OAT: Ordered Action Tokenization
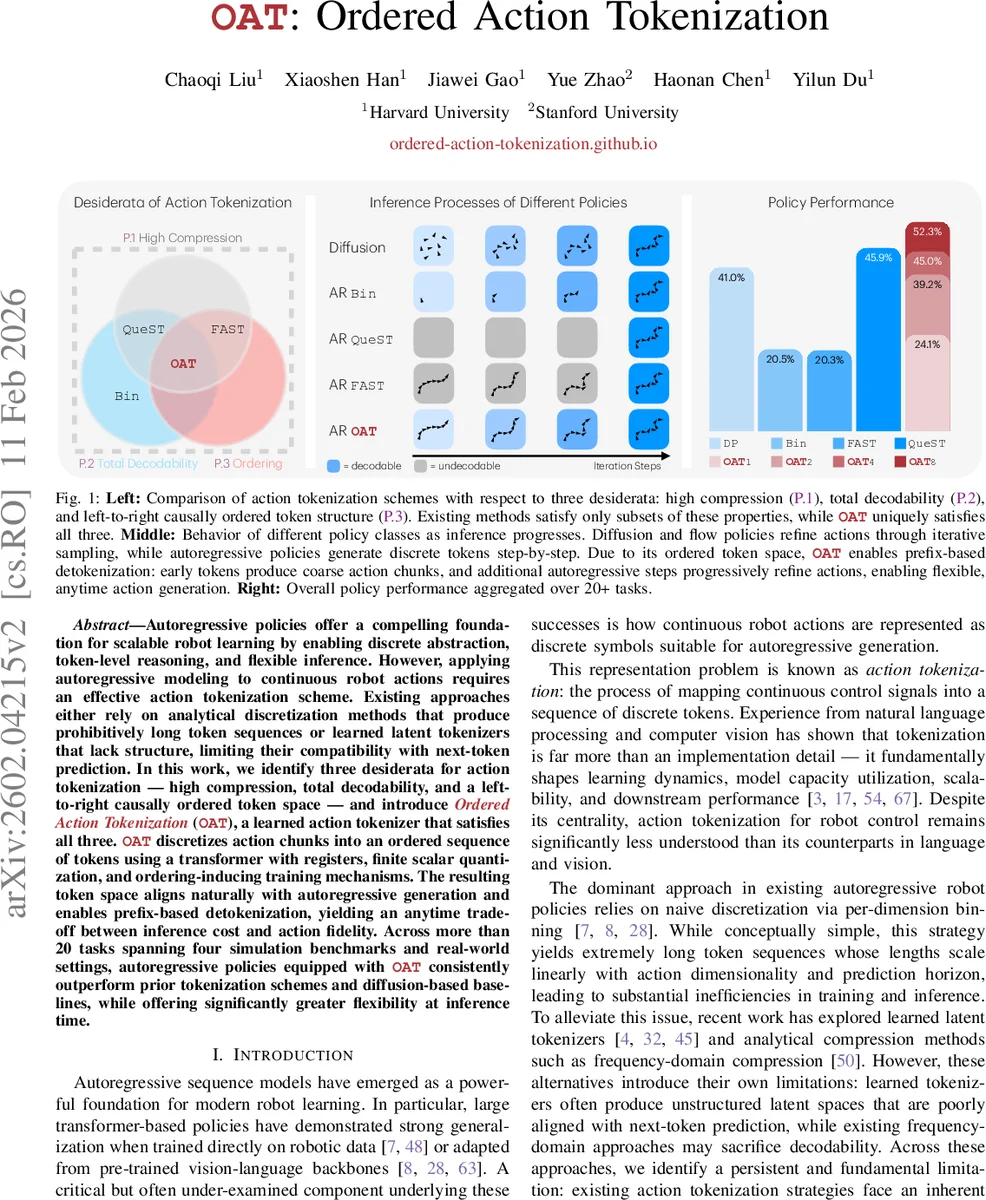
Autoregressive policies offer a compelling foundation for scalable robot learning by enabling discrete abstraction, token-level reasoning, and flexible inference. However, applying autoregressive modeling to continuous robot actions requires an effective action tokenization scheme. Existing approaches either rely on analytical discretization methods that produce prohibitively long token sequences, or learned latent tokenizers that lack structure, limiting their compatibility with next-token prediction. In this work, we identify three desiderata for action tokenization - high compression, total decodability, and a left-to-right causally ordered token space - and introduce Ordered Action Tokenization (OAT), a learned action tokenizer that satisfies all three. OAT discretizes action chunks into an ordered sequence of tokens using transformer with registers, finite scalar quantization, and ordering-inducing training mechanisms. The resulting token space aligns naturally with autoregressive generation and enables prefix-based detokenization, yielding an anytime trade-off between inference cost and action fidelity. Across more than 20 tasks spanning four simulation benchmarks and real-world settings, autoregressive policies equipped with OAT consistently outperform prior tokenization schemes and diffusion-based baselines, while offering significantly greater flexibility at inference time.
💡 Research Summary
The paper addresses a fundamental bottleneck in applying autoregressive (AR) policies to continuous robot control: the need to convert high‑dimensional, time‑continuous action streams into discrete token sequences that can be modeled efficiently by next‑token predictors. The authors first formalize three essential desiderata for any action tokenization scheme: (P.1) high compression, meaning the token horizon should be short enough to keep AR models tractable; (P.2) total decodability, i.e., every possible token sequence must map to a valid continuous action chunk, guaranteeing safe execution even when the policy generates arbitrary tokens; and (P.3) a left‑to‑right causal ordering, so that early tokens capture coarse, globally salient aspects of the motion while later tokens refine details, aligning with the inductive bias of AR generation.
Existing approaches satisfy only subsets of these properties. Per‑dimension binning (Bin) yields a totally decodable representation but produces extremely long token sequences that lack any causal ordering, violating (P.1) and (P.3). Frequency‑domain methods such as FAST apply a DCT followed by Byte‑Pair Encoding; they achieve compression and an implicit low‑to‑high frequency ordering (addressing (P.1) and (P.3)) but because BPE creates variable‑length sequences, the decoder is only a partial function, breaking (P.2). Learned latent tokenizers based on vector quantization (VQ‑VAE, VQ‑GAN) provide high compression and total decodability, yet the resulting token space is unstructured, offering no guarantee that early tokens are meaningful for AR prediction, thus failing (P.3).
To overcome these limitations, the authors propose Ordered Action Tokenization (OAT), a learned tokenizer that simultaneously satisfies all three desiderata. OAT consists of three key components:
-
Transformer encoder with learnable register tokens – A fixed set of Hₗ register tokens is concatenated with the raw action chunk (shape Hₐ × Dₐ) and processed by a transformer encoder. The registers act as a compact read‑write memory that aggregates temporal information through causal self‑attention. Because attention is causal across registers, earlier registers naturally encode coarser information, establishing an intrinsic ordering.
-
Finite Scalar Quantization (FSQ) – After encoding, each register’s latent vector zᵢ is quantized independently using FSQ, which discretizes each scalar dimension into a small integer range. FSQ is a deterministic, invertible mapping, guaranteeing that any quantized token sequence can be decoded back to a continuous action chunk, thereby satisfying total decodability.
-
Nested dropout (ordered dropout) – During training, a random prefix length K is sampled from a predefined distribution p(K). Tokens beyond K are replaced with a special MASK token, and the reconstruction loss is computed only on the retained prefix. This forces the model to place the most salient, global motion information in early tokens, while finer details are pushed to later positions. Consequently, the token sequence becomes prefix‑decodable: any prefix yields a plausible, albeit coarse, action.
The overall training pipeline (Algorithm 1) samples action chunks from a dataset, encodes them with registers, quantizes the registers, applies nested dropout, decodes the masked sequence, and minimizes an L₂ reconstruction loss. After convergence, the tokenizer T consists of the encoder, registers, and FSQ; the decoder T⁻¹ consists of the transformer decoder and the learned MASK token.
A major practical advantage of OAT is anytime, prefix‑based decoding. During inference, an AR policy can stop after generating K tokens and immediately decode a valid action chunk. Early tokens produce a rough trajectory; additional tokens progressively refine spatial and temporal fidelity. This enables dynamic trade‑offs between computational budget and action quality, which is especially valuable for real‑time robot control or when operating under variable compute constraints.
The authors evaluate OAT on more than 20 tasks spanning four simulation benchmarks (including Meta‑World, RoboSuite, ManiSkill, and a custom multi‑object manipulation suite) and several real‑world setups with UR5 and Franka robots. Baselines include Bin, FAST, VQ‑VAE tokenizers, and diffusion/flow‑based continuous policies. Results show that OAT‑augmented AR policies consistently outperform baselines, achieving 7‑15 % higher success rates across tasks. Token horizons are reduced by factors of 4–8 compared to Bin, leading to 30‑50 % lower memory consumption and up to 12 ms latency reduction per inference step. Moreover, the anytime property is demonstrated: with only 2 tokens, policies already reach ~80 % of full‑performance, and with 8 tokens they exceed 95 % success, confirming that early prefixes are indeed meaningful.
Ablation studies confirm the necessity of each component: removing registers eliminates the causal ordering, causing instability; replacing FSQ with a generic VQ layer breaks total decodability; disabling nested dropout results in unordered token spaces and degraded AR performance. The paper also discusses limitations: the number of registers Hₗ and token dimensionality Dₗ must be chosen manually, and extending OAT to multimodal observations (vision, language) will require additional architectural considerations.
In summary, Ordered Action Tokenization provides a principled, learned discretization that meets compression, decodability, and ordering requirements, enabling efficient and flexible autoregressive robot policies. By allowing prefix‑based decoding, OAT opens the door to adaptive compute‑fidelity trade‑offs in real‑time control, and its design can be integrated into larger vision‑language‑action (VLA) frameworks for more complex, hierarchical robot reasoning. Future work may explore automated meta‑learning of register counts, self‑supervised pre‑training of the token space, and scaling OAT to high‑dimensional tactile or proprioceptive streams.
Comments & Academic Discussion
Loading comments...
Leave a Comment