Chain-of-Look Spatial Reasoning for Dense Surgical Instrument Counting
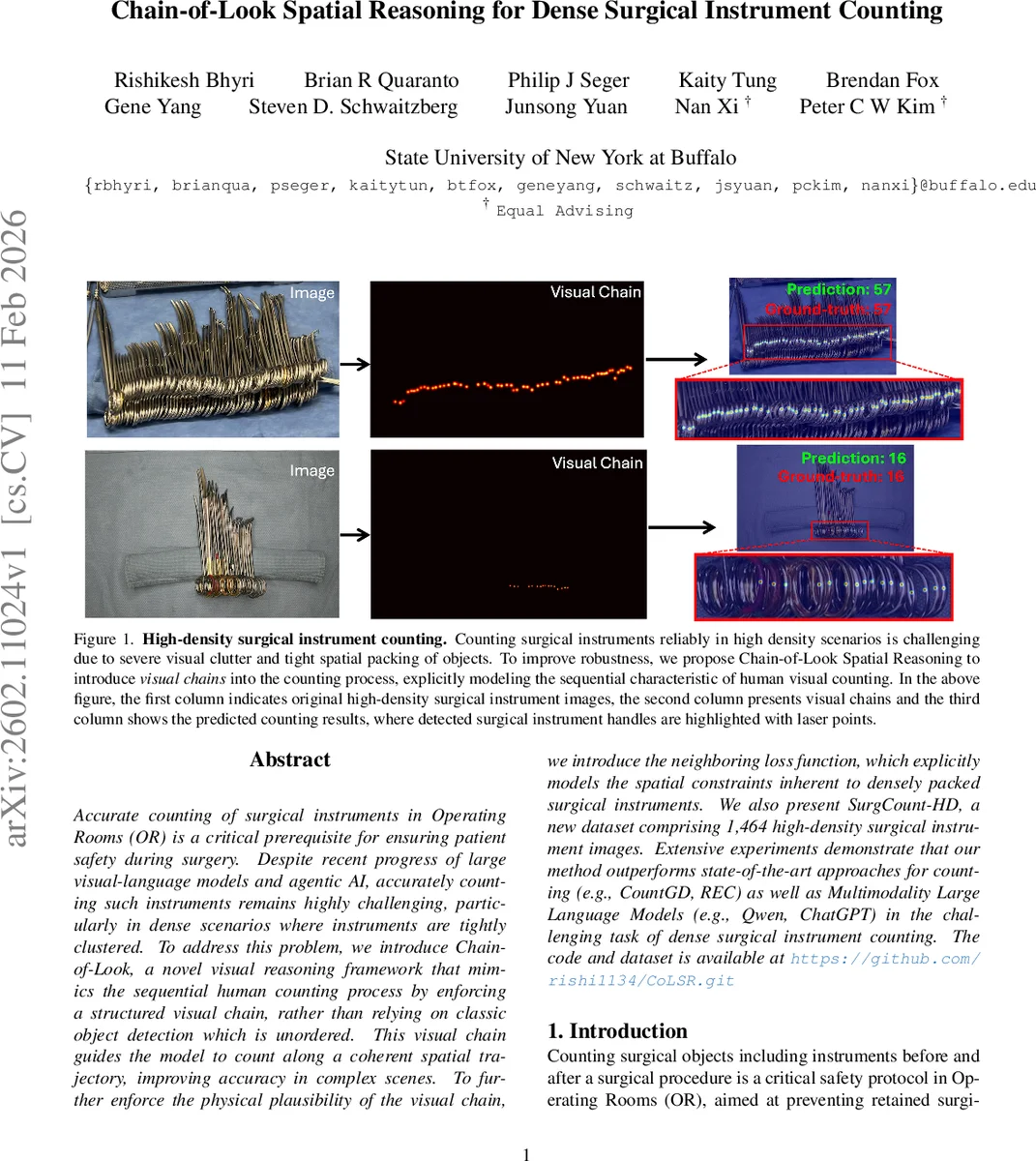
Accurate counting of surgical instruments in Operating Rooms (OR) is a critical prerequisite for ensuring patient safety during surgery. Despite recent progress of large visual-language models and agentic AI, accurately counting such instruments remains highly challenging, particularly in dense scenarios where instruments are tightly clustered. To address this problem, we introduce Chain-of-Look, a novel visual reasoning framework that mimics the sequential human counting process by enforcing a structured visual chain, rather than relying on classic object detection which is unordered. This visual chain guides the model to count along a coherent spatial trajectory, improving accuracy in complex scenes. To further enforce the physical plausibility of the visual chain, we introduce the neighboring loss function, which explicitly models the spatial constraints inherent to densely packed surgical instruments. We also present SurgCount-HD, a new dataset comprising 1,464 high-density surgical instrument images. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches for counting (e.g., CountGD, REC) as well as Multimodality Large Language Models (e.g., Qwen, ChatGPT) in the challenging task of dense surgical instrument counting.
💡 Research Summary
Accurate counting of surgical instruments in the operating room (OR) is a critical safety measure to prevent retained items, yet manual counting is time‑consuming, error‑prone, and especially difficult in high‑density settings where instruments are tightly clustered and partially occluded. Existing automated counting approaches fall into two families: density‑map methods that estimate a continuous density field and sum it, and detection‑based methods that count bounding boxes. Both treat the problem as an unordered set, ignoring the sequential nature of human counting, where a technician typically scans the tray from left to right (or another consistent direction), checking each item one by one. This sequential visual strategy reduces omissions and double‑counts, a fact well documented in cognitive psychology.
The paper introduces Chain‑of‑Look Spatial Reasoning (CoLSR), a novel framework that explicitly models this human‑like sequential process. CoLSR consists of two main components: (1) a Visual Chain Generator that produces a structured visual sequence (the “visual chain”) guiding the counting, and (2) a Neighboring Loss that enforces physical plausibility along that chain by penalizing unrealistic gaps or overlaps between adjacent predicted objects.
Visual Chain Generator builds on the open‑world counting model CountGD. An image encoder (Swin‑B transformer) extracts multi‑scale features, which are projected to 256‑dimensional tokens. A text encoder (BERT) processes a class‑specific description (“circular instrument handle”) and learnable prompt tokens (T_C) that act as class‑specific priors. A feature enhancer f_ϕ fuses image tokens, visual exemplar tokens (derived via RoIAlign from initial detections), and text tokens through six self‑attention blocks followed by six cross‑attention blocks. The fused representation is fed to a cross‑modality decoder that outputs confidence scores and bounding‑box coordinates for a set of 900 high‑similarity query patches. This pipeline yields a coarse visual chain—an ordered list of candidate instrument locations that respects the chosen scanning direction.
Neighboring Loss refines the chain. First, Hungarian matching aligns each predicted bounding box with a ground‑truth box using a cost that combines L1 distance of centers and classification cost. After matching, the model examines the ordered sequence in a fixed direction (e.g., left‑to‑right). For each pair of adjacent objects, the loss computes the L2 distance between the predicted inter‑object distance (d_i^P) and the ground‑truth inter‑object distance (d_i^G). Summing these terms across the chain yields L_neigh = Σ_i ||d_i^P – d_i^G||². This loss forces the model to keep the predicted ordering and spacing consistent with the true physical arrangement, effectively teaching the network to follow a coherent spatial trajectory rather than scattering independent detections.
The authors also contribute SurgCount‑HD, a new dataset of 1,464 high‑density surgical instrument images (1,236 for training, 228 for testing). Each image depicts a back‑table layout where instrument handles face the camera; only a single class (“circular instrument handle”) is annotated with tight bounding boxes. The dataset reflects real‑world challenges: heavy occlusion, visual similarity, and dense packing. To illustrate difficulty, the authors evaluated GPT‑5 on several test images; the model dramatically over‑counted (e.g., predicting 84 vs. ground‑truth 57), underscoring the inadequacy of current multimodal LLMs for this task.
Experimental results show that CoLSR outperforms state‑of‑the‑art counting methods, including CountGD, REC, DQ‑DETR, and CAD‑GD, across MAE, RMSE, and F1 metrics. The neighboring loss contributes a measurable boost, reducing average absolute error to under 5 % of the true count, while maintaining real‑time inference (~30 FPS on an RTX 3090). Multimodal large language models (Qwen, ChatGPT, GPT‑5) lag far behind, confirming that specialized visual‑spatial reasoning is essential for dense instrument counting.
Limitations and future work are candidly discussed. The current implementation assumes a single scanning direction, which may be suboptimal for more complex 2‑D or 3‑D arrangements. The model is trained on a single class; extending to multiple instrument types will require additional class‑specific prompts and possibly a hierarchical chain representation. Scaling the dataset to include diverse surgical specialties, lighting conditions, and camera angles would further test generalization. The authors suggest exploring multi‑directional chains, graph‑based ordering, reinforcement‑learning‑driven path planning, and integration of depth information to handle occlusions more robustly.
In conclusion, CoLSR demonstrates that embedding human‑like sequential visual reasoning into deep models can dramatically improve counting performance in densely packed, safety‑critical environments. By generating a visual chain and enforcing spatial consistency through the neighboring loss, the framework bridges the gap between unordered detection and ordered human enumeration, offering a promising step toward reliable, automated instrument counting in real OR workflows.
Comments & Academic Discussion
Loading comments...
Leave a Comment