Improving Reasoning for Diffusion Language Models via Group Diffusion Policy Optimization
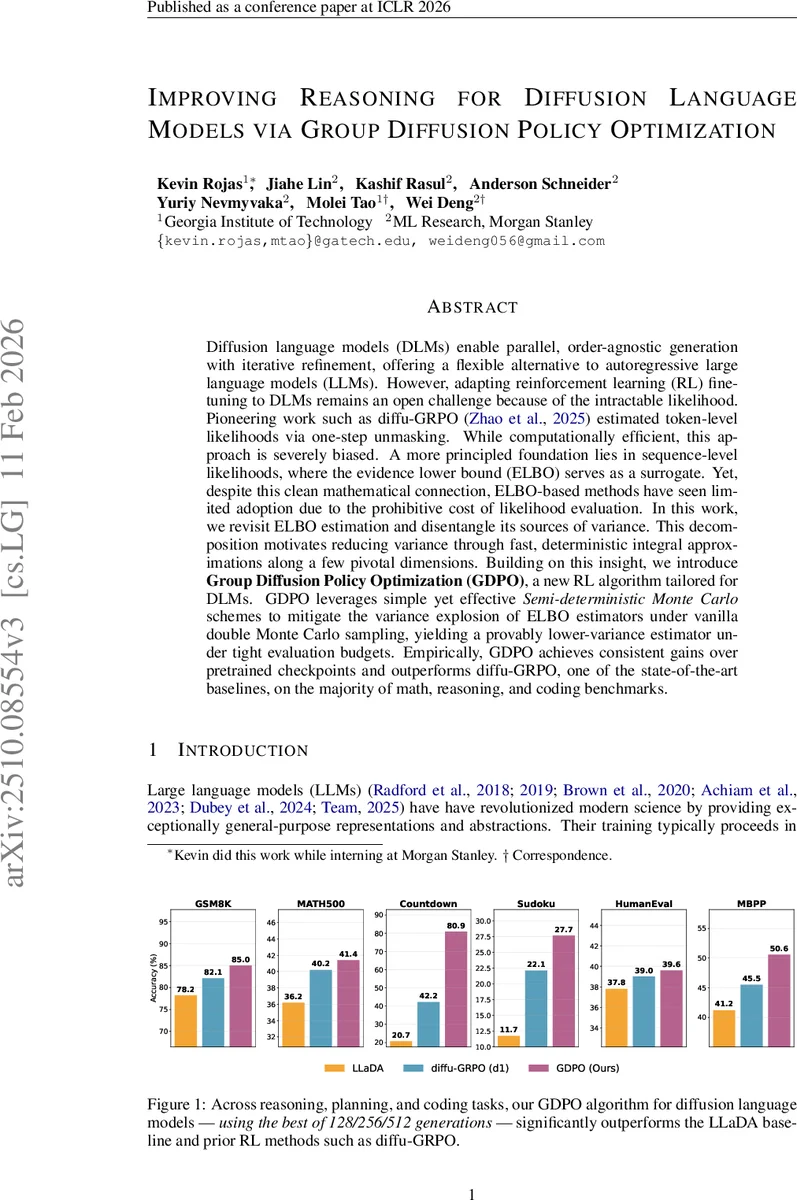
Diffusion language models (DLMs) enable parallel, order-agnostic generation with iterative refinement, offering a flexible alternative to autoregressive large language models (LLMs). However, adapting reinforcement learning (RL) fine-tuning to DLMs remains an open challenge because of the intractable likelihood. Pioneering work such as diffu-GRPO estimated token-level likelihoods via one-step unmasking. While computationally efficient, this approach is severely biased. A more principled foundation lies in sequence-level likelihoods, where the evidence lower bound (ELBO) serves as a surrogate. Yet, despite this clean mathematical connection, ELBO-based methods have seen limited adoption due to the prohibitive cost of likelihood evaluation. In this work, we revisit ELBO estimation and disentangle its sources of variance. This decomposition motivates reducing variance through fast, deterministic integral approximations along a few pivotal dimensions. Building on this insight, we introduce Group Diffusion Policy Optimization (GDPO), a new RL algorithm tailored for DLMs. GDPO leverages simple yet effective Semi-deterministic Monte Carlo schemes to mitigate the variance explosion of ELBO estimators under vanilla double Monte Carlo sampling, yielding a provably lower-variance estimator under tight evaluation budgets. Empirically, GDPO achieves consistent gains over pretrained checkpoints and outperforms diffu-GRPO, one of the state-of-the-art baselines, on the majority of math, reasoning, and coding benchmarks.
💡 Research Summary
Diffusion language models (DLMs) have emerged as a compelling alternative to traditional autoregressive large language models (LLMs) because they generate text in a parallel, order‑agnostic fashion and allow iterative refinement of tokens. However, adapting reinforcement‑learning (RL) fine‑tuning methods—such as PPO or GRPO—to DLMs is non‑trivial, primarily because the likelihood of a complete sequence under a diffusion process is intractable. Prior work (diffu‑GRPO) sidestepped this issue by estimating token‑level likelihoods through a single‑step unmasking operation. While computationally cheap, that approach discards important token‑level dependencies, leading to a severely biased gradient signal.
The authors of this paper revisit the evidence lower bound (ELBO) as a principled surrogate for the true log‑likelihood of a sequence generated by a diffusion model. The ELBO can be expressed as an integral over the continuous time variable t (the masking ratio) of an expectation over the randomly masked sequence yₜ. Two sources of stochasticity therefore affect the estimator: (1) sampling the time t and (2) sampling which tokens are masked at that time. Empirical variance decomposition on 1,000 prompts shows that roughly 96 % of the total variance stems from the random choice of t, while the variance contributed by random masking is comparatively minor.
Motivated by this observation, the paper introduces a Semi‑deterministic Monte Carlo (SDMC) estimator. Instead of treating the ELBO as a double Monte‑Carlo problem, the outer integral over t is approximated deterministically using a small quadrature rule (e.g., Gaussian‑Legendre with N ≈ 3 points). For each fixed tₙ, the inner expectation over masked sequences is estimated with a tiny number of Monte‑Carlo samples (K ≈ 2–3). This hybrid approach eliminates the dominant source of variance while retaining unbiasedness in the limit of large N and K. Experiments comparing SDMC to a naïve double‑Monte‑Carlo estimator demonstrate a reduction in both bias and variance by more than 30 % with only a handful of function evaluations.
Building on the low‑variance ELBO estimator, the authors propose Group Diffusion Policy Optimization (GDPO), a new RL algorithm tailored for DLMs. GDPO inherits the group‑level importance‑ratio and advantage‑normalization machinery from Group Relative Policy Optimization (GRPO) but replaces token‑level likelihood ratios with the SDMC‑estimated ELBO differences. The objective is:
L_GDPO(θ) = E_q
Comments & Academic Discussion
Loading comments...
Leave a Comment