Credit Where It is Due: Cross-Modality Connectivity Drives Precise Reinforcement Learning for MLLM Reasoning
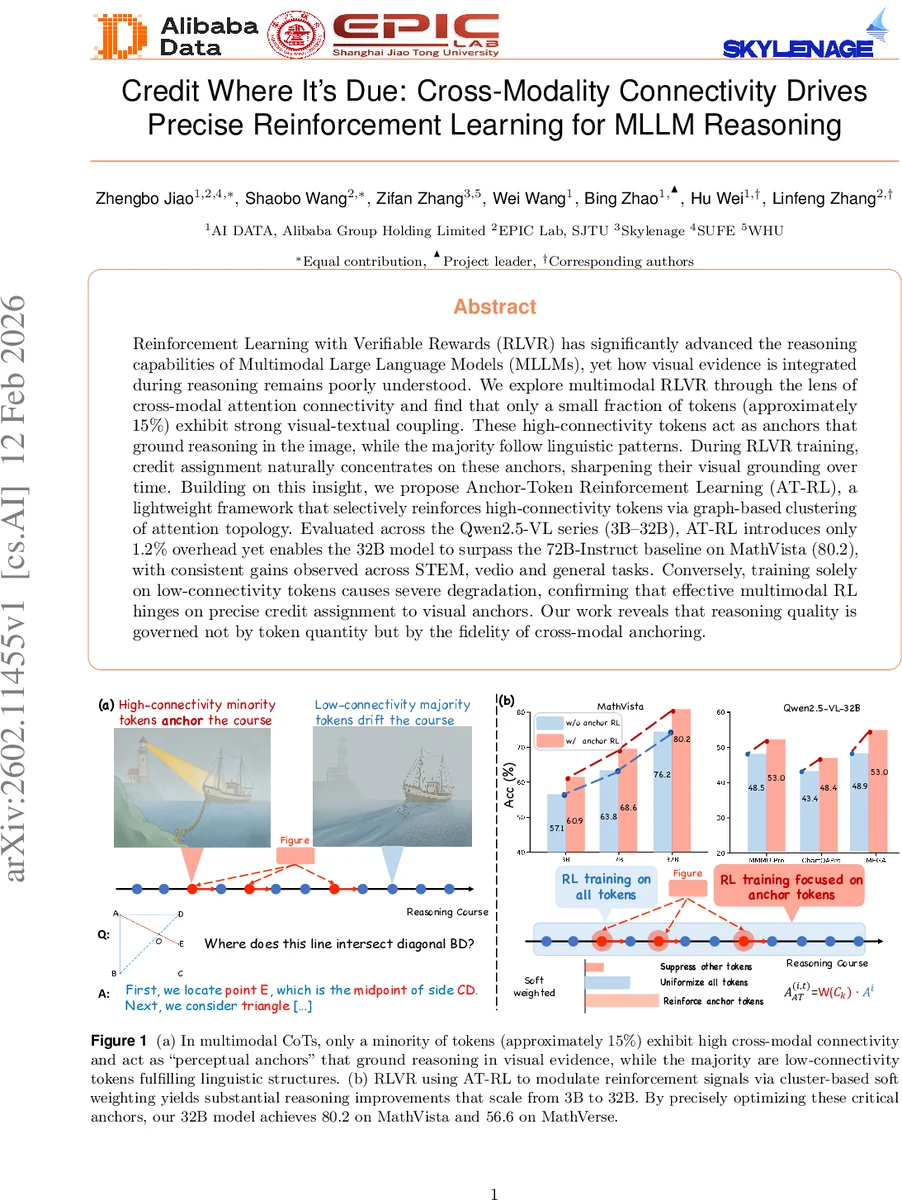
Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced the reasoning capabilities of Multimodal Large Language Models (MLLMs), yet how visual evidence is integrated during reasoning remains poorly understood. We explore multimodal RLVR through the lens of cross-modal attention connectivity and find that only a small fraction of tokens (approximately 15%) exhibit strong visual-textual coupling. These high-connectivity tokens act as anchors that ground reasoning in the image, while the majority follow linguistic patterns. During RLVR training, credit assignment naturally concentrates on these anchors, sharpening their visual grounding over time. Building on this insight, we propose Anchor-Token Reinforcement Learning (AT-RL), a lightweight framework that selectively reinforces high-connectivity tokens via graph-based clustering of attention topology. Evaluated across the series (3B-32B), AT-RL introduces only 1.2% overhead yet enables the 32B model to surpass the 72B-Instruct baseline on MathVista (80.2), with consistent gains observed across STEM, video and general tasks. Conversely, training solely on low-connectivity tokens causes severe degradation, confirming that effective multimodal RL hinges on precise credit assignment to visual anchors. Our work reveals that reasoning quality is governed not by token quantity but by the fidelity of cross-modal anchoring.
💡 Research Summary
The paper “Credit Where It is Due: Cross‑Modality Connectivity Drives Precise Reinforcement Learning for MLLM Reasoning” investigates how multimodal large language models (MLLMs) integrate visual evidence during chain‑of‑thought (CoT) reasoning and proposes a novel reinforcement‑learning framework that focuses credit on the most visually grounded tokens.
First, the authors conduct a systematic analysis of cross‑modal attention in the Qwen2.5‑VL series (3B‑32B parameters). By aggregating attention weights across layers and heads and applying a bias‑correction function, they compute a “connectivity” score for each textual token, measuring its reliance on visual patches. The distribution is highly skewed: only about 15 % of tokens exhibit strong visual‑textual coupling. These high‑connectivity tokens, termed “perceptual anchors,” serve as the pivotal points where the model actually looks at the image to solve a sub‑problem, while the remaining low‑connectivity tokens mainly maintain linguistic coherence.
Existing Reinforcement Learning with Verifiable Rewards (RLVR) methods such as GRPO, DAPO, and SAPO treat all tokens uniformly when propagating the advantage signal, effectively diluting the learning signal that should be directed toward the visual anchors. The paper hypothesizes that precise credit assignment to these anchors will improve multimodal reasoning efficiency.
To test this hypothesis, the authors introduce Anchor‑Token Reinforcement Learning (AT‑RL). AT‑RL proceeds in three stages: (1) locate perceptual anchors by thresholding the calibrated connectivity scores; (2) construct a token‑level graph from the aggregated attention matrix and partition it into semantically coherent clusters using graph‑partitioning algorithms (e.g., Louvain); (3) compute a cluster‑wise density metric and use it to softly re‑scale the sequence‑level advantage into token‑level weights. Unlike binary masking approaches (e.g., VPPO), the soft weighting preserves gradient flow for non‑anchor tokens, maintaining overall language fluency while amplifying learning for the visual anchors.
Extensive experiments are performed on a wide range of benchmarks: MathVista, MathVerse, STEM‑VQA, VideoMMMU, and several general VQA datasets. Across all model sizes, AT‑RL yields consistent gains. Notably, the 32‑billion‑parameter Qwen2.5‑VL model trained with AT‑RL achieves 80.2 on MathVista, surpassing the 72‑billion‑parameter Qwen2.5‑VL‑Instruct baseline (≈78.5) while incurring only a 1.2 % computational overhead per training iteration. Ablation studies show that training exclusively on low‑connectivity tokens or applying random/reversed weighting leads to severe performance degradation, confirming the central role of anchor‑focused credit assignment.
The paper also discusses limitations: the connectivity threshold and clustering hyper‑parameters are fixed across tasks, which may not be optimal for every domain; reliance solely on attention‑based connectivity may miss other forms of vision‑language interaction such as multi‑head complementarity. Future work is suggested to explore dynamic thresholding, integration of multimodal positional encodings, and unsupervised visual‑language alignment metrics to further refine AT‑RL.
In summary, the work makes three key contributions: (1) discovery of a structural dichotomy in multimodal CoT reasoning—high‑connectivity perceptual anchors versus low‑connectivity linguistic tokens; (2) the AT‑RL framework that leverages graph‑based clustering to deliver soft, token‑level advantage weighting, thereby aligning reinforcement signals with visual grounding; and (3) empirical evidence that precise, anchor‑focused reinforcement dramatically improves reasoning performance across scales and tasks with negligible extra cost. This study opens a new direction for multimodal RL research, emphasizing that reasoning quality is governed not by the quantity of tokens but by the fidelity of cross‑modal anchoring.
Comments & Academic Discussion
Loading comments...
Leave a Comment