Learning to Manipulate Anything: Revealing Data Scaling Laws in Bounding-Box Guided Policies
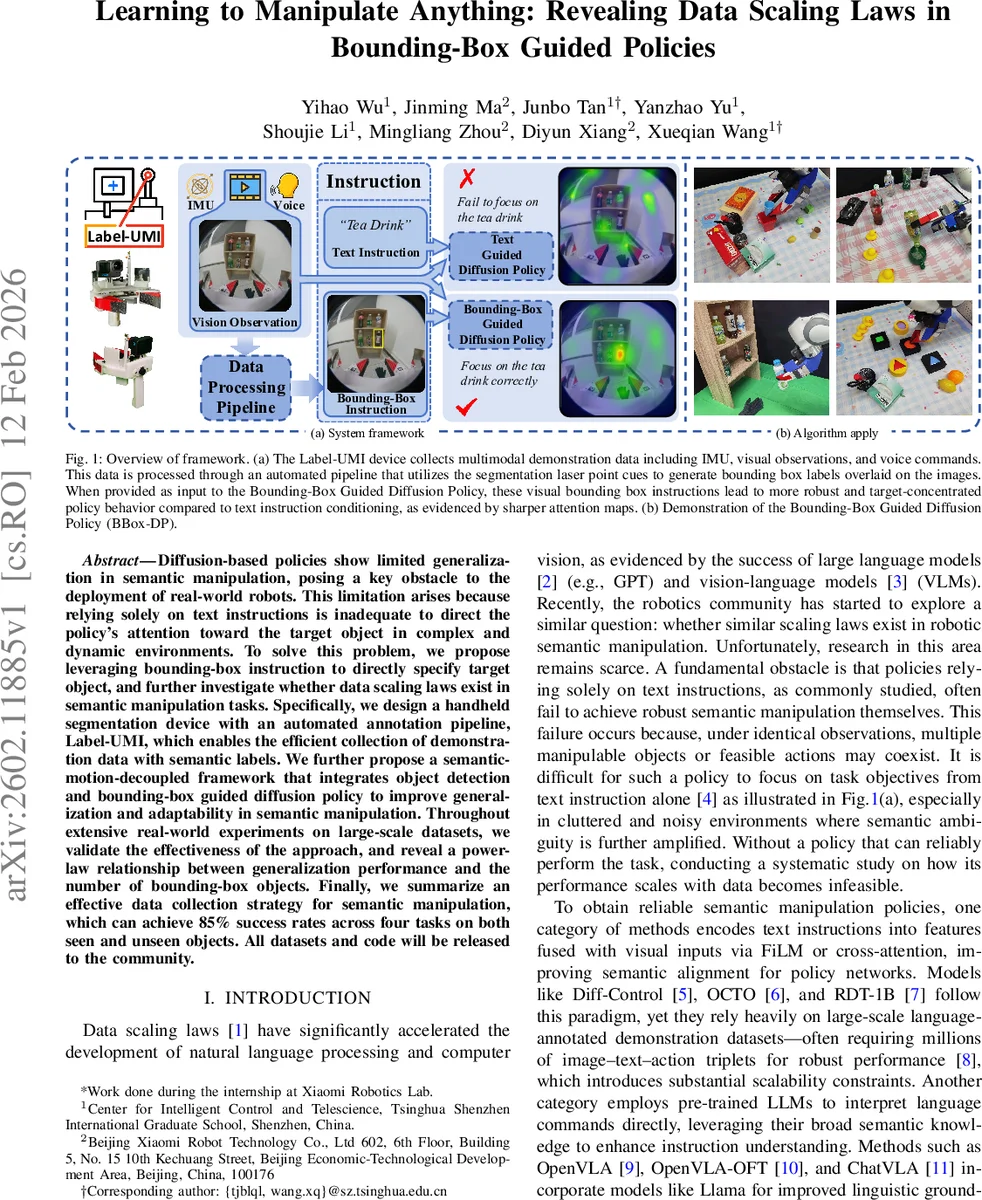
Diffusion-based policies show limited generalization in semantic manipulation, posing a key obstacle to the deployment of real-world robots. This limitation arises because relying solely on text instructions is inadequate to direct the policy’s attention toward the target object in complex and dynamic environments. To solve this problem, we propose leveraging bounding-box instruction to directly specify target object, and further investigate whether data scaling laws exist in semantic manipulation tasks. Specifically, we design a handheld segmentation device with an automated annotation pipeline, Label-UMI, which enables the efficient collection of demonstration data with semantic labels. We further propose a semantic-motion-decoupled framework that integrates object detection and bounding-box guided diffusion policy to improve generalization and adaptability in semantic manipulation. Throughout extensive real-world experiments on large-scale datasets, we validate the effectiveness of the approach, and reveal a power-law relationship between generalization performance and the number of bounding-box objects. Finally, we summarize an effective data collection strategy for semantic manipulation, which can achieve 85% success rates across four tasks on both seen and unseen objects. All datasets and code will be released to the community.
💡 Research Summary
The paper tackles a fundamental limitation of current semantic manipulation policies: when only text instructions are provided, the policy often fails to focus on the intended object, especially in cluttered, dynamic scenes. To overcome this, the authors introduce a two‑part solution. First, they design a handheld annotation device called Label‑UMI that combines a laser pointer, a joystick, a microphone, a camera, and an IMU. During data collection the user points the laser at the target object, speaks its name, and performs the manipulation while the device records multimodal data. After recording, the first video frame is processed by a YOLOv8s model fine‑tuned to detect the laser dot. The dot’s coordinates serve as a point prompt for the Segment‑Anything Model 2 (SAM2), which produces per‑frame object masks. Minimum bounding boxes are extracted from these masks, yielding high‑quality visual labels without any manual annotation. The pipeline is fully automated, dramatically reducing labeling time (≈10–12 boxes per minute) while preserving accuracy.
Second, the authors propose a Semantic‑Motion‑Decoupled architecture named Bounding‑Box Guided Diffusion Policy (BBox‑DP). An object detection module (e.g., a lightweight YOLO trained on the automatically generated boxes) converts the textual command into a visual instruction: a bounding‑box overlay on the current image. The policy itself is a diffusion‑based controller built on a U‑Net. It receives two streams of conditioning information: (1) visual features extracted separately from the raw image and from the image with the bounding‑box (both encoded by a Vision Transformer), and (2) proprioceptive robot state (joint positions, velocities, etc.). These features are fused and used to iteratively denoise an action sequence, ultimately producing a refined trajectory that manipulates the object indicated by the box. By delegating semantic grounding to the detection module, the diffusion policy only needs to learn “follow the box,” which simplifies learning and improves robustness. The modular design also allows swapping in more powerful detectors (e.g., DINOv2) without retraining the policy.
The authors evaluate BBox‑DP on four real‑world tasks—rubbish disposal, drink fetching, button pressing, and water pouring—using datasets of varying size (50, 100, 200, 300 annotated objects). They observe a clear power‑law relationship between the number of distinct bounding‑box objects (N) and the success rate (S): S ≈ k·N^α with α ≈ 0.45. This scaling law indicates that performance improves predictably as more diverse object annotations are added, mirroring scaling phenomena seen in large‑language and vision models. Compared to state‑of‑the‑art text‑conditioned diffusion policies (e.g., Diff‑Control, OCTO), BBox‑DP achieves 20–30 % higher success rates across all tasks, and it maintains about 85 % success on unseen objects, confirming strong generalization.
Beyond the empirical findings, the paper contributes a practical data‑collection strategy: using Label‑UMI and the automated pipeline, researchers can rapidly amass large, richly annotated manipulation datasets with minimal human effort. The authors plan to release all code, models, and datasets to the community, facilitating further research on scalable, vision‑grounded robot learning. In summary, the work demonstrates that bounding‑box visual instructions, coupled with diffusion‑based control, provide a simple yet powerful means to achieve robust, generalizable semantic manipulation, and it quantitatively uncovers how performance scales with data diversity.
Comments & Academic Discussion
Loading comments...
Leave a Comment