Controlled Self-Evolution for Algorithmic Code Optimization
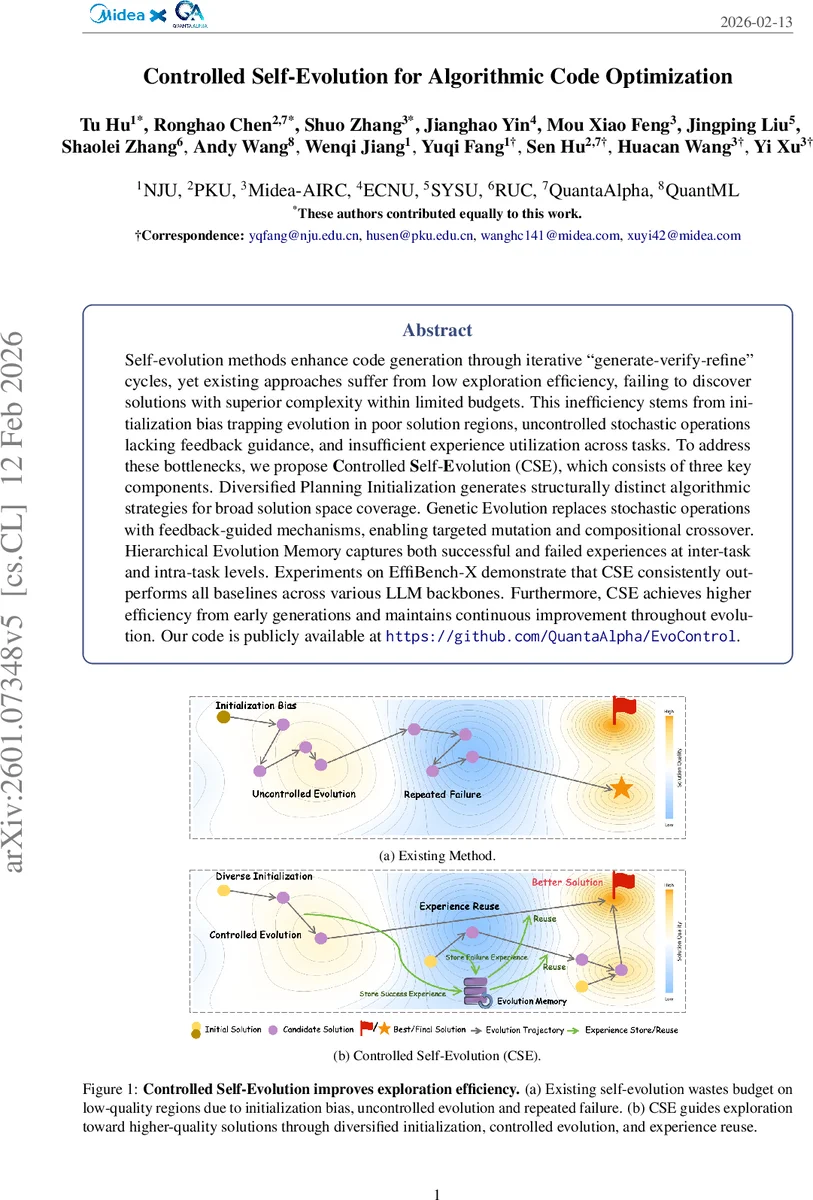
Self-evolution methods enhance code generation through iterative “generate-verify-refine” cycles, yet existing approaches suffer from low exploration efficiency, failing to discover solutions with superior complexity within limited budgets. This inefficiency stems from initialization bias trapping evolution in poor solution regions, uncontrolled stochastic operations lacking feedback guidance, and insufficient experience utilization across tasks. To address these bottlenecks, we propose Controlled Self-Evolution (CSE), which consists of three key components. Diversified Planning Initialization generates structurally distinct algorithmic strategies for broad solution space coverage. Genetic Evolution replaces stochastic operations with feedback-guided mechanisms, enabling targeted mutation and compositional crossover. Hierarchical Evolution Memory captures both successful and failed experiences at inter-task and intra-task levels. Experiments on EffiBench-X demonstrate that CSE consistently outperforms all baselines across various LLM backbones. Furthermore, CSE achieves higher efficiency from early generations and maintains continuous improvement throughout evolution. Our code is publicly available at https://github.com/QuantaAlpha/EvoControl.
💡 Research Summary
The paper tackles a fundamental limitation of large language model (LLM)‑driven code generation: while modern models can often produce functionally correct programs, the generated solutions are frequently far from optimal in terms of time and space complexity. Existing “self‑evolution” approaches—iterative generate‑verify‑refine loops—attempt to improve code quality but suffer from three intertwined inefficiencies. First, they start from a single or very few initial solutions, which may lie in low‑quality regions of the search space, causing the evolutionary process to become trapped in local optima. Second, mutation and crossover are applied in an uncontrolled, stochastic manner, without leveraging the rich feedback (test failures, performance bottlenecks) that the execution environment provides. Third, successful patterns and failures are not systematically recorded or reused across tasks, leading to repeated mistakes and a lack of transferable knowledge.
To overcome these bottlenecks, the authors propose Controlled Self‑Evolution (CSE), a three‑component framework that injects explicit control and experience reuse into the evolutionary loop.
-
Diversified Planning Initialization – Instead of a monolithic seed, CSE first asks the LLM to produce a set of high‑level algorithmic sketches that are structurally distinct (e.g., greedy, dynamic programming, bit‑manipulation). Each sketch is then instantiated into a concrete implementation, forming a diverse initial population. This multi‑modal seeding dramatically reduces initialization bias and enables parallel exploration of several promising regions.
-
Genetic Evolution – CSE replaces blind random operators with feedback‑guided mechanisms. The code of each candidate is decomposed into independent functional components (I/O handling, core algorithm, edge‑case logic). A probabilistic parent‑selection scheme weighted by normalized reward keeps high‑scoring individuals while still allowing lower‑scoring ones to contribute useful fragments. Two guided operators are introduced:
- Controlled Mutation – The model identifies the component responsible for the largest reward drop (using test failures or performance metrics) and regenerates only that part, leaving the rest untouched. This “surgical” mutation preserves useful context and improves mutation efficiency.
- Compositional Crossover – Rather than naïve textual concatenation, CSE extracts complementary strengths from two parents (e.g., one’s low‑time‑complexity loop and another’s robust edge‑case handling) and recombines them at the component level. This mirrors how human programmers merge ideas from different solutions.
-
Hierarchical Evolution Memory – Experience is captured at two levels.
- Local Memory records, for each step, whether the reward increased (success insight) or decreased (failure lesson). These distilled patterns are compressed and injected into the next prompt, guiding the model to repeat what worked and avoid past mistakes.
- Global Memory aggregates cross‑task knowledge. For each task, the top‑K positive and negative experiences, together with the best solution, are stored in a vector database. When a new task is being evolved, the system generates targeted queries (based on current errors or bottlenecks) and retrieves the most relevant experiences, which are then supplied as additional context. This enables transfer learning across tasks without manual engineering.
The authors evaluate CSE on EffiBench‑X, a benchmark specifically designed to measure algorithmic efficiency, using several state‑of‑the‑art LLM backbones (e.g., GPT‑4o, DeepSeek‑Coder). Compared with strong baselines such as AlphaEvolve, SE‑Agent, and AfterBurner, CSE consistently achieves higher composite scores that combine correctness and efficiency. Notably, CSE shows a steep performance gain within the first three to five generations, indicating that the diversified initialization and feedback‑driven operators dramatically improve early‑stage exploration. Final solutions often match or surpass human‑written canonical implementations in both time and space complexity, while using comparable computational budgets.
The paper also discusses limitations. The quality of the initial sketches depends on the underlying LLM’s prompting ability; weaker models may produce insufficient diversity. The hierarchical memory, especially the global component, can grow large, raising concerns about storage and retrieval latency. Finally, the current reward function focuses on correctness and efficiency, leaving other desirable software qualities (readability, maintainability) unaddressed.
Future work is suggested in three directions: (1) automated sketch generation that is less sensitive to prompt engineering, (2) more scalable memory compression and indexing techniques, and (3) integration of multi‑objective optimization (e.g., combining efficiency with code quality metrics) possibly via reinforcement learning.
In summary, Controlled Self‑Evolution introduces a principled, controllable, and experience‑rich evolutionary loop for LLM‑based code generation. By diversifying the starting population, guiding mutations and crossovers with concrete feedback, and reusing both intra‑task and inter‑task knowledge, CSE markedly improves exploration efficiency and yields algorithmically superior code under realistic resource constraints. This work paves the way for more practical, high‑performance automated programming systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment