samples typically assign a single user per Resource Unit (R U), 11ax samples frequently in volv e multiple users sharing a single RU through MU-MIMO. The latter creates significant visual overlap in the time-frequency plane, masking the indi vidual user signatures and making the counting task more challenging for a vision- based backbone compared to the spatially distinct OFDMA patterns in 11be. This demonstrates that RF-GPT can infer approximate user counts directly from OFDMA/MU-MIMO structures in WLAN spectrograms. NRIE: NRIE results are shown in Fig. 11 . General-purpose VLMs perform poorly on NR-specific attributes, with aver - age accuracies around 20% and substantial variation across tasks (e.g., slightly better on UE count, b ut weak on SSB pattern and SCS). After RF grounding, RF-GPT -3B reaches an av erage accuracy of 72% , with near -perfect SCS and SSB pattern recognition and moderate performance on UE number estimation, CSI-RS, and SRS resources. RF-GPT -7B achieves similar or impro ved performance on most tasks (notably higher SRS and UE estimation), confirming that larger models can extract richer NR structure from spectrograms. Overall, NRIE shows that RF-GPT is not limited to generic modulation or technology recognition, but it can also recov er protocol- specific parameters that are crucial for 5G NR analysis. T aken together , these results show that RF-GPT consistently turns general-purpose VLMs, which hav e no RF prior, into strong RF foundation models that perform well across a di- verse suite of benchmarks, including modulation classification, ov erlap analysis, technology recognition, number of users estimation, and NR-specific attrib ute extraction. D. Ablation Studies W e perform ablation studies on dif ferent configurations. W e select one benchmark that we believ e to be the most sensitiv e to a giv en configuration and apply it to data samples related to this benchmark only instead of the whole dataset to avoid extra data processing. Robustness against impairments. W e start by ev aluating the rob ustness of RF-GPT to common RF impairments. For impairment-sweep experiments, we v ary one impairment fam- ily at a time, including IQ (IQ) imbalance, power amplifier (P A) nonlinearity , carrier frequency offset (CFO), or time- varying multipath (TDL), while reusing a common clean wa veform as a base. W e introduce a normalized impairment lev el λ ∈ { 0 . 2 , 0 . 4 , 0 . 6 , 0 . 8 , 1 . 0 } , with λ = 0 correspond- ing to the clean baseline. During training, we include only spectrograms with relatively mild impairments ( λ ≤ 0 . 3 ), so that robustness to larger distortions must arise from gen- eralization rather than direct exposure during training. For IQ imbalance, the gain mismatch between I and Q branches increases from 0 to 8 dB and the phase mismatch from 0 ◦ to 15 ◦ across the sweep. For P A nonlinearity , we gradually mov e from a relativ ely linear amplifier with a high saturation lev el and smooth Rapp characteristic to a stronger , more abrupt saturation with lower ef fectiv e backof f. CFO is swept from 0 to 1200 Hz, and the TDL channel ev olves from a flat channel to one with delay spreads up to 500 µ s and maximum Doppler shifts up to 200 Hz, with the TDL profile randomly chosen from TDL-C and TDL-D in the MA TLAB API. This setup enables a controlled robustness analysis in which the impairment strength changes while the underlying wa veform content remains fixed. Fig. 12 reports NRIE performance of RF-GPT -7B under increasing impairment se verity for CFO, TDL, P A, and IQ imbalance. Starting from a clean score of 76 . 31% , CFO and P A sweeps cause only minor degradation and the curves remain nearly flat, while TDL introduces a moderate drop. In contrast, IQ imbalance produces the largest and nearly monotonic performance decline, from 75 . 29% at the lowest nonzero le vel to 70 . 21% at the highest le vel (about 6 . 1 percentage points below clean). The observed ranking aligns with ho w each impairment alters spectrogram structure, where the CFO primarily shifts energy along the frequency axis while preserving local time–frequency patterns, moderate P A nonlinearity mainly compresses amplitudes and generates in- band distortion without radically changing the layout of NR structures, TDL spreads and fades components but often keeps coarse OFDM structure visible, IQ imbalance, howe ver , intro- duces strong image-frequency components and cross-leakage, creating mirror-like or duplicated patterns that directly inter - fere with counting and structural cues used by NRIE (e.g., UE-related re gions and reference-signal layouts), making it the most destructive of the considered impairments. Comparison with CNN/T ransformer baselines. T o com- pare RF-GPT with strong non-LLM baselines, we implement spectrogram-based CNN and T ransformer models for the NRIE benchmark. Each model tak es the NR spectrogram as input, passes it through a shared backbone (e.g., Efficient- Net [ 37 ] or V iT [ 24 ]), and applies global av erage pooling to obtain a feature vector . On top of this backbone, we attach separate task-specific heads for each NRIE attribute, reflecting the heterogeneous nature of the benchmark. The SCS and SSB heads are implemented as linear layers with softmax outputs ov er their respective label sets, whereas the counting heads are implemented as small classifiers over the admissible count range for number of UEs, CSI-RS and SRS, with the predicted integer given by the arg max of the logits. The overall NRIE loss is an equally weighted sum of the per-head cross-entropy terms. Howe ver , these task-specific customizations underscore the narrow generalization of con ventional deep neural net- works compared to a unified instruction-following RFLM. Fig. 13 compares NRIE performance across training progress for RF-GPT and CNN/T ransformer baselines includ- ing Ef ficientNet and V iT -B, V iT -H. RF-GPT -7B consistently achiev es the best score, improving from 69 . 99% (epoch 1) to 76 . 96% (epoch 3). RF-GPT -3B also improves steadily , from 67 . 17% to 71 . 83% by epoch 3, which is already close to V iT - B at epoch 30 ( 72 . 34% ) and slightly higher than Efficient- Net at epoch 30 ( 70 . 85% ). Among the non-LLM baselines, V iT -H is strongest, increasing from 65 . 21% to 76 . 39% by epoch 30, while V iT -B and EfficientNet reach 72 . 34% and 70 . 85% , respectiv ely . Overall, RF-GPT -7B still outperforms the strongest V iT -H baseline slightly while using only 3 14 WNUC-Easy (AX) WNUC-Easy (BE) WNUC-Medium (AX) WNUC-Medium (BE) WNUC-Hard (AX) WNUC-Hard (BE) 0 20 40 60 80 100 Accuracy / Percentile (%) 35.2 38.3 23.0 19.9 13.6 13.8 30.3 35.9 20.7 22.4 13.9 13.8 13.0 7.5 5.5 7.5 6.5 3.0 73.0 86.7 62.5 69.1 47.6 53.7 75.9 88.1 67.7 74.3 55.4 59.6 Qwen2.5-VL-3B-Instruct Qwen2.5-VL-7B-Instruct GPT-5 RFGPT-3B RFGPT-7B Fig. 10: Benchmark scores on the WLAN number of users counting (WNUC) tasks for 802.11ax and 802.11be. RF-GPT with different model sizes is capable of estimating the number of UEs directly from spectrograms. CSIRS SRS UE SSB Pattern SCS 0 20 40 60 80 100 Accuracy / Percentile (%) 3.7 6.7 24.2 23.0 20.4 5.5 5.3 25.6 7.2 24.1 13.3 8.3 26.6 11.1 13.7 43.7 57.2 59.2 87.1 98.2 48.7 69.1 64.2 94.1 99.1 Qwen2.5-VL-3B-Instruct Qwen2.5-VL-7B-Instruct GPT-5 RFGPT-3B RFGPT-7B Fig. 11: Benchmark results for the Ne w Radio information e xtraction (NRIE) benchmark. RF-GPT is capable of accurately extracting the SCS in kHz, identifying SSB pattern and estimating the number of UEs, CSI-RS and SRS. epochs instead of 30, indicating better data efficiency and stronger instruction-conditioned RF reasoning. This behavior is related to the NRIE task structure, where jointly inferring heterogeneous attributes benefits from a unified language- conditioned model more than from fixed closed-set multi- head classifiers. The sharp improvement of RF-GPT -7B during training suggests that RF instruction tuning rapidly captures task-specific priors, whereas baseline models impro ve more slowly ev en with extended training. In contrast to multi- head CNN or Transformer classifiers that require separate architectures and supervision for each NRIE task, RF-GPT relies on a unified model trained with a single tok en-lev el cross-entropy objective. Different NR attributes are handled naturally through language instructions, without modifying the architecture. This unified RF–language interface simplifies the overall design while producing structured, human-readable 15 0 1 2 3 4 5 Impairment Level 70 72 74 76 NRIE Score (%) CFO PA TDL IQ Fig. 12: NRIE ablation vs. impairment le vel of IQ imbalance (IQ), power amplifier nonlinearity (P A), time delay channel (TDL) and and carrier frequency offset (CFO). RF-GPT main- tains high accuracy except for IQ due to its destructiv e in- troduction of cross-leakage, mirror-lik e creation or duplicated patterns. 1 2 3 30 Epoch 55 60 65 70 75 NRIE Score (%) RFGPT-7B RFGPT-3B ViT-H ViT-B EfficientNet Fig. 13: NRIE ablation comparing RF-GPT and Trans- former/CNN baselines across epochs; RF-GPT -7B consistently leads, and even after 30 epochs the best CNN/T ransfomer baseline remains belo w RF-GPT , highlighting the advantage of RF-grounded finetuning. outputs (e.g., explanations or JSON summaries) rather than only numeric predictions, making the system easier to interpret and integrate with higher-le vel LLM agents. Image resolution W e end the ablation study by analyzing the impact of input image resolution on WBMC. W e ev aluate RF-GPT -7B at 224 , 384 , and 512 , as shown in Fig. 14 . The performance improves consistently as resolution increases, where WBMC-Easy rises from 72 . 94% → 78 . 72% → 82 . 41% , WBMC-Medium from 64 . 52% → 71 . 26% → 74 . 24% , and WBMC-Hard from 39 . 64% → 43 . 76% → 47 . 94% . From 224 to 512 , the absolute gains are +9 . 47 (Easy), +9 . 72 (Medium), and +8 . 30 (Hard) points. These results indicate that higher-resolution spectrograms preserve more discriminativ e time–frequency details and benefit both coarse and fine-grained modulation recognition. Howe ver , increasing image resolution also increases RF token count, leading to WBMC-Easy WBMC-Medium WBMC-Hard 0 20 40 60 80 100 Accuracy / Percentile (%) 72.9 64.5 39.6 78.7 71.3 43.8 82.4 74.2 47.8 RFGPT-7B (224) RFGPT-7B (384) RFGPT-7B (512) Fig. 14: WBMC ablation of RF-GPT -7B under dif ferent image resolutions. Larger image resolution leads to better accuracy thanks to finer RF tokens. higher memory/computation cost and longer inference latency . V . C O N C L U S I O N In this paper , we introduce the concept of RFLM and present RF-GPT as its first realization. RF-GPT integrates RF spectrograms into a multimodal LLM, enabling a unified interface between RF signals and natural language. Through adopting realistic synthetic w aveform generation, deterministic spectrogram captioning, and LLM-based instruction synthesis, we constructed a large RF instruction-tuning dataset span- ning multiple technologies and tasks. On our comprehen- siv e benchmarks, RF-GPT substantially outperformed general- purpose VLMs with no RF priors, and showed competitiv e performance with strong CNN and Transformer baselines, while additionally of fering natural-language answers, struc- tured outputs, and explanations from a single model. Our current RF grounding is mainly synthetic and limited to single- input spectrograms, motiv ating future work on real over - the-air data, multi-antenna and ISA C settings, and finer NR control-channel features. W e also aim to inte grate RF-GPT into spectrum-monitoring and AI-native network management prototypes, moving RFLMs from synthetic proof-of-concept tow ard practical RF intelligence engines for next-generation wireless networks. R E F E R E N C E S [1] A. Hurst, A. Lerer, A. P . Goucher , A. Perelman, A. Ramesh, A. Clark, A. Ostrow , A. W elihinda, A. Hayes, A. Radford et al. , “Gpt-4o system card, ” arXiv preprint , 2024. [2] G. Comanici et al. , “Gemini 2.5: Pushing the frontier with adv anced reasoning, multimodality , long context, and next generation agentic capabilities, ” arXiv preprint , 2025. [3] H. Liu et al. , “V isual instruction tuning, ” Advances in Neural Informa- tion Processing Systems , vol. 36, pp. 34 892–34 916, 2023. [4] S. Bai et al. , “Qwen2.5-VL T echnical Report, ” arXiv preprint arXiv:2502.13923 , 2025. [5] J. Zhu et al. , “InternVL3: Exploring Advanced Training and T est- T ime Recipes for Open-Source Multimodal Models, ” arXiv pr eprint arXiv:2504.10479 , 2025. [6] A. Radford, J. W . Kim, T . Xu, G. Brockman, C. McLeavey , and I. Sutskever , “Robust speech recognition via large-scale weak supervi- sion, ” in International conference on machine learning . PMLR, 2023, pp. 28 492–28 518. 16 [7] Y . Chu, J. Xu, Q. Y ang, H. W ei, X. W ei, Z. Guo, Y . Leng, Y . Lv , J. He, J. Lin et al. , “Qwen2-audio technical report, ” arXiv preprint arXiv:2407.10759 , 2024. [8] B. Zhang, C. Guo, G. Y ang, H. Y u, H. Zhang, H. Lei, J. Mai, J. Y an, K. Y ang, M. Y ang et al. , “Minimax-speech: Intrinsic zero- shot text-to-speech with a learnable speak er encoder , ” arXiv preprint arXiv:2505.07916 , 2025. [9] X. Tian, Q. Zheng, B. Li, D. Qiao, K. Y u, Z. W ei, B. Li, H. Jiang, X. Li, Y . Lin, and G. Gui, “ A survey on deep learning enabled automatic mod- ulation classification methods: Data representations, model structures, and regularization techniques, ” Signal Processing , vol. 242, p. 110444, 2026. [10] M. Cheraghinia, E. De Poorter, J. Fontaine, M. Debbah, and A. Shahid, “ A foundation model for wireless technology recognition and localiza- tion tasks, ” IEEE Open Journal of the Communications Society , vol. 6, pp. 9879–9896, 2025. [11] S. Alikhani, G. Charan, and A. Alkhateeb, “Large wireless model (lwm): A foundation model for wireless channels, ” arXiv preprint arXiv:2411.08872 , 2024. [12] T . Y ang, P . Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “W irelessgpt: A generati ve pre-trained multi-task learning framework for wireless communication, ” IEEE Network , 2025. [13] J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T . Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. W elbl, A. Clark et al. , “T raining compute-optimal large language models, ” in Pro- ceedings of the 36th International Conference on Neural Information Pr ocessing Systems , 2022, pp. 30 016–30 030. [14] A. Shahid et al. , “Large-scale AI in telecom: Charting the roadmap for innov ation, scalability , and enhanced digital experiences, ” arXiv preprint arXiv:2503.04184 , 2025. [15] Y . Zhao et al. , “A Comprehensive Survey of 6G Wireless Communica- tions, ” arXiv preprint , 2020. [16] M. Giordani et al. , “6G: The Intelligent Network of Everything – A Comprehensiv e V ision and Tutorial, ” arXiv preprint , 2024. [17] L. Liang et al. , “Large Language Models for W ireless Communications: From Adaptation to Autonomy, ” arXiv pr eprint arXiv:2507.21524 , 2025. [18] F . Zhu et al. , “W ireless large ai model: Shaping the ai-native future of 6g and beyond, ” arXiv preprint , 2025. [19] J. Shao et al. , “W irelessLLM: Empowering Large Language Models T owards W ireless Intelligence, ” arXiv preprint , 2024. [20] L. Bariah, Q. Zhao, H. Zou, Y . Tian, F . Bader , and M. Debbah, “Large Generative AI Models for T elecom: The Next Big Thing?” IEEE Communications Magazine , vol. 62, no. 11, pp. 84–90, 2024. [21] H. Zhou et al. , “Large Language Model (LLM) for T elecommunications: A Comprehensive Survey on Principles, Ke y T echniques, and Opportu- nities, ” IEEE Communications Surveys & T utorials , vol. 27, no. 3, pp. 1955–2005, 2025. [22] H. Zou, Q. Zhao, Y . Tian, L. Bariah, F . Bader , T . Lestable, and M. Debbah, “T elecomGPT : A Framework to Build T elecom-Specific Large Language Models, ” IEEE T ransactions on Machine Learning in Communications and Networking , vol. 3, pp. 948–975, 2025. [23] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser , and I. Polosukhin, “ Attention is all you need, ” in Advances in Neural Information Pr ocessing Systems (NeurIPS) , vol. 30, 2017. [24] A. Dosovitskiy , L. Beyer , A. Kolesniko v , D. W eissenborn, X. Zhai, T . Unterthiner , M. Dehghani, M. Minderer , G. Heigold, S. Gelly et al. , “ An image is worth 16x16 words: Transformers for image recognition at scale, ” in International Confer ence on Learning Repr esentations (ICLR) , 2021. [25] H. T ouvron, M. Cord, M. Douze, F . Massa, G. Synnaeve, and H. J ´ egou, “T raining data-efficient image transformers & distillation through at- tention, ” in International Conference on Machine Learning (ICML) . PMLR, 2021, pp. 10 347–10 357. [26] P . Flandrin, T ime-F requency/T ime-Scale Analysis . Academic Press, 1999. [27] K. Jaganathan, Y . C. Eldar, and B. Hassibi, “Stft phase retriev al: Unique- ness guarantees and recov ery algorithms, ” IEEE J ournal of selected topics in signal processing , vol. 10, no. 4, pp. 770–781, 2016. [28] E. J. Candes, T . Strohmer, and V . V oroninski, “Phaselift: Exact and stable signal recovery from magnitude measurements via conve x pro- gramming, ” Communications on Pur e and Applied Mathematics , vol. 66, no. 8, pp. 1241–1274, 2013. [29] J. Su, M. Ahmed, Y . Lu, S. Pan, W . Bo, and Y . Liu, “Roformer: En- hanced transformer with rotary position embedding, ” Neurocomputing , vol. 568, p. 127063, 2024. [30] B. Zhang and R. Sennrich, “Root mean square layer normalization, ” in Advances in Neural Information Processing Systems (NeurIPS) , vol. 32, 2019. [31] J. Ainslie, J. Lee-Thorp, M. de Jong, Y . Zemlyanskiy , W . Fedus, P . Sumers, G. Desjardins, A. Siddhant, Y . Ruiz, D. Luan et al. , “GQA: T raining generalized multi-query transformer models from multi-head checkpoints, ” arXiv preprint , 2023. [32] N. Shazeer, “Glu variants improve transformer, ” arXiv pr eprint arXiv:2002.05202 , 2020. [33] L. Boegner et al. , “Large scale radio frequency signal classification, ” arXiv preprint arXiv:2207.09918 , 2022. [34] H. Zou, B. W ang, Y . Tian, L. Bariah, C. Huang, S. Lasaulce, and M. Debbah, “Seeing radio: From zero rf priors to explainable modulation recognition with vision language models, ” arXiv preprint arXiv:2601.13157 , 2026. [35] D. P . Kingma and J. Ba, “ Adam: A method for stochastic optimization, ” in International Conference on Learning Representations (ICLR) , 2015. [36] S. Agarwal, L. Ahmad, J. Ai, S. Altman, A. Applebaum, E. Arbus, R. K. Arora, Y . Bai, B. Baker , H. Bao et al. , “gpt-oss-120b & gpt-oss-20b model card, ” arXiv pr eprint arXiv:2508.10925 , 2025. [37] M. T an and Q. V . Le, “Efficientnet: Rethinking model scaling for con volutional neural networks, ” in Proceedings of the 36th International Confer ence on Machine Learning , ser . ICML. PMLR, 2019, pp. 6105– 6114.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment