Model-based controller assisted domain randomization for transient vibration suppression of nonlinear powertrain system with parametric uncertainty
Complex mechanical systems such as vehicle powertrains are inherently subject to multiple nonlinearities and uncertainties arising from parametric variations. Modeling errors are therefore unavoidable, making the transfer of control systems from simu…
Authors: Heisei Yonezawa, Ansei Yonezawa, Itsuro Kajiwara
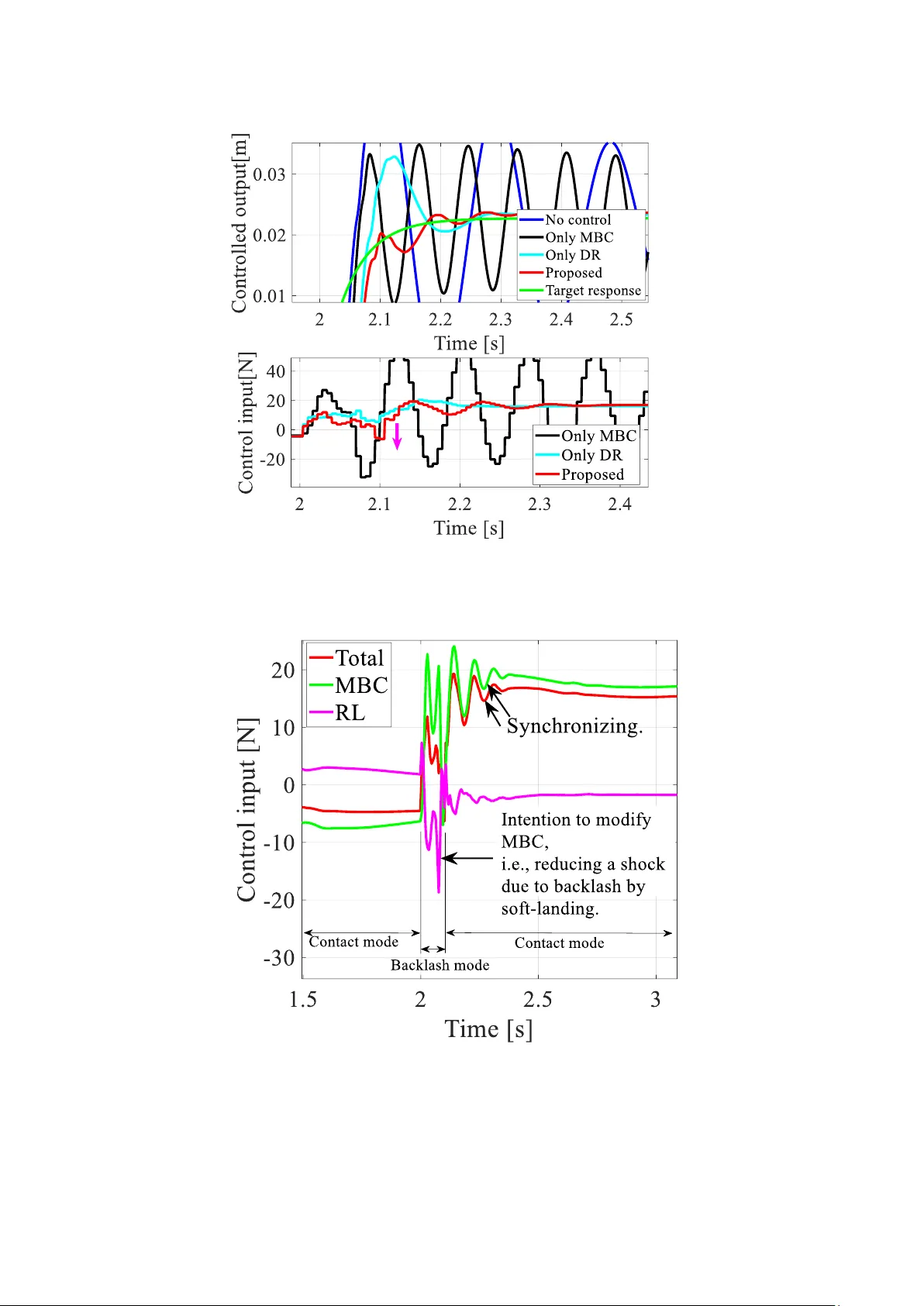
Model-based controlle r assisted domain randomization for transient vibration suppression of nonlinear powertr ain system with parametric uncertainty Heisei Y onezawa #1 , Ansei Y onezawa #2 , Itsuro K ajiwara #3 #1(Correspond ing author) Division of Mech anical and Aerospace Engin eering, Hokkaid o Universi ty N13, W8, Kita-ku, S apporo, H okkaido 060-8628, Jap an Phone +81-80- 4039-9406 E-mail: yonezawah@ eng.hokudai.ac. jp #2 Department of Mechanical Engineering, Kyu shu Univ ersity 744 Motooka, Nis hi-ku, Fukuoka 81 9-0395, Japan Phone +81- 90- 2893-3160 E-mail: ayonezawa @mech.kyushu-u.ac .jp #3 Division of Mech anical and Aerospace Engin eering, Hokkaid o Universi ty N13, W8, Kita-ku, S apporo, Hokkaid o 060-8628, Jap an Phone +81-11- 706-6390, Fax. +81-11- 706-6390 E-mail: ikajiwara @eng.hok udai.ac.jp Abstract Complex mechanical systems such as vehicle powertrains are inherently subject to multiple nonlinearities and unc ertai nties ar ising from pa rametric variations. Mod eling errors are there fore unavoidable, making the transfer of control systems from simul ation to real-world systems a critical challenge. T raditional robu st controls have limitations in handling certain types of nonlinearities and uncertainties, requiring a more practical approach capable of comprehensive ly compensating for these various constraints. This study proposes a new robust control approach using the framework of deep reinforcement learn ing (DRL). The key strategy lies in t he synergy among doma in randomization-bas ed DRL , long short-ter m memory (LSTM)-based actor and critic netwo rks, and model- based control (MBC). The problem setup is modeled via the la tent Markov dec ision proce ss (LM DP), a se t of vanilla MDPs, for a con trolled system sub ject to unc ertainties and n onlinearities. In LMDP , the dynamics of an environment simulator is randomized during training to improve the robustness of the control system to real test ing enviro nments. The randomization increases training dif ficulties as well as conservativene ss of the res ultant control system; therefore, progress is assisted by conc urrent us e of a model-based controller based on a physics-based system model. Compared to tradi tional DRL -based controls, the proposed approach is smarter in t hat we can ac hieve a high level of generalization ability with a more co mpact neural netwo r k architecture and a smaller amount of train ing data . The controller is verified via p ractical application to active damping for a complex powertra in system with nonlinearities and para metric variations. Comparat ive tests demonstrate the high robustness of the proposed approach. Keywords : Active vibra tion control, Dom ain random ization, Robust co ntrol, Model-based contro l, Powertrain, Deep re inforce ment learning 1. Introduction In recent years, the performance requirements for industrial m echanical systems, such as automotive powertrain systems [1][2] and robotic control [3][4], have become increasingly sophisticated, leading to a continuous increase in system complexity. Mechanical systems are inherently subject to nonlinearities [5], communication delays, and uncertainties arising from parametric variations [6]. Therefore, control system design must rigorously account for these f actors to ensure stability and performance. Since the formalization of modern control theory by Rudolf Kalman [7], the superior performance of model-based control system s, which rely on system models ( e.g., linear state-space equations), has been widely recognized. Inspi red by this paradigm, control system design has traditionally focused on achieving high-precisio n modeling of the controlled system by leveraging governing equations and system i dentification techniques. However, as industrial systems continue to grow in complexity and exhibit i ncreasing nonlinearities, naïve model-based co ntrol approaches are reaching thei r fund amenta l limitations. Modeling and calibration errors are inherently unavoidable, making the transfer of control strategies from si mulation to real-world systems a critical challenge — commonly referred to as the s im - to -real gap problem [8]. Mitigating performance degradation in t he presence of system variations an d nonlinearities remains a top-priority chal lenge in both industry and academia and continues t o be an unresolved issue. However, traditional robust controls such as control [9][10] ha ve inherent limitations in handling certain types of nonlinearities and uncertainties. Industrial systems, such as automotive powertrains, are typically affected by multiple nonlinear characteristics and uncertainties simultaneously. Therefore, more practical control systems are needed capable of comprehensively compensating for these various con straints. In recent years, the significant advancement in computational power and theoretic al breakthroughs in machine learning h ave brought i ncreasing attent ion to the in tegration of artificial inte lligence (AI) into control system design [11]. Among thes e advancements, reinforcemen t learning (RL) has achieved remarkable succes s in solving com plex, nonlinear , large-scale, and high-dime nsional cont rol problems [12][13]. In RL, an agent — the decision-mak ing entity — learns to perform complex tasks through trial and er ror by interac ting with the environment. T he key advan tage of RL lies in its ability to autonomously collect training data and learn without requiring an explicit transition m odel of the environment ’ s dyna mics [14][15]. Notably, deep reinfor cement learning (DRL) [16][17], which leverages deep learning techniques, has gained prom inence in recen t years. A major breakthrough i n DRL was the successful approximat ion o f value function s using deep, nonlinear neural networks, sign ificantly enhancing t he scalability and generalization capability of RL-based control systems . The proposition of DRL has led to significant advancements, particularly in the extension to contin uous action spaces. Notable examples include Deep Deterministic Policy Gradient (DDPG) [18][19] and its improved variant, Twin Delayed Deep Deterministic Policy Grad ient (TD3) [20 ], bo t h o f which exemplify the class of policy gradient optimization methods. Mo re recently, Proximal Policy Optimization ( PPO) [21] has demonstr ated remarkable learning capabilities, underp inning the success of the large language model ChatGPT , which has had a profound global impact [22][23]. DRL also has shown the powerful capabilities for controlling complex mechanical systems such as a rot ary flexible link manipulator [24], rotating machinery [25], a m agnetorheologic al elastomer vibration absorb er [26], and v ibration control oriented to flexible solar panels of s pacecraft and satellites [27]. The applica tion to m ulti-story shear building structures show ed t hat DRL outperform s tradition al model-based control in partially observed settings [28]. Anothe r pr evious study demonstrated that integration of DDPG wit h an i terative gradient-based state feedback control algor ithm can accelerate the learning process [29]. For driving a robot gearshift manipulator, a combined approach of active disturbanc e rejection control and DDPG was proposed [30]. RL inherently relies on trial-and-error exploration, wh ere training data is sampled through stochasti c exploratory actions, often resulting in extreme or misguid ed policies. Conseque ntly, training an RL agent direct ly in a r eal-world environment poses significant safety risks [8]. Moreover, collecting the vast amount of experimenta l data required to acquire an effective policy entails substantial computational costs and time [31]. To alleviate these challenges, a common approach is to train RL agents in simulated environments, where safety concerns are el iminated, and an unlimited amount of training data can be generated [8] . However, the s im - to - real gap is a well-recognized issue not only in control theory but also in RL . Due to modeling and c alibration errors, an agent trained to pe rform a task successfully in simula tion may fail to exhibit the same level of perfor mance when deployed in the rea l world [8]. It should be remarked that p revious naïve applications of RL to active vibration controls overlook the issue o f sim- to -real gap s. A practical appro ach that has been increasingly adopted in the field of robotics to address the s im - to - real gap problem is domain randomization (DR) [ 8,32,33]. While this concept is simple and intuitive, it has proven to be highly effective. To enhance the generali zation ability of an RL agent to real-world environments, it is prefer able to train the agen t under a diverse set of various environments rather than under a single fixed environment. In spired by this i nsight, t he dynamics of an environment simulator are randomly sampled at the beginn ing of each training episode in DR. By optimizing the value function across a set of different Markov decision processes (MDPs), the agent can improve generalization and robustness to real-world conditions. One study in particular provided a t heoretical analysis on why domain randomization can succeed [33]. From the viewpoint of the successful applications, there are many examples including deformable object manipulation [34], object pushing t asks with 7- DOF robotic arm control [8], locomotion control of bipedal r obots [35], imitation learning for real -world animals with agile locomotion skills [36], and humanoid robots [ 37][38]. Other studies have explore d further application s in drone racing [39] and path-fo llowing con trol for an autonomous surface vehic le [31] . However, there remain some technical shortcomi ngs and gaps in previous studies on domain randomization- based techniques fro m the viewpoint of practical app lications as follows: 1. While domain r andomization has been i ncreasingly utilized in the field o f robotics , its app lication to a broader range of mechanical systems — such as automo tive systems — for positioning and vibration control re mains largely une xplored. 2. Since a domain randomized environment is constantly changing due to random sampling, the difficulty of training is i ncreased, hindering the succe ssful l earning progress [34]. Additionally, the trained po licy is prone to be too con servative [40 – 4 2]. Most previou s studies on d omain r andomization do not address the se issues. If an enormous amount o f training data (episodes) and a large scale of a nonlinear f unction approximator are available, we may acquire a nearly optimal policy with domain randomization. Nevertheless, such a complex setting not only enlarges the effort, cost, and training time in developmen t, but also rais es the risk of overfitting in deep neural networ ks. This study f ocuses on a new controller design to addr ess th ese pro blems. It may be ques tioned wh ether a control system that relies on a large amount of training data and a large nonlinear function approximator to accomplish its target task can really be called smart. In other words, the central question posed in our study is: What defines a more intelligent controlle r ? This study contends that a smarter control system is one that achieves the same level of learning performance (i.e., generalizat ion ability ) with a more compact neural ne twork architec ture and a smaller amo unt of trainin g data . Inspired by the above definition, this study proposes an improvement metho d to overcome the shortcomings of vanilla domain r andomization-base d control systems. The proposed method is based on the idea that th e introduc tion of a model-based con troller (MBC) der ived f rom a nominal model can assist the progress of domain randomization training. The approach is outlined in Fig. 1 . The effectiveness of integrating MBC and RL has also been analyzed in recent studies [43], where an advanced model-data hybrid driven control scheme wa s proposed to address uncertain hydr aulic Euler- Lagrange systems. Our present study leverage s t he similar idea of s uch inte gration to enhance the properties of domain randomization. We formulate modeling via t he latent Markov decision process (LMDP) f or a controlled system subject to uncertainties and nonlinearities. In LMDP, a robust policy is realized by randomizing the dynamics of an environment simulator during training, e xtending the generalization ability to real testing environm ents. In the proposed approach, a DRL agent trained by domain random ization co mpensates for modeling er rors ( e.g., nonlinear ity and p arametric unc ertainty) while a model-based controller undertakes the base for t he control action from scratch, making t he training process e asier. In summary, the con tributio ns and technical novelties o f this study ar e as follows: 1. Integration of MBC with domain rando mization in a DRL framework: The essential novelty of this study li es i n strengthening domain randomization through the assistance of an MBC d es igned from a nom inal syste m mode l. Our nove l fra mework realizes a strong synergy between physical model -based control and data-driven learning, which overcomes many challenges of controlling mechanic al systems. By providing baseline control performance from the beginning, MBC significan tly improves training efficiency, reduces unnecessary exploration, and mitigates the conse rvativeness of the r esulting pol icy. Th is synergy allows the RL agent to achiev e robust generalization with fewer training data and smaller network s tructures. 2. Memory-augmented pol icy representat ion: We employ LSTM -based actor and critic network s, which store past experiences in hidden states and thereby enable the policy to i nfer the dynamics of r andomly varied environments . This enhances the adaptability of the control sys tem under uncer tainties. 3. Formulation as LMDP: From a theoretica l perspective, we model the control problem with uncertainties and nonlinearities as an LMDP. We demonstrate that even when the learning environment is extended to include MBC, the Markov property — the theoretical foundation of RL — remains satisfied. Th i s prov ides a more genera l theo retical basis for app lying the pro posed al gorithm to a broader class of no nlinear systems and stat e-space-represented model-based con trollers. 4. Application to nonlinear powertrain vibra tion cont rol: The proposed approach is validated through numerical simulations f or active damping of a vehicle powertrain subject to strong nonl inearities and parame tric v ariations. To the bes t o f our knowledge, this is the first application of domain randomization to c omplex acti ve vibration control. Compar ative valid ations confirm the superior robustness of the proposed method ove r existing approaches . The r emainder of this paper is organ ized as follows. Section 2 describes the problem formulation . Section 3 outlines the standard reinforcement learning setup. Section 4 details t he proposed approach, i.e., MBC assisted domain randomization training (MBCA-D RT) strategy. The proposed scheme is extended to the continuou s action RL algorithm: DDP G. Section 5 applies the improved robust DDPG to active vibration c ontrol o f an unce rtain pow ertrain s ystem. Th e robustness of t he proposed approach is verified via nume rical examp les using the powe rtrain mod el. Finally, Section 6 concludes th e paper. Fig. 1 Outline of M BC assisted domain randomizat ion. 2. Problem formulation : no nlinear adaptive optimal contr ol problem Consider a discrete-t ime (DT), nonlin ear dynamical sy stem defined by (1) (2) where , , and are the state, the control i nput, and the disturbance at discrete time , respectively . The controlled output is denoted by . Here , is t he uncertain nonlinear function that represents the transition dynami cs of the system. Also, is the uncertain func tion that defines the sys tem output. The symbo l corresponds to a set of system paramete rs that may be subj ect to uncerta inties such as parameters variations and nonlinearities. The dynamics of the simulation is parametrized by duri ng domain randomization training. T he goal o f this co ntrol prob lem is to de termine the control input at each time step so t hat the tracking error converges t o zero: , where . Here, represent s a reference va lue. No te that and are independe nt fr om past states and co ntrol inputs ( i.e., they are exogen ous disturbances with known or random distributions). Associated with this system, the adaptive optima l control problem with a finite time-horizon i s defined based on the immediate cost Observed states, Reward Model-based controller RL agent-based controller Plant dynamics with Plant dynamics with Plant dynamics with Plant dynamics with A set of different MDPs Facilitate learning Randomly selected dynamics Randomize dynamics parameter distribution Sample Reference value Improve robustness function : subject to (3) where and as . In this paper, the quad ratic cost function is used: (4) where and are positive semi-definite and positive definite symmetric matrices, respectively. It is not possible to direct ly apply the conventional model-based linear controller to the optimization problem ( 3) because the system dynamics (1) and (2) ar e unknown due to the model uncertainty and nonlinearity. Neverthele ss, in most industrial systems, partially known system dynamics can be leveraged to derive the line arized no minal model, which shoul d be u seful to boost the efficiency of R L agent training. The following assump tions are introd uced into the opt imization p roblem. Assumption 1 : The linearized approx imate model (i. e., nominal mode l) of the nonlinear system in Eq s. (1 ) and (2 ) is known: (5) (6) where , , , and . These system matrices can be obtained from various approaches su ch as first principle-based modeling, syste m identification, and data-driv en approaches. Assumption 2 : For the above linear approximate m odel, we ca n design a mode l-based linear c ontroller in the form of the following discrete state-space representation, generating the model -based contro l input . This is an approx imate solution fo r the optimiza tion problem (3). (7) (8) where , , , and . Here, is an interna l state vector of the MBC. It should be noted that only the mode l-based fixed controller itsel f f ails t o ap propria tely control the real system (1) and (2) due to t he modeling error such as parametric uncertainty and non l inearity negle cted in the approximated system (5) and ( 6). Such nonlinearity negatively affects the control system ’ s performance, causing serious degradation and instability . RL techniques are capable of dealing with system nonlinearit ies by training a control policy such that provides approxim ately optimal so lutions to the problem ( 3 ). In most RL algorithms, Eqs. (1)-(4) can be equivalently formulated as a DT Markov decision process (MDP) [14][44]; however, the sim- to - real gap is not e xplicitly add ressed. 3. Deep reinfor cement learning 3.1. Markov decis ion pro cess This chap ter follows the RL framework based on descriptions in literatures [18][19]. Following the convention adopted i n most RL l iteratures, the time step is denoted by , which correspond s t o in Chapter 2. Fig. 2 Setup of st andard reinforcem ent learning. W e consider a standard reinforcement learning se tup i n which an agent ac ts in a stochastic environment by sequential ly selecting actions over a sequence of discrete time steps , in order to maximize a cumulative long-term reward, as shown in Fig. 2. W e model the problem as a n MD P which is composed : a state space , an action space , an initial state distribution with dens ity , a stationary transition dyna mics di stribution with condition al den sity . The Mark ov property is satisfied, meaning , for any trajectory in state-action space. At each time step , t he agent receives a state , takes an action and receives a scalar-valued reward . The actions are real-valued . A reward RL agent Environment Reward function State Action Reward Update law Policy Action State Reward RL agent (a) (b) function is a m etric that r epresents the immedia te desirabili ty o f a gi ven state and an agent’ s action of the en vironment. T o evaluate the quality of an agent’ s actions, i t is provided as a scalar value to the agent from the environment at every step. A policy is used to select actions in the MDP . In general, the policy is stochastic and defined by mapping from states to a probability distribution over the actions , where is a set of probability measures on and is a paramet er vector of dimensions. is the con ditional proba bility dens ity at treated as t he policy . The policy is used by the agent to interact with t he MDP t o generate a trajectory of states, actions and rewards, over . The return is the sum of discounted future reward from t ime-step onwards, where is a discounting f actor . V alue function is used as the obje ctive func tion in man y RL algorithms. It is d efined to b e the expe cted total discounted re ward, sta rting from state and thereafter following po licy : (9) Similarly , action-value f unction is de fined to be the expected return aft er tak ing an action in state and thereafter fo llowing po licy : (10) The goal of the agent in RL is to l earn a policy which maximizes the expected cumulative discounted reward from the st art state, defined b y the perform ance obje ctive . R L approaches make use of t he recursive relat ionship known as the Bellman equation , which is a fundamental rela tionship betwee n the value of a state-action p air and the value of the subsequent state-act ion pair : (11) For the tar get determ inistic policy , we can remove the inner exp ectation: (12) W e describe the density at state after transitioning for time steps from state by . W e also describe the (improper) discounted state vi sitation distribution for a policy by . The performance o bjective is then defined as an expecta tion as: (13) where indicates the (improper) expected value with res pect to discounted state di stribution 3.2. Policy grad ient method based on a ctor and criti c algorithm For control problems with continuous action space, policy gradient methods are t he most pow erful class of RL algorithms. The fundamental i dea is to iteratively adjust the policy parameters in the direction of the gradient of the performance objective. The policy gradient theorem is t he basic result under lying these algor ithms [45]: (14) The expectation can be formed through an empiric al average of a sample-based estimation (approximation). However , one problem with t his algorithm i s how to estimate the action-value function . In o rder to esti mate both the po licy gradien t a nd simultaneously , the actor -critic algorithm is widely employed based on the policy gradient theorem [45–48]. The actor -critic method relies on two eponymous componen ts. An actor tunes the para meters of the policy by stochastic gradient ascent of Eq. (14). Instead of the unknown true a ction-value function i n E q. (14), an estimation of an action-value function is em ployed wit h parameter vector . The r ole of a critic i s to estimate the a ction-value function bas ed on an appropriate policy evaluation algo rithm such a s temporal-diff erence learn ing. A concern with the above architecture is that estimation bias may be introduc ed by substituting a function approx imator for th e true a ction-value fun ction . However , if the functi on approximator is appropriately selected such that i) and i i) the parameters are determ ined to minimize the m ean-squared erro r , then no bias is induc ed [45], (15) In an off-policy setting [49], we can estimate the policy gradient from trajectories sampled from a differe nt stochastic exploration policy using an importance sampling ratio as: (16) 3.3. Deep determ inistic policy grad ient (DDPG ) The Deep Q Network (DQN) algorithm [ 16][17] is a method based on Q-learni ng t hat successfully leverages a dee p neural net work-based funct ion approximator for estima ting the action-value fu nction . Furthermore, an ex tension of DQN t o continuous action spaces within the o f f -policy actor - critic framework has been developed called the deep deterministic policy gradien t ( DDPG) algorithm [19] . While the policy gradient in DDPG is derived from t he determin istic policy gradient (DPG) theorem [18], it employs deep neural networks as f unction approxi mators fo r bo th the actor policy and the crit ic value function. Q-learning [50], a com monly used off-policy algorit hm, employs the greedy m aximization (or soft maximization) of t he estimated action-value function: . W e consider a deep neural network function approximato r i n place of the tr ue action-value f unction . The function approximator is parameterized by , which is optimized by minimizing the critic loss: (17) where (18) While also depend s on , this is usually ignored. Q-learning is not applicable to con trol problems with continuous action spaces because the greedy policy assumes maximiza tion of the action- value function over a discrete action space, which is computationally impractical in a continuous space. In contrast, th e DDPG algorithm optimizes both a policy and an action-value function, approximated by deep neura l networks, w ithin the actor-critic framework under the assumption o f a deterministic policy parameterized by . This a pproach is applicable to continuous action spaces. I n D DPG, similar to DQN, the c ritic is upda ted by minimizing the mean- squared error based on the Bellman equation. Meanwh ile, the actor optimizes the policy function , which defines a deterministic mapping from states to actions. Specifically , the actor ’ s parameters are updated in the direc tion of the g radient of the estimated action-value function with r espect to the actor parameters. Since the update direction varies for each visited state, the e xpectation is taken over the off-polic y state distribu tion . Defining a perfo rmance objective , applying the ch ain rule results in the DPG theore m [18]: (19) T o improve the stability and robustness of learning, several techniques have been incorporated into DQN and DDPG [16] [17]. One such technique is off-policy mini-batch learning using a replay buffe r , which min imizes co rrelations bet ween s amples and en hanc es opt imization ef ficiency . Additionally , the target networks and with weights and are i ntroduced for compu ting in Eq. (18). The weights and are upd at ed as: and with , resp ectively . By delay ing the upd ates of th e tar get networks, optim ization stabilit y is improved. In summary , the following deterministic off-policy ac tor -critic algor ithm is formu lated [18][19] : (20) (21) (22) In continuous action space s, DDPG employs the following stochastic exploration policy with sampling from a n oise process to ensure suff icient explorat ion [19] . (23) 4. Proposed appr oach 4.1. Latent Markov d ecision process with domain r andomization In this study, the dyna mics (e.g., un ce rtain physical parameters) of the environ ment used as a simulator are randomized during training to expose the RL agent to a diverse range of environments. Through this process, t he RL agent acquires the cap ability to adapt t o mismatches between the s imulator and real worlds, thereby enhancing its generalization and r obustness when deployed in a real environment. This approach, known as domain randomization , has recently gained significant attention especially in the field of robotics , where pre cise modeling is often impractica l for real-world app lications [8]. To enhance robustness against uncertainties, it is pr eferable to train the agent to achieve effective control under various simulator dynamics rather t han in a single specifi c environm ent. Hence, the simulator is modeled as a set of MDPs parameterized by unknown dynamics parameters . In domain randomization, a s et of unc ertain paramet ers is randomly changed at the beginning of each episode , according to the distributio n [8]. The parameter se t remains fixed throughout an episode and is resampled at the beginnin g of the next episode [8][32]. Con sequently, the control problem can be regarded as a set of differen t MDPs, where each MDP i s associated with it s own latent var iables, i.e., a set of the paramete rs . Such a cont rol proble m can be formulated as a latent Markov decision process (LMDP) where the latent var iable can select different MDPs [32,33,51]. The latent variables are introduced to capture variations of a set of t he parameters , and ea ch single trajectory under a randomly sampled environment can b e regarded as an MDP with finite horizon . Formally, we consider a set of th e parameters to parameteriz e t he dynamics of the simulat or (environment) [8] . is defined as a set of MDPs with finite horizon under different sets of the dyn amics parame ters . Le t the LMDP be denoted as , where denote s the distribution of (i.e., the latent variables) over [32][33]. Under the se assumptions, we can modify t he objective function such that the expected return is maximized across the distribut ion of dynamics mode ls [8,32,33]: (24) where the likelihood of a trajecto ry is denoted by under the policy . In the simulator modeled as LMDP, each MDP is randomly selected from a set of MDP s according to the d istribution at the b eginning of each episode. The training process is to find an optimal history- dependent policy for LMDP [32][33 ]. (25) Nevertheless, one serious issue r emains: it becomes m ore difficult f or the RL agent to le arn an effec tive control policy from scratch because the simulator, i.e., environment, is subject to unceasing rando m sampling in domain rando mization. Furth ermore, the resulting policy is prone to be more conserv ative especially when the simulator ha s many aspects of randomized dyna mics [40 – 42] . 4.2. Model-based cont roller as sisted domain rand omization training (MBCA- DRT) This study proposes a new idea i n which domain randomization improves the generalization performance of an RL agent to real testing environmen ts while the training i s efficiently assisted by a MBC. The proposed approach is outlined in Algorithm 1 . Both the RL agent and the MBC are complementary to each other. From the viewpoint of the RL agent, the MBC eliminates the need for many meaningless trials that were due to immature policy search during i nitial iterations. In ot her words , MBC supports the RL agent by stabilizing t he balance between exploration and exploitation, boosting the learning convergence . Because MBC is based on a nominal system model, i t can form the base of the control action from the bot tom. Meanwhile, from the viewpoint of MBC, the rol e of the RL agent is t o ensu re r obustness by compensating for nonlinearity and uncerta inty due to sim- to -real gaps. Because the RL agent does not need to undertake t he entire control action from scratch, its learning process will be easier. Ther efore, only the minimum data and simple n etwork architecture are suf ficient for training. The pr oposed control input is defined as the linear combination of an RL agent ’ s policy and a MBC as follows: (26) (27) The property that t he transition probability dynamics to the next state depend only on the current state and the current action, without being influenced by past states, is called the Markov property [15]. When applying RL , it is des irable for the environmen t dynam ics to follow MDP [52]. To apply domain randomiz ation, we formulate the simulator a s an LMDP ; a set of MDPs with tunable latent variables and finite horizon , where the latent variable can sel ect different MDPs. Eac h single process can be regar ded as an MDP w ith finite horizon . For the hybrid approac h in Eqs. (26) , we need to consider whether each single environment random ly samp led at the beginning of each episode has a Markov property or not. As a general princi ple, the following proposition can be established. Proposition : Suppose that Assumptions 1 and 2 hold. The clo sed-loop system is configured with the nonlinear system in Eqs. (1) and (2) and the controller in Eqs. (7) and ( 8), correspon ding to each variable randomly sampled. Let t h is closed-loop system be denoted as environment E randomly sampled at the beginning of each ep isode. Let the state of env ironment E be . Then, the state transition of environment E satisfies the Markov prope rty ; therefore , LMDP can be formulated with Eq. (26). Proof : The proof follows a similar scheme to [52][53] . The parameter set sampled through domain randomization is uniquely det ermined for each env ironment E . Furthermore, the state of the controlled system in Eqs. (1) and (2) at t ime is uniq uely determined by the state and t he control input at time . Note that and are independent from all past st ates and contro l inputs, as they are exogenous di sturbances. In Eq. (26), is computed with Eq. (8). Therefore, the state transition of environ ment E , which integrates the controlled system and the model-based controller as the closed-loop system, is given as fo llows. (28) According to Eq. (28), the state of environment E at time is uniquely determin ed by the state and the control input at time . Therefore, the state transition dy namics of each environment E fol lows MDP. Algorithm 1: The MBC A-DRT A lgorithm. 1 Input: Environment and trajectories poo l 2 Output: Optima l history-dependen t policy 3 Randomly initial ize the actor’s pol icy parameters and the critic p arameters. 4 Design a MBC with a nominal syst em model. 5 for each episode do 6 randomly samp le dynamic s. 7 randomly selected env ironmen t. 8 Generate rollou t with dynam ics and . 9 10 RL control input from the acto r policy. 11 combination o f the RL policy and the model-based c ontrol . 12 for each gradien t step do 13 Compute the int ernal mem ories of the recur rent actor and critic netwo rks. 14 Update the critic p arameter s by minimizing the mean square d error. 15 Update the actor p olicy parameters u sing the samp led policy gradien t. 16 with update. 17 update the hybrid con trol. 18 end 19 end Remark 1 : Th e above proposition means that the accumulated practical knowledge in previous research of domain ra ndomization is also appl icable to the combined app roach in Eq. (26 ). This is because ea ch environment randomly selected at the beginning of each episode follows t he Markov property , even i f it includes a MBC. In other words, like vanilla domain randomization, we can f ormulat e LMDP for a set of those closed-l oop syste ms. 4.3. Memory-augmen ted actor and cr itic based on l ong short-term memory ( LSTM) The actor and critic netwo rks employ a long short-term memory (LSTM) architecture t o provide the agent with a mechanism for inferring the dynamics of an environment [8][32]. The LSTM network is well-suited for effectively handling long -term dependencies in sequential data [54]. Since p ast state and action i nformation is s tored in the in ternal m emories, the agent can impro ve i ts ge neralization ability to varying environ ments [8]. The in puts of LSTM a re t he current state , th e previous hidden state , and the previous c ell state . The previous hidden state and previ ous ce ll s tate can effec tively store previous dynamic s information, wh i ch is us ed to improve the gene ralization capability. The forg et, inp ut, and o utput ga tes are used t o control what information should be forgotten, retained, and outputted. The three gates are mathematically f ormulated as foll ows [54]: (29) (30) (31) where , , and denote the input we ight, recu rrent weight, and bia s, respectiv ely. represents the ac tivation fu nction. The current cel l state is given by (32) where repres ents the Hadama rd product, and is the cell state ca ndidate given by (33) The current hidde n state is compu ted as follows : (34) With the memory-augmented actor and critic architecture, the information regarding dynamics of the environment (each simulator selected f rom LMDP) can be encoded as hidden states, assisting the RL agent to infer mo re accurate env ironment dyna mics [8,32,33]. For t he LS TM-based actor and cri tic networks, we propose to leverage information on the control input from MBC for training an RL agent. This additional observed information allows for the RL agent to explicitly learn a mechanism by which modeling errors aggravate the nominal controller ’ s performance, which is he lpful for the agent to f ind an effective comp ensation strategy r ealizing robustness. This conf iguration is appr oximately rea lized in actu al implementa tion. 4.4. DDPG algor ithm wit h MBCA- DRT In this study, we employ the DDPG algorithm [19] t o train an RL agent. In additi on, a domain randomization techniqu e is also integrated with DDPG, which is suppor ted by the MBC to boost learning convergence. The proposed algorithm is su mmarized in Algorithm 2 . T he outline is illustrated in Fig. 3. Algorithm 2: DDPG a lgorithm w ith MBCA- DR T. 1 Randomly initial ize critic network and actor with w eights and . 2 Initialize targe t networks and with weights and . 3 Initialize replay b uffer . 4 Design a MBC based on a nominal sys tem model. 5 for each episode do 6 randomly samp le dynamic s. 7 randomly selected env ironmen t. 8 RL control input from the determin istic actor policy. 9 combination of th e RL pol icy and model-based con trol . 10 Initialize a rando m process for exploration policy. 11 Observe initia l state. 12 Perform control according to the explora tion noise, RL agent action, and model-based control. 13 Observe new sta te and obtain reward . 14 Store transition in . 15 for each gradien t step do 16 Sample a random mini-batch of transitions from . 17 Compute the int ernal mem ories of the LSTM actor a nd critic ne tworks. 18 Set . 19 Update the critic p arameter s by minimizing the mean square d error: 20 Update the actor p olicy parameters u sing the samp led policy gradien t: 21 Update the targe t networks: 22 update the hybrid con trol. 23 end 24 end Fig. 3 DDPG algor ithm with MBC A- DRT . 5. Numerical example 5.1. Active vibrati on contr ol of nonlinear pow ertrain system This study validates the proposed approach (i.e., MBCA- DRT ) via application to active damping of a vehicle powertrain system, which suffers from nonlinearity and parametric uncertainty. Previou s studies [55][56] have established a powertrain model illustrated in Fig. 4(a), where the backlash nonlinearity (i.e., dead-zone effect of a discontinuous mechanical gap) increases t he vibration amplitude. The nominal values of t he system parameters are li sted in Table 1. As shown in Fig. 4(b), due to the presence Loss function Input layer Output layer Hidden layer T arget actor network Input layer Output layer Hidden layer LSTM-based critic network Input layer Output layer Hidden layer LSTM-based actor network Input layer Output layer Hidden layer T arget critic network Policy gradient Model-based controller Plant dynamics with Plant dynamics with Plant dynamics with Plant dynamics with A set of different MDPs Randomize dynamics parameter distribution Plant dynamics with Plant dynamics with Plant dynamics with Soft update Soft update Replay buffer Randomly selected plant dynamics Update Update Exploration noise model State, Reward State Input DDPG algorithm with LSTM T ransition Mini -batch Random sample of backlash, the dynamics are disconti nuously changed between t wo modes, backlash mode and contact mode , making the application of t raditional control more challenging. In addition, the powertrain system has parametric variations with respect to the actuator mass and the ve hicle body mass . Under the effects of such uncertain ties, the con trol ob jective is to quickly suppress transient vibrations induced in the vehicle body by applying the control command to the actuator . The control led output is , which must converge to an ideal response (i.e., reference signa l ) such that , with . Fig. 4 Controlled system: (a) power train system with nonlinear backlash and parame tric uncer tainty and (b) two dyn amics modes. In order to design a MBC in Eqs. (7) and (8), a linearize d model, which simplifies the powertra in system in Fig. 4(a) by neglec ting b acklash prope rty and parameter variations, is nece ssary. The deta iled mode l is available in pr evious studies [ 55][56]. Using the lineariz ed nomina l powertra in model of the pr evious Mechanical connection Backlash traverse (dead-zone) Drivetrain mode Backlash mode Contact mode (a) (b) Control input V ehicle vibration e.g., Step input Parameter distribution Parameter distribution Force Backlash study, this study designs an output feedback controller according to model-ba sed linear control theory [57][58]. For application to powertrain control, a feedforwar d input is also added to the controller [55][56] . T able 1 Nominal paramete rs of the power train syste m. Parameter Description Nominal V alue Unit Spring connec ted with N/m Spring between and N /m Spring between and N/m Mass of the actuat or kg Mass of the interme diate pa rt kg Mass of the vehicl e body kg Damper between and Ns/m Damper connected w i th Ns/m Damper of Ns/m Damper between and Ns/m Length of the back lash m Steady va lue of the reference signal fr om 0 to 2 seconds m Steady va lue of the reference signal fr om 2 to 4 seconds m Fig. 5 Application of MBCA-DR T to active vibration control of a nonlin ear powertrain system. 5.2. Verification settings To examine the applicabil ity of domain randomizati on, we prepare t he f ollowing two scenarios. In Scenario 1 , the actuator mass and the vehicle body mass are randomized at the beginning of each episode, whereas the amount of backlash length is fixed. In Scenario 2 , which is a more challenging setup, the backlash length i s also randomized, i n additio n t o t he two masses. Among the physical paramete rs of the powertrain, , , and have particularly significant effects on t he system d ynamics; hence their randomizat ion is essential for robus tness. This is supported by prior studies [55][59] that employed the same powertrain model. In ac tual vehic les, can change drastically with passenger load and cargo, and varies due to aging and manufacturing differences . Backlash Control input Model-based controller LSTM LSTM FC ReLU FC ReLU Action Observation Observation Action V alue Critic Actor DDPG agent Dynamics parameter distribution Nominal model Control input State Design MBCA-DR T Real-world envir onment Uniform randomize dynamics parameter distribution Time Time Time Environment 1 Environment 2 Environment N Sample T rajectory 1 T rajectory 2 T rajectory N T raining Latent MDP Model-based control signal Moreover, bo th scenar ios i nvolve r andomizat ion of a reference si gnal , to which the control led output should conve rge. The set-up for RL is as follows: the observed information includes the reference signal, the controlled output , the tracking error , its i ntegral, and its derivative. In MBCA-DRT, the cont rol input from MBC is additionall y leveraged in the observation, as described in t he previous chapter. Each component of t he observation is properly normalized to facilitate effective learning. The reward function is defined based on the quadratic cost in Eq. ( 4) as: . In the simulations, the weighting matrices of the quadratic cost function in Eq. (4) were selected as and . In general, a larger emphasizes tracking acc uracy, while a larger emphasizes control effo rt saving . In this study, a simple choice of was adopt ed t o balance both aspects. The hyperparamete rs for DDPG are available in Table 2. In many prior works [60] apply ing DDPG, the following hyperparameters of DDPG are crucial: ac tor learning rate, critic learning rate, discount factor, soft target update rate ( i.e., target smooth f actor), batch size, and exploration noise para meters (e.g. Ornstein – Uhl enbeck noise sigma). As a rough heuristic, smaller learning rates tend t o improve training stability but slow convergenc e. Larger batch sizes may stabilize gradient estimates but increase computational burden. A discount factor close to 1 encourages long-term reward consideration, whereas a lower value prioritize s immed iate g ains. The soft update coeff icient is often kept sm all ( e.g. 0.001 ) to slowly track target networks for stability. Increasing Ornstein – Uhlenbec k noise sigma promotes exploration in sea rch proce ss. During the training proces s shown i n Fig. 5, the ab ove-mentioned parameters in the simulator ar e simultaneously randomize d in each episode to allow for the RL agent t o generalize for various environments. Each parameter is randomly changed at the beginning of each episode, according to the uniform distributions such as , and . Table 3 shows each variation amount. MATLAB R2024b was consistent ly used for both training the RL agent and verifying its performance. The specification of the PC wa s as follows: LAPTO P-STP755NN (ThinkPad, Le novo Co r poration), W indows 10 Pro, 64bit ope rating system, x64 base processor , Intel(R) Core(T M) i7-10850H C PU @ 2.70GHz 2.71 GHz. In t he numerical verificat ions, we compare the proposed approach (MBCA-DRT) wit h a case employing only a model-based linear controller (referred t o as Only MBC ). Note that Only MBC includes no compensati on for backlash. Moreover, MBCA-DR T is also compared with conventiona l DRL -based control (refer red to as Only DR ) in wh ich domain randomization does not receive any assistance from a MBC. Tab le 2. Hyp erpa rame ter s for DD PG. DDPG Hype rpar ame ter Value Samp ling tim e s Crit ic le arn ing rate Actor lea rn ing r ate Disco unt fac tor Exp lora tion nois e Ornst ein- Uhl enbe ck A ct ion N ois e Numb er o f th e n euron s in the hidd en laye rs Size of t he min i-bat ch Size of t he repl ay bu ffe r Targe t s moo th fa cto r Hor izon Netw ork a rch i tec ture LSTM + F ully co nnec ted + ReLu Numb er o f ep isode s Tab le 3. Ran domi zed d ynamics para mete rs. Para mete r Rang e Vehic le b ody mas s: Nomin al v alue : Actua to r ma ss: Nomin al v alue : Lengt h of backlas h: (rando mized only in Sce nario 2 ) Nomin al v alue : Steady value of the reference si gnal from 0 to 2 seconds: Steady value of the reference si gnal from 2 to 4 seconds: 5.3. Results and di scussion in Scenari o 1 Figure 6 shows reward curves i n Scenario 1 and Scenario 2 . The red and blue lines describe the epi sode rewards obtained by the pr oposed method (i.e., MBC A-DRT) and Only DR , resp ectively. As shown in the fi gure, the proposed method exh ibits three clear adv antages: (1) t he exploration process i s stabilized within the first few e pisodes; ( 2) convergenc e is achiev ed w ith significantly f ewer episodes; and (3) the final reward level is higher than that of doma in randomization alone. These results conf irm that the proposed method enables more efficient and effective trainin g. By ensuring a baseline control performance from the beginning, MBC prevents the RL agent fr om engaging in unnecessary exploration. As a result, the agent can focus on refining the co ntrol strategy around an already stable b aseline, which substantially accel erates the learning proce ss. It should also be noted that the rewa rd curve o f the proposed method exh ibits a te mporary drop a round 200 episodes i n Fig. 6(b). Such sudden declines may be due to factors such as exploration noise, distributional shifts in the replay buffer, or tempora ry critic i nstability. Neverthele ss, thanks t o the baseline perfor mance ensured by MBC, the agent quickly recovers from this t ransient collapse and continues to conv erge to a stab le and superior p erformance comp ared to dom ain randomizati on alone. Fig. 6 Rewar d curves in (a) Scenario 1 and (b) S cenario 2 . Fi rst, we consider Scenario 1 . Figure 7 shows the control result for a nominal powertrain system without any parametric variations and backlas h nonlinearity. This work quantitati vely evaluates the control performance of each control based on 2 -norm of the tracking er ror , corre sponding to the first term in Eq. ( 4). These results are summarized in Table 4. Figure 7 indicates that all the control systems (propo sed appro ach, O nly DR , and O nly MBC ) succes sfully da mp the vehicle body v ibrations, making the controlled output quickly converge to the target response. According t o Table 4, the minimum norm is achieve d b y Only MBC . It is b ecause there are no sim- to -real gaps between t he nominal model use d for controller des ign and the real system, which means that the MBC shoul d be the best choice. (a) (b) Figures 8-11 show the control results for powertrain system s with nonlinearity and parameter uncertainty. Though we examined more cases by changing patterns of variations of the randomized parameters for Scenario 1 , only the representat ive results are given here. Th ose 2-norm values are available in Tables 5-8. The remarkable point is that the propos ed approach denoted in the r ed line consistently m aintains the high control performance, proving its excellent robustness and generalization capabilities to real testing environment s. Even with the parametric variations in Fi gs. 8-11, the transient vibrations are attenuated. In addition, the overshoots owing to t he effect of backlash are reduced immediately after 2.0 s compa red t o t he cyan and black lines. Consequently, the proposed appro ach can comprehensi vely deal w ith parametric u ncertainty and dynamical no nlinearity. In contrast, the r esidual vibration remains i n the responses by On ly DR , even though instability of the controlled output is avoided in all cases. The cause of such poo r performance lies in the t raining process where the learning convergence is immature. The immature training procedure may require more data (i.e., episodes ) or larger network structures, whereas the proposed approach indicates that the current small setup is sufficient t o a chieve the control objective. This compar ison c learly d em onstrates t hat the introduction of MBC can ac celerate the learn ing process. Despite the sys tem variations, re sponses were stabilized with Only DR due to the conservativeness of the policy. In other words, the RL agent is so overfitting the poli cy to avoid w orst case (i.e., unstable response) that it also l oses its aggre ssiveness t o suppress transien t vibrations. Focusing on the responses by Only M BC , we can see that the variation in control performance is more drastic, a s imp lied from c omparison o f F igs. 8 and 11. Specifically, Tab le 8 pre sents the good performance achie ved by Only MBC . I n contrast, the re sponse is on the ve rge of destabilizat ion in Fig. 8. Since MBC relies on the approximate linear model, robustness cannot be ensured if t he sim- to -rea l gap is not considered expli citly. In all cases, the overshoots largely remain, which is due to the l ack of compensation for b acklash nonl inearity. In summary, the comparative verificati on between the proposed approach, Only MBC , and Only DR shows t he effectiveness o f the combination of doma in randomization and MBC. This combination prevents the con troller from be ing too conserva tive while improving th e robustness. Fig. 7 Time responses of the vehicle body vibrat ion (upper graph) and the control input (lower graph) in Scenario 1 , where all the paramete rs take nominal values and backla sh is absent in th e controlled powe r train. T able 4 2-norm compu ted for the con trol results in Fi g. 7. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 8 Time responses of the vehicle body vibration and t he control input in Scenario 1 with , , , , and the fixed back lash length . T able 5 2-norm compu ted for the con trol results in Fi g. 8. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 9 Time responses of the vehicle body vibration and t he control input in Scenario 1 with , , , , and the fixed back lash length . T able 6 2-norm compu ted for the con trol results in Fi g. 9. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 10 Time responses of the vehicle body vibration and the control input in Scenario 1 with , , , , and the fixed back lash length . T able 7 2-norm compu ted for the con trol results in Fi g. 10. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 11 Time responses of the vehicle body vibration and the control input in Scenario 1 with , , , , and the f ixed backlash length . T able 8 2-norm compu ted for the con trol results in Fi g. 1 1. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm W e also analyze the necess ity of LSTM in the proposed approach. Figure 12 shows the cont rol result obtained by the combination of MBC and domain randomization empl oying multi-layer perceptron s (MLPs), not LSTM. The MLP and LSTM have the same hyperpara meters. The robustness has decreased, resulting in the transient vibration. Th e controlled powertrain system has the same conditions as t hose of Fig. 8. Therefore, t he comparison clarifies the importance of inc orporating memory- augmented networks such as LST M for the actor and criti c to allow the a gent to infer the dynamics of randomized env ironments. Fig. 12 Control result by m ulti-layer perceptron (MLP)-based actor and critic i n Scenario 1 with , , , , and the fixed backlash length . 5.4. Results and di scussion in Scenari o 2 In Scenario 2 , t he size of backlash i s also randomized during training. This is a more challenging setup because of the increas ing number of rando mized paramete rs. The control result for the nominal powertrain sys tem is illustrated in Fig. 1 3. The quantitative comparison is available in Table 9. Although the proposed approach c ompletely suppr esses the overshoot ( i.e., the e ffect of backlash), t he bes t pe rformance is pr ovided by Only MBC . A s discussed in the previous section, t his is a reasonable result s ince the controlled sy stem has no unce rtainties. The st rong r obustness of the propo sed approach is demonstrated through Figs. 14-16 and Tables 10-12 , which indicate the test results of robustness to perturbed powertrain systems. Despite the variations i n backlash length, i n addition to the changed two masses, the red line exhibits the smallest overshoot as well as the reduced transient vibrations in all cases. Compared to t he cyan line, we can obtain the following conclusion: concurrent ly using MBC with domain randomi zation can ensure robustness while preventing the po licy from be ing too conservative . For exam ple, the pow ertrain has the maximum size of backlash in Fig. 14, where Only DR fails to suppress the overshoot due to the backlash . This is because of the too conservative policy. Figure 17 shows the enlarge d view of Fig. 1 4 immediately after 2.0 s. As indicated by the magenta arrow, the cyan wavefor m ( Only DR ) l acks a sufficient downward force in the negative di rection, which is crucial for suppressing overshoot. In other words, th e c ontrol ex hibits a lack of aggressiveness because o f it s conse rvativenes s. In c ontrast, the red line shows t he oppo site tendency, wh er e the large negative force i s in stantaneously applied, ef fectively damping the overshoo t. Compared to t he black line, the robustness of the proposed approach i s also clear ly identified. Only MBC shows the good perf ormances in Figs. 15 and 16, whereas the vibration is hardly attenuated in Fig. 1 4. Analyzing in detail Fig. 17, excessive control input and its phase erro r occur in Only MBC . Th is deterioration is due to the parameter gaps of , , and to their nominal values. On t he other hand, the proposed approa ch is consistently robust against various dynamics in Figs. 14-16. This tendency indica tes the high generalization ability to real test ing environmen ts. Fig. 13 Time responses of the vehicle body vibration (upper graph) and the control input (lower graph) in Scenario 2 , where all the paramete rs take nominal values and backla sh is absent in the controlled powe rtrain. T able 9 2-norm compu ted for the con trol results in Fi g. 13. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 14 Time responses of the vehicle body vibration and the control input in Scenario 2 with , , , , and . T able 10 2-norm compu ted for the con trol results in Fig. 14. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 15 Time responses of the vehicle body vibration and the control input in Scenario 2 with , , , , and . T able 11 2-norm comp uted for the con trol results in Fig. 15. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 16 Time responses of the vehicle body vibration and the control input in Scenario 2 with , , , , and . T able 12 2-norm compu ted for the con trol results in Fig. 16. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 17 Enlarg ed view of the resp onse in Fig. 14. Fig. 18 Breakdown o f the proposed control input in Fig. 14. We can conduc t a detailed analysis of the control i nput computed by the propo sed approach in Fig. 18 , which provides an enlarged view of the breakdown of the total control input compos ed of MBC and RL, focusing on the key time zon e. As discussed below , Fig. 18 supports the presence of our propos ed synergy effect of MBC and RL . The f irst remarkable point is that the con trol behavior of MBC and the total control (i.e., MBC+RL) are generally synchroniz ed, as se en from the matching of their input phases. This means that the base of the control action is f orm ed by MBC, which is mainly responsible for constructing the total control input. As indicated by the d ifference in the input magnitude be tween the red and green lines, how ever, Only MBC results in improper control action due to the system uncertainties, e.g., backlash nonlinearity. Immediately after 2.0 s, the gre en line shows that MBC computes an exc essive amount of control input due t o the dead zone effect of backlash, which will produce shock by unneces sarily accelerating t he actuator. Such a shock effect c auses a large ov ershoot and r emaining vibr ations. As shown in the magenta line, the m ore critical highl ight is the control behavior by RL to properly modify the control input of MBC. As mentioned earlier, MBC generates an excessively large positive control input immediately after 2.0 s, which will lead t o shock due to the effect of b ac klash, specifically during t he transition from the backlash mode to the contact mode. In contrast, RL compute s the negative control input in the oppo site direction to co unteract the excessive control i nput of MBC. This is evident from the phase opposition between t he magenta waveform and the green waveform. The mo d ification by RL appropriately reduces the magnitude of the total control input, indicated by the red waveform, compared to the gre en waveform. Th is contribut es to the improve ment in contro l performance. The corresponding physical phenomena of the above control operat ions are as follows. At 2.0 s, the actuator thrust direction un dergoes a rapid ch ange f rom negative to positive. As show n in Fig . 4, due to the presence of backlash cl earance in the powertrain, the dynamics transition fro m the contact mode to the backlash mode and then back to the contact mode. During the backlash mode, the dead -zone characteristic prevents the ac tuator f rom transmitting force t o the vehicle body. Since MBC does not explicitly account for these dynamics, it c omputes the excessiv ely large control input during t he backlash mode. With only MBC, a shock will be induced at t he moment of transition back to the contact mode. In contrast, RL serves to correct t his error. Specifically, RL applie s the control input in the opposite direction to MBC, providing an appropriate braking effect to the actuator. This achieves a “ soft-landing ” effe ct, effect ively reducing the shock. Another notewor thy as pect of this study is the achievement of superior perform ance by the proposed method, despite utili zing limited data and a relativel y simple neural netwo r k architecture. As sh own in Table 2, the number of training episodes in this study is 300, which is significantly lower than that of similar applications to mechanical system control with domain randomization in related research [32]. Furthermore, the required number of neuro ns i s only 64. The general ization ability to rando mized environments achiev ed under such simpl ified conditions is attributed to the introduction of MBC . In the proposed method, the RL agent does not need to explore the adequate control action from scratch , because M BC provides foundational knowledge regarding how to control sys tem dynamics. During the learning process, t herefore, the RL agent primaril y focuses on enhancing robustness, which is considered less complex than constructing a bas e for control action independently. To facilitate this, the proposed method shares the knowledge on control input from M BC with the RL agent as a l earning cue. To further confirm whether the proposed method can overcome the sim - to -r eal gap, Fig. 19 shows the results of a statistical evaluation of the control system. In this verification, 100 different conditions were generated by r andomly varying the parameters of the pow ertrain, and s tatistical analysis was performed for all of these patterns. Fig. 19 pres ents the time-history average across the 100 ver ification cases. Furthermore, Table 13 summarizes the mean and standard deviat ion of the 2-norm values of t he responses. As can be seen, the proposed method exhibit ed the highest robustness against 100 powertrain variations that differed from the training environment. From these results, it is demonstrated that the proposed method achieves sim- to -real transfer in verifications designed to emulate actual systems where arbitrary pa rameter variat ions may occur. Fig. 19 Mean time responses of 100 trials when random variat ions are applied to the powertrain parameters in Scenar io 2 . T able 13 Statistics of 2-n orm of 100 tri als computed for the control results in Fig. 19. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) Mean values of 2-norm Standard deviation 5.5. Verification on robustness aga inst additional p ossible uncertain ty This se ction investigates the robustness of th e proposed m ethod against un certainties other t han parameter variations in the controlled plant. In an actual powertrain system, observa tion noise inevitably affects sensor measurements. To reflect this, Gaussi an noise with a standar d deviation of 5% of the observation value was added in the training environment. Furthermore, t o account for the vehicle dynamics such as resistance and friction acting on a veh icle body , a frictional force model was incorporated. Figures 20 and 21 show the control performance obtained when the se uncertainties were considered in the training environment. Fo r example, the magenta line shows the open -loop response when observation noise was applied to t he vehicle body vibration. As shown, the proposed m ethod consistently achieved effective vibration suppression even when t he powertrain includes observation noise and friction, demonstrating its robustness. Tables 14 and 15 provide quan titative performance comparisons, further confirming the validity of t he proposed appr oach. These results demonstrate t hat incorporating sens or noise and friction int o the trainin g environment enhan ces the robu stness provid ed by domain random ization and impro ves the gene ralization capab ility of the ac tor network. Fig. 20 Control result when the powertrain includes noise and friction with , , , and . T able 14 2-norm compu ted for the con trol results in Fig. 20. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm Fig. 2 1 Control result when the power train inc ludes noise an d f riction with , , , and . T able 15 2-norm compu ted for the con trol results in Fig. 21. Proposed method (MBCA-DR T) Only domain randomization Only MBC Open-loop (i.e., no control) 2-norm The central claim of this study is that we have demonstrated the potent ial for achieving power ful robustness of control even with li mited data by integrating MBC and RL . From a broader perspective, this effectiveness i s attri butable to the physics (e.g., first principles model)-based reliability of MBC . Even in the current era of advanced AI, “lazy” approach es that solely rely on black-box machine learning for rudely replacing all existing co ntrol system s present inherent limitations. Consequently, the role of MBC is expe cted to remain significan t in future developmen ts. 6. Conclusion For mechanical systems subject t o nonlineari ties and uncertainties, this study presents a novel robust control method based on DRL. T h e proposed approac h relies on the ef fective combination of domain randomization, LSTM-bas ed actor and critic networks, and utilization of MBC. W e develop a robust DDPG algorithm where learning progress is boosted by the hybridized control of RL and MBC, preventing the resultant policy from being t oo conservative. The proposed approach is verified for active vibration control of a compl ex powertrain system with backlash nonlinearity and parametric uncertainty . Compared to conventional control approaches, numeri cal examples confirm that the propos ed approach provides excel lent damping performance and s tronger r obustness against system v ar iations. In the future, experimental verifications will be conducted by implementing the proposed control system in a basic experimental device reflecting a simplified powertrain system. In addition, future work will extend the verification to more complex domain randomization involving a larger combin ation of physical para meters. CRediT au t horship contr ibution sta tement Heisei Y onezawa : Concep tualization, Methodology , Software, V alidation, Investigation, W riting - Original D raft. Ansei Y onezawa : Con ceptualizat ion, V alidation, W r iting - Original Draft. Itsur o Kajiwara : Concept ualizati on, W riting - Original Draft, Supervis ion. Declaration of co mpeting inter est The authors declare that they have no known competing financial interests or personal relationships that could have appe ared to influence the work repo rted in thi s paper . Acknowledgmen t A part of this w ork was supported by the J apan Society for the Promotion of Scien ce (JSPS) KAK ENHI [Grant Number 23K 13273]. Referenc es [1] F. Wang, T. Wu, Y. Ni, P. Ye, Y. Cai, J. Guo, C. Wang, Torsional oscillation suppression - oriented torque compensat e control for regenerative braking of electric powertrain based on mixed logic dynamic mode l, Mech. Syst. Signal Process. 190 (20 23) 110114. https://doi.org /10.1016/j.ymss p.2023.110114. [2] F. Wang, P. Ye, X. Xu, Y. Cai, S. Ni, H. Que, Novel regenerative braking method for transien t torsional oscillation suppression of planetary-gear electrical powertrain, Mech. Syst. Signal Process. 163 (2022) 1 08187. ht tps://doi.org/10.1 016/j.ymssp.2021. 108187. [3] C. Wu, K. Guo, J. Sun, Y. Liu, D. Zheng, Active vibration control in robotic grind ing us ing six- axis accelerat ion feedback, Mech. Syst. Signal Process. 214 (2024) 111379. https://doi.org /10.1016/j.ymss p.2024.111379. [4] S. Zaar e, M.R. Soltanpou r, Adaptive fuzzy global coupled nonsingular fast t erminal sliding mode co ntrol of n-r igid-link elastic-join t robo t m anipulators in pres ence o f u ncertainties, Mech. Syst. Signal Proce ss. 163 (2022) 1 08165. https ://doi.org/10.1016 / j.ymssp.2021.108165. [5] Y. Yang, C. Liu, T. Zhang, X. Zhou, J. Li, Event -triggered composite sliding mode anti-sway control for tower crane systems and experimental verif ication, Mech. Syst. Signal Process. 230 (2025) 112578. h ttps://doi.org/1 0.1016/j.ymssp.2 025.112578. [6] Z. Xu, G. Qi, Q. Liu, J. Yao, ESO-based adaptive full state constra int cont rol of uncertain systems and its application to hydraulic servo systems, Mech. Syst. Signal Process. 167 (2022) 108560. https://doi. org/10.1016/ j.ymssp.2021.108560. [7] R.E. Kalman, On the general theory of control systems, IFAC Proc. Vol. 1 (1960) 491 – 502. https://doi.org /10.1016/S1474-6670(17 )70094-8. [8] X. Bin Peng, M. Andrychowicz, W. Zare mba, P. Abbeel, Sim- to -Real Transfer of Roboti c Control with Dynamics Randomization, in: 2018 IEE E Int. Conf. Robot. Autom., IEEE, 2018: pp. 3803 – 3810. htt ps://doi.org/10.1109 /ICRA.2018.84 60528. [9] S. Xu, X. Liu, Y. Wang, Z. Sun, J. Wu, Y. Shi, Freque ncy shaping- based H∞ c ontrol for active pneumatic vib ration i solation with input voltage saturation, Mech. Syst. Signal Process. 220 (2024) 111705. h ttps://doi.org/1 0.1016/j.ymssp.2 024.111705. [10] A. Noormohammadi-Asl, O. Esrafilian, M. Ahangar Arzati, H.D. Taghi rad, S ystem identification and H∞ -based control of quadrotor attitude, Mech. Syst. Signal Process. 135 (2020) 106358. h ttps://doi.org/1 0.1016/j.ymssp.2 019.106358. [11] Y. Zhao, Y. Zhang, L. Guo, S. Ding, X. Wang, Adv ances in machine learning -based active vibration control f or au tomotive s eat su spensions: A comprehensive review, Mech. Syst. Signa l Process. 231 (2025) 1 12645. ht tps://doi.org/10.1 016/j.ymssp.2025. 112645. [12] Z. Qiu, Z. Hu, Biological evolution r einforcement learning vibration control of a three-flexible- beam coupling multi-body system, Mech. Syst. Signal Process. 231 (2025) 112634. https://doi.org /10.1016/j.ymss p.2025.112634. [13] D. Chen, P. Yu, G. Wang, X. Liu, Y. Ding, J. Jin, Design of a hybrid-mode piezoelectr ic actuator for compact robotic finger bas ed on deep reinforcement l earning, Mech. Syst. Signal Process. 227 (2025) 112401. https:// doi.org/10.1016/j. ymssp.20 25.112401. [14] R.S. Sutton, A.G. Barto, Reinforcement learning: An introduction, MIT Press, Cambridge, 1998. [15] R.S. Sutt on, A.G. Barto, Reinforcement learning: An introduction, 2nd ed., MIT Press, Cambridge, 2018. [16] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, M. Riedmiller, Playing Atari with Deep Reinforce ment Learning, ArX iv Prepr. (2013). https://doi.org /https://doi.org/10.48 550/arXiv.1312 .5602. [17] V. Mnih, K. Kavukcuoglu, D. Silver, A.A. Rusu, J. Veness , M.G. Bellema re, A. Graves, M. Riedmiller, A.K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wi erstra, S. Legg, D. Hassa bis, Human-level control through deep reinforcement learning, Nat ure. 518 (2015) 529 – 533. h ttps://doi.org/ 10.1038/natu re14236. [18] D. Silver, G. Lever, N. Heess, T. Deg ris, D. Wierst ra, M. Riedmille r, Deter ministic policy gradient algorithm s, in: 31s t Int. Conf. Mach. L ea rn. ICML 2014, 2 014: pp. 387 – 395. [19] T.P. Lillicrap, J.J. H unt, A. Pritzel, N. H eess, T. Erez, Y. Tassa, D. Si lver, D. Wierstra, Continuous control with deep reinforce ment learning, in: 4th In t. Con f. L earn. Rep resent. ICLR 2016 - Conf. Track P roc., 2 015. http://arxiv.org /abs/1509.02971. [20] S. Fujimoto, H . Van Hoo f , D. Meger, Addressing Func tion Approximation Error in Actor-Critic Methods, in: 35th Int . Conf. Mach. Learn. PMLR, 2018: pp. 1587 – 1596. https://doi.org /https://doi.org/10.48 550/arXiv.1802 .09477. [21] J. Schulman, F. Wolski, P. Dhari wal, A. Radford, O. Klimov, Proximal Policy Optimization Algorithms, ArX iv Prepr. (2017). h ttps://doi.org /https://doi.o rg/10.48550/a rXiv.1707.06347. [22] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C.L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, R. Lowe, Training l anguage models to fol low instructions with human feedback, Adv. Neural Inf. Proces s. Syst. 35 (2022) 27730 – 27744. http://arxiv.org/ab s/2203.02155. [23] R. Zheng, S. Dou, S. Gao, Y. H ua, W. Shen, B. Wang, Y. Liu, S. Jin, Q . Liu, Y. Zhou, L. Xiong, L. Chen, Z. Xi, N. Xu, W. Lai, M. Zhu, C. Chang, Z. Yin, R. Weng, W. Cheng, H. Huang, T. Sun, H. Yan, T. Gui, Q. Zhang, X. Q iu, X. Huang, S ecrets of RLHF i n L arge Language Models Part I: PPO, ArXiv P repr. (2023). h ttps://doi.org /https://doi.o rg/10.48550/a rXiv.2307.04964. [24] J.K. Viswanadhapall i, V.K. Elumalai, S. S., S. Shah, D. Mahajan, Deep reinforce ment learning with rewar d shaping for tracking control and vib ration suppression o f f lexible link manipulator, Appl. Soft Compu t. 152 (2024) 11 0756. https:// doi.org/10.1016/ j.asoc.2023.110756. [25] M.H. Ahm ed, A. AboH ussien, A . E l-Shafei, A. M. Darwish, A .H. Abd el -Gawad, Acti ve co ntrol of flexible rotors using deep r einforcem ent learning with application of multi -act or-critic deep deterministic policy gr adient, En g. Appl. Artif. Intell. 124 (2023) 106593. https://doi.org /10.1016/j.engappa i.2023.106593. [26] C. Wang, W. Cheng, H. Zh ang, W. Dou, J. Chen, A n immune op t imization dee p reinforcement learning control method used for magnetorheologica l elastomer vibration absorber, Eng. Appl. Artif. Intell. 137 (2024) 109108. h ttps://doi.o rg/10.1016/j.enga ppai.2024.109108. [27] Z. Qiu, Y. Liu, X. Zhang, Reinforcement learning vibration control and trajectory planning optimization of translational flexible hinged plate sys tem, Eng. Appl. Artif. Intell. 133 (2024) 108630. https://doi. org/10.1016/ j.engappai.2024.1086 30. [28] Y. -A. Zhang, S. Zhu, Novel Model-free Optimal Active Vibration Contr ol Strategy Based on Deep Reinforcement Learning, Struct. Control Heal. Monit. 2023 (2023) 1 – 15. https://doi.org /10.1155/202 3/6770137. [29] J. Panda, M. Chopra, V. Matsagar, S. Chakraborty, Contin uous control of structural vibra tions using hybrid deep reinforcement learning policy, E xpert Syst. Appl . 252 (20 24) 124075. https://doi.org /10.1016/j.esw a.2024.124075. [30] G. Chen, Z. Ch en, L. Wang, W. Zhan g, D eep D eterminist ic Poli cy Gradi ent and A ctive Disturbance Rejection C ontroller based coordinat ed co ntrol for gearshi ft manipula tor o f dr iving robot, Eng. Ap pl. Artif. Intell . 117 (2023) 105586. https://doi.org /10.1016/j.engappai.2022. 105586. [31] T. Slawik, B. Wehbe, L. Christensen, F. Kirch ner, Deep Reinforcement Lear ning for Path - Following Control of an Autonomous Surface Vehicle using Domain R andomization, IFAC - PapersOnLine. 58 (2024) 21 – 26. h ttps://doi.org/10.10 16/ j.ifacol.202 4.10.027. [32] J. Zhang, C. Zh ao, J. Ding, Deep reinforcemen t le arning wi th dom ain r andomization fo r overhead crane control with payl oad mass variations, Control Eng. Pract. 141 (2023) 105689. https://doi.org /10.1016/j.conengpr ac.2023.105689. [33] X. Chen, J. Hu, C. Jin, L. Li, L. Wang, Understanding Domain Randomization for Sim - to -rea l Transfer, in: ICLR 2022 - 10th Int. Conf. Learn. Represent., 2021: pp. 1 – 28. https://doi.org /https://doi.org/10.48 550/arXiv.2110 .03239. [34] J. Matas, S. James, A.J. Davison, Sim - to -Rea l Reinfor cement Learning for Deformable Object Manipulation, in: 2nd Conf. Robot Learn. PMLR, 2018: pp. 734 – 743. http://arxiv.org/ab s/1806.07851. [35] Z. Li, X. Cheng, X. Bin Peng, P. Abbeel, S. Levine, G. Berseth, K. Sreenath, Reinforc ement Learning for Robust Parameterized Locomotion Control of Bipedal Robots, in: 2021 IEEE Int. Conf. Robot. Autom., IEEE, 2021: pp . 2811 – 2817. https://doi.org /10.1109/ICRA48506.2021. 9560769. [36] X. Bin Peng, E. Couman s, T. Zhang, T.-W. Lee, J. Tan, S. Levine, Learning Agile Robotic Locomotion Skills by Imitating Animals, in: Robot. Sci. Syst., Robotics: Science and Systems Foundation, 2020. https://doi.or g/10.15607/RSS.2020 .XVI.064. [37] Q. Liao, B. Zhang, X. Huang, X. Huang, Z. Li, K. Sreena th, Berkeley Humanoid: A Resea rch Platform for Learning-based Control, ArXiv Prepr. (2024). https://doi.org /https://doi.org/10.48 550/arXiv.2407 .21781. [38] X. Gu, Y .-J. Wang, X. Zhu, C. Shi, Y. Guo, Y. Liu, J. Chen, Advanc ing Hu manoid Locomotion: Mastering Challengin g Terrains with Denoising World Model Learning, in: Robot. Sci. Syst., Robotics: Scienc e and Systems Founda tion, 2024. ht tps://doi.org/1 0.15607/RSS.2024.XX .058. [39] A. Loquer cio, E. Kauf mann, R . Ran ftl, A. Dosovi tskiy, V. K oltun, D. Scar amuzza, Deep Drone Racing: From Simulation to Reality With Domain Randomization, IEEE Trans. Robot. 36 (2020) 1 – 14. https ://doi.org /10.1109/TRO.201 9.2942989. [40] O. Nachum, M. Ahn, H. Ponte, S. Gu, V. Kumar, Multi-Agent Manipulation vi a Locomotion using Hierarchical Sim2Real, Proc. Mach. Learn. Res. 100 (2019) 110 – 121. https://doi.org /https://doi.org/10.48 550/arXiv.1908 .05224. [41] F. Ramos, R. Possas, D. Fox, BayesSim: Adaptive Domain Randomization Via Probabilistic Inference for Robotics Simulators, in: Robot. Sci . Syst. XV, Robotics: Science and Syst ems Foundation, 2019. https://doi.or g/10.15607/RSS.2019 .XV.029. [42] Y. Cheng, P. Zhao, F. Wang, D.J. B lock, N. Hovakimyan, Improv ing th e Robustness of Reinforcement Learning Policies With L1 Adaptive Control, IEEE Robot. Autom. Lett. 7 (2022) 6574 – 6581. https:/ /doi.org/10.1109 /LRA.2022.31 69309. [43] Z. Yao, X. Liang, S. Wang, J. Yao, Model-Data Hybrid Driven Contro l of Hydraulic Euler – Lagrange Systems, IEEE/ASME Trans. Mechatronics. 30 (2025) 131 – 143. https://doi.org /10.1109/TM ECH.2024.339012 9. [44] L.P. Kaelbling, M.L. Littman, A.W. Moore, Reinforcement Learning: A Survey, J. A rtif. Intell . Res. 4 (1996) 237 – 285. h t tps://doi.org/10.1613 / jair.301. [45] R.S. Sutton, D. McAllester, S. Singh, Y. Mansour, Policy gradient methods for reinforcement learning with function approximation, i n: Adv. Neural Inf. Process. Syst. 12, 200 0: pp. 1057 – 1063. [46] J. Peters, S. Vijayakumar, S. Schaal, Natural Actor-Critic, in: 16th Eur. Conf. Mach. Learn., 2005: pp. 280 – 291. h ttps://doi.org/1 0.1007/11564096 _29. [47] S. Bhatnagar, R.S. Sutton, M. Ghavamzadeh, M. Lee, Incremental natural actor -critic algorithms, in: Adv. Neural Inf. Process. Sys t. 20 - Proc. 2007 Co nf ., 2007. [48] T. Degris, P.M. Pilars ki, R.S. Sutton, Model-Free reinforcement learning wit h continuous action in practice, in : 2012 Am. Control Co nf ., IEE E, 2012: pp. 2177 – 2182. https://doi.org /10.1109/AC C.2012.6315022. [49] T. Degris, M. White, R.S. Sutto n, Off-Policy Actor-Critic, in: Proc. 29th Int. Conf. Mach. Learn. ICML 2012, 2012: pp. 457 – 464. h ttp://arxiv.org /abs/1205.4839. [50] C.J.C.H. Wa tkins, P. Dayan, Q-learning, Mach. Learn. 8 (1992) 279 – 292. https://doi.org /10.1007/BF00992698. [51] J. Kwon, Y. Efroni, C. Caramanis, S. Mannor, RL for Latent MDPs: Regret Guarant ees and a Lower Bound, Adv. Neural Inf. Process. Syst. 34 (2021) 24523 – 24534. https://doi.org /https://doi.org/10.48 550/arXiv.2102 .04939. [52] Y. Okawa, T. Sasaki, H. Iwane, Control Approach Combining Reinforce ment Learning and Model-Based Control, in: 2019 12th Asian Control Conf. ASCC 2019, JSME, 2019: pp. 1419 – 1424. [53] I. Koryakovskiy, M. Kudruss, H. Vallery, R. Babuska, W. Caarls, Model -Plant Mismatch Compensation U sing Reinforce ment Learning, IEEE R obot. Autom. Le tt. 3 (2018 ) 2471 – 2477. https://doi.org /10.1109/LRA .2018.2800106. [54] S. Hochreiter, J. Schmidhuber, Long Short-Term Memory, Neural Comput. 9 (1997) 1735 – 1780. https://doi.org /10.1162/nec o.1997.9.8.1735. [55] H. Yonezawa, A. Yoneza wa, T. Hatano, S. Hiramatsu, C. Nishidome, I. Kajiwara, Fuzzy - reasoning-based r obust v ibration con troller for drivet rain mechanism with various control input updating timings, Mech. Mach. Theory. 175 (2022) 104957. https://doi.org /10.1016/j.mechmach theory.2022.104 957. [56] H. Yonezawa, A. Yone zawa, I . Kajiwara, Experi mental validat ion of adapti ve grey wolf optimizer-based powertrain vibration control w it h back lash hand ling, Mech. Mach. Theory. 20 3 (2024) 105825. h ttps://doi.org/1 0.1016/j.mech machtheory.2 024.105825. [57] M. Chilali, P. Gahinet, H∞ design with pole placement constra ints: An LMI approach, IEEE Trans. Automa t. Contr. 41 (1996) 3 58 – 367. https://do i.org/10.1109 /9.486637. [58] Zhou K, Doyle JC, G lover K, Robust and Optima l Control, P renticeHall, New J ersey, 1996. [59] H. Yonezawa, A. Yoneza wa, I. Kajiwara, Grey wolf optimization tuned drivetrain vibration controller with backlash compensation strategy using time -dependent-switched Kalman filter, Proc. Inst. Mech. Eng. Part D J. Automob. Eng. (2024). https://doi.org /10.1177/095440702412 40019. [60] R. Liessner, J. Schmitt, A. Dietermann, B. Bäker, Hyperparameter Optimization f or Deep Reinforcement Learning in Vehicle Energy Management, i n: Proc. 11th Int. Conf. Agents Artif. Intell., SCITEPRES S - Science and Technology Publ ications, 2019: pp. 134 – 144. https://doi.org /10.5220/000 7364701340144.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment