FireRed-Image-Edit-1.0 Technical Report
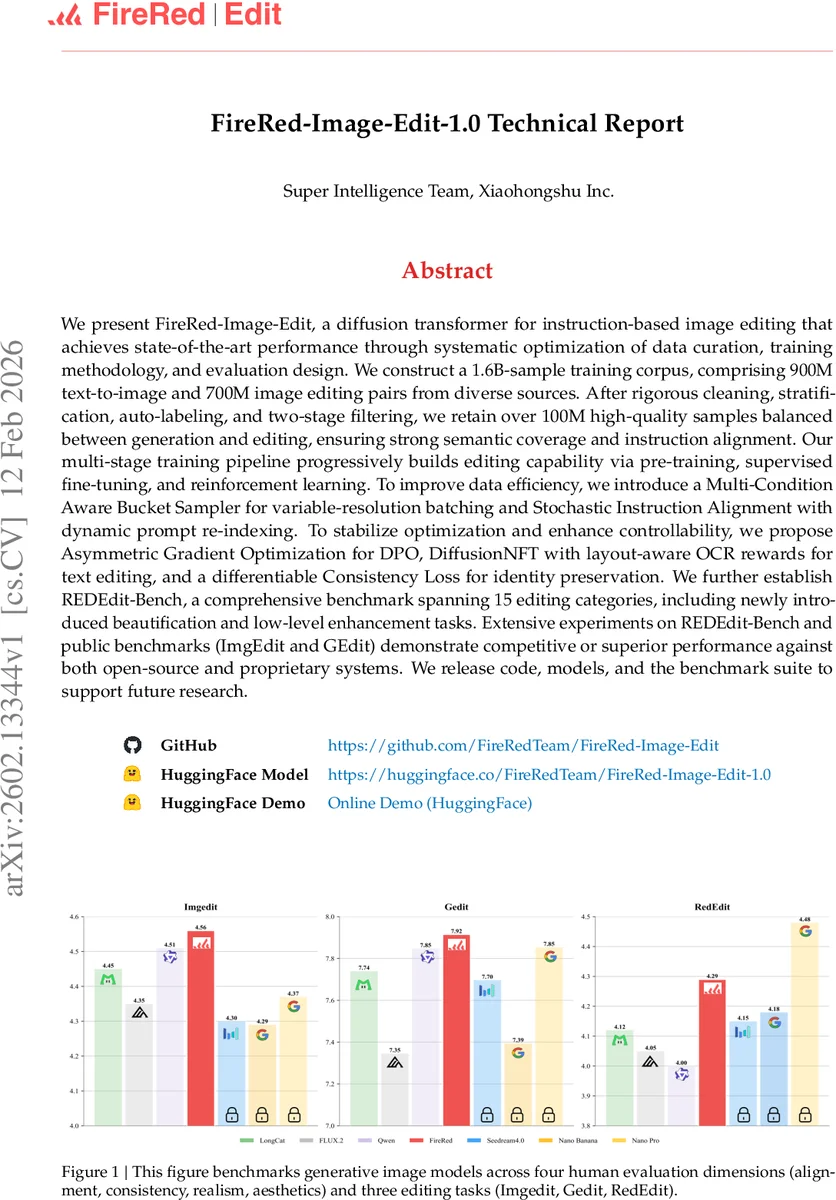
We present FireRed-Image-Edit, a diffusion transformer for instruction-based image editing that achieves state-of-the-art performance through systematic optimization of data curation, training methodology, and evaluation design. We construct a 1.6B-sample training corpus, comprising 900M text-to-image and 700M image editing pairs from diverse sources. After rigorous cleaning, stratification, auto-labeling, and two-stage filtering, we retain over 100M high-quality samples balanced between generation and editing, ensuring strong semantic coverage and instruction alignment. Our multi-stage training pipeline progressively builds editing capability via pre-training, supervised fine-tuning, and reinforcement learning. To improve data efficiency, we introduce a Multi-Condition Aware Bucket Sampler for variable-resolution batching and Stochastic Instruction Alignment with dynamic prompt re-indexing. To stabilize optimization and enhance controllability, we propose Asymmetric Gradient Optimization for DPO, DiffusionNFT with layout-aware OCR rewards for text editing, and a differentiable Consistency Loss for identity preservation. We further establish REDEdit-Bench, a comprehensive benchmark spanning 15 editing categories, including newly introduced beautification and low-level enhancement tasks. Extensive experiments on REDEdit-Bench and public benchmarks (ImgEdit and GEdit) demonstrate competitive or superior performance against both open-source and proprietary systems. We release code, models, and the benchmark suite to support future research.
💡 Research Summary
FireRed‑Image‑Edit 1.0 is a diffusion‑based transformer designed for instruction‑driven image editing. The authors begin by highlighting the current landscape: proprietary systems achieve high fidelity but lack transparency, while open‑source efforts chase ever larger model sizes, creating prohibitive computational costs. To break this trend, the paper proposes a holistic approach that optimizes data curation, model architecture, training efficiency, and evaluation methodology.
Data collection starts with 1.6 billion raw samples (900 M text‑to‑image pairs and 700 M image‑editing pairs) drawn from public datasets, web crawls, video frames, and a proprietary production engine. A five‑stage filtering pipeline—deduplication (coarse global, pair‑level, and fine‑grained multi‑metric), photometric & statistical filtering, artifact removal, perceptual quality & aesthetic assessment, and AIGC detection—reduces the corpus to over 100 million high‑quality examples. Crucially, the final dataset is balanced 1:1 between generation and editing data, ensuring that the model learns robust text semantics while also mastering diverse edit operations. The distribution spans natural scenes, people, design assets, and three major edit types: semantic, stylistic, and structural, covering 15 sub‑categories such as object addition/removal, color alteration, view change, and text modification.
The model architecture builds on a standard diffusion transformer but adds support for variable numbers of input images. To handle the resulting heterogeneity efficiently, the authors introduce a Multi‑Condition Aware Bucket Sampler that groups samples by resolution and image count, dramatically reducing padding overhead. Stochastic Instruction Alignment further randomizes the ordering of reference images and dynamically re‑indexes prompts during batch construction, forcing the model to decouple spatial ordering from content and improving generalization in multi‑reference scenarios. Training infrastructure includes pre‑extracted text embeddings, Fully Sharded Data Parallel (FSDP), gradient checkpointing, and mixed‑precision arithmetic, enabling large‑scale distributed training without excessive memory consumption.
Training proceeds in three stages. First, a large‑scale pre‑training phase mixes generation and editing data to establish a strong prior. Second, supervised fine‑tuning (SFT) on the curated 100 M samples refines instruction‑to‑edit mappings. Third, Reinforcement Learning with Human Feedback (RLHF) is applied via Direct Preference Optimization (DPO). The authors propose Asymmetric Gradient Optimization for DPO, which applies different learning rates to the policy and reference networks, stabilizing the notoriously volatile preference‑based updates. For text‑centric edits, DiffusionNFT incorporates a layout‑aware OCR reward that explicitly evaluates character placement and readability, mitigating the common problem of garbled text in diffusion outputs. A differentiable Consistency Loss enforces high‑level feature similarity between the original and edited images, preserving identity in portrait or facial edits.
To evaluate the system, the authors construct REDEdit‑Bench, a benchmark comprising 15 editing categories, including newly added beautification and low‑level enhancement tasks. The evaluation pipeline combines human judgments across four dimensions (alignment, consistency, realism, aesthetics) with automated metrics. Across REDEdit‑Bench, as well as public benchmarks ImgEdit and GEdit, FireRed‑Image‑Edit 1.0 consistently matches or exceeds the performance of both leading open‑source models (e.g., Qwen‑Image, FLUX.2) and commercial black‑box solutions, particularly excelling in text‑centric and complex structural edits. Notably, the model achieves these results while using fewer parameters and less compute than many competing systems, demonstrating the efficacy of the proposed data and training efficiencies.
In conclusion, the paper shows that meticulous data curation, adaptive batching, and targeted optimization techniques can deliver state‑of‑the‑art image editing without resorting to massive model scaling. All code, pretrained weights, and the REDEdit‑Bench suite are released publicly, providing a valuable resource for future research and practical deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment