Optimistic World Models: Efficient Exploration in Model-Based Deep Reinforcement Learning
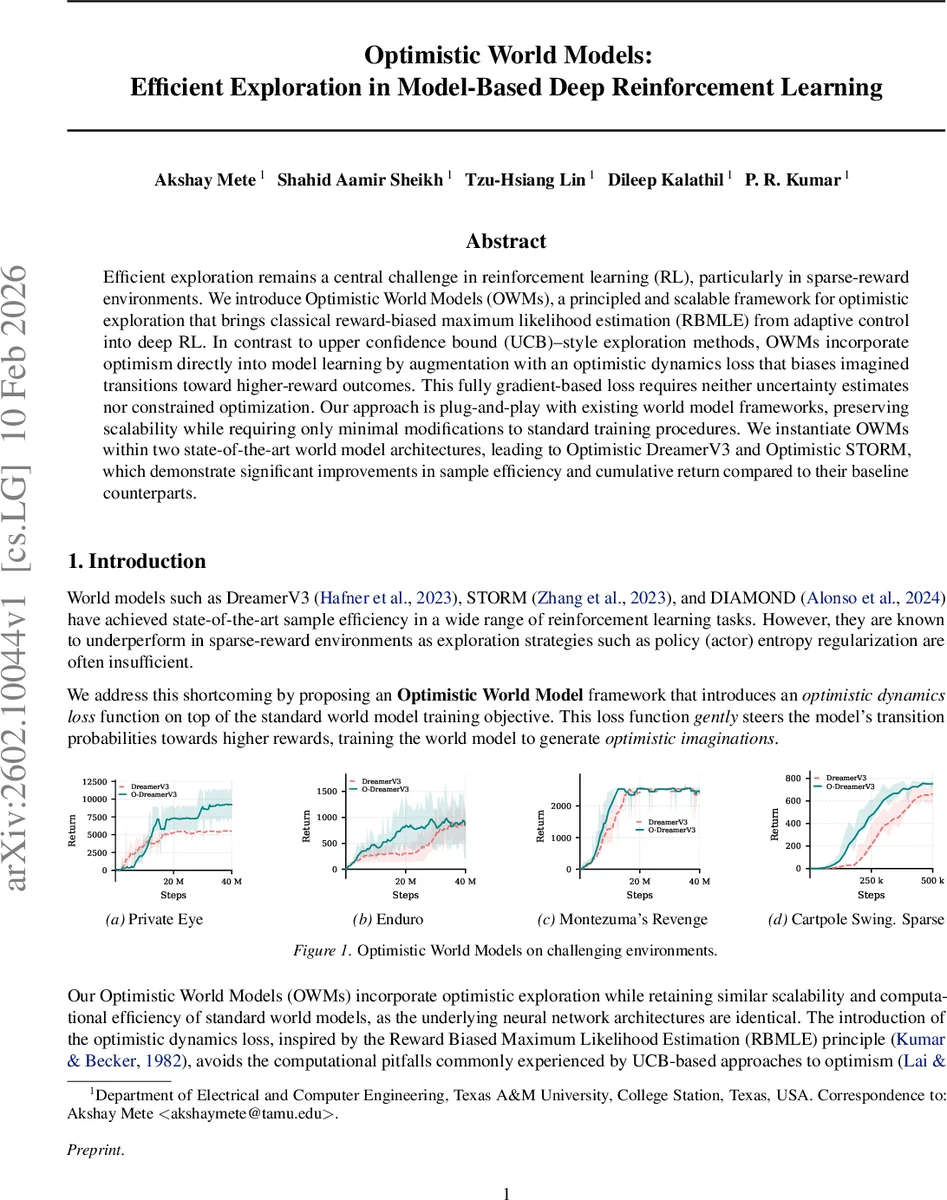
Efficient exploration remains a central challenge in reinforcement learning (RL), particularly in sparse-reward environments. We introduce Optimistic World Models (OWMs), a principled and scalable framework for optimistic exploration that brings classical reward-biased maximum likelihood estimation (RBMLE) from adaptive control into deep RL. In contrast to upper confidence bound (UCB)-style exploration methods, OWMs incorporate optimism directly into model learning by augmentation with an optimistic dynamics loss that biases imagined transitions toward higher-reward outcomes. This fully gradient-based loss requires neither uncertainty estimates nor constrained optimization. Our approach is plug-and-play with existing world model frameworks, preserving scalability while requiring only minimal modifications to standard training procedures. We instantiate OWMs within two state-of-the-art world model architectures, leading to Optimistic DreamerV3 and Optimistic STORM, which demonstrate significant improvements in sample efficiency and cumulative return compared to their baseline counterparts.
💡 Research Summary
The paper tackles the long‑standing challenge of efficient exploration in reinforcement learning, especially in sparse‑reward settings, by introducing a novel framework called Optimistic World Models (OWM). OWM brings the classical reward‑biased maximum likelihood estimation (RBMLE) from adaptive control into deep model‑based reinforcement learning (MBRL). Unlike conventional upper‑confidence‑bound (UCB) approaches that require explicit uncertainty quantification and often involve non‑convex constrained optimization, OWM embeds optimism directly into the model learning process through an additional “optimistic dynamics loss”. This loss nudges the learned transition distribution toward outcomes that yield higher cumulative reward, effectively biasing imagined rollouts to be more optimistic.
The authors first revisit the certainty‑equivalence principle, which underlies many MBRL algorithms: the agent fits a dynamics model to real data via maximum likelihood, then optimizes a policy on the fitted model. They point out that, without the strong identifiability condition, this procedure can converge to a self‑consistent but sub‑optimal closed‑loop model and policy—a phenomenon known as the closed‑loop identification problem. RBMLE resolves this by augmenting the log‑likelihood with a weighted expected return term α(t)·J(p,π), where α(t) diminishes over time but grows fast enough (t·α(t)→∞) to guarantee eventual convergence to the true dynamics while still encouraging optimism early on.
To make RBMLE practical for deep networks, the paper derives gradient‑based estimators for both the model parameters ϕ and the policy parameters θ. The standard log‑likelihood term is computed on the replay buffer Dₜ as usual. For the optimism term, the current policy π_θ is rolled out in the learned model p_ϕ to generate N imagined trajectories τ_i. Using the log‑derivative trick, the gradient of the expected return with respect to ϕ is expressed as an expectation over imagined transitions weighted by the trajectory return R(τ_i). This leads to the “optimistic dynamics loss”:
L_optₜ = –α(t)·(1/L)∑{ℓ=1}^L A_ℓ log p_ϕ(s{ℓ+1}|s_ℓ,a_ℓ) – η·(1/L)∑_{ℓ=0}^L H(p_ϕ(·|s_ℓ,a_ℓ)),
where A_ℓ is an advantage estimate derived from a critic, and H denotes entropy regularization. The loss mirrors the standard actor loss, requiring only a substitution of the policy log‑probability with the dynamics log‑probability. Consequently, OWM can be plugged into any imagination‑based world‑model pipeline with minimal code changes.
The framework is instantiated in two state‑of‑the‑art world‑model algorithms: DreamerV3 and STORM. The resulting Optimistic DreamerV3 (O‑DreamerV3) and Optimistic STORM (O‑STORM) retain all original components (encoder, decoder, latent dynamics, reward predictor, critic) and differ only by the addition of L_opt during model training.
Empirical evaluation spans Atari100K, the DeepMind Control Suite (DMC), and several deliberately sparse‑reward environments such as Private Eye, Cartpole Swing‑up Sparse, and Acrobot Swing‑up Sparse. Key findings include:
- O‑DreamerV3 achieves a mean human‑normalized score (HNS) of 152.68 % on Atari100K, a 55 % improvement over the baseline DreamerV3 (97.45 %).
- Both O‑DreamerV3 and O‑STORM show markedly faster early‑stage learning, discovering rewarding states that baseline methods miss for thousands of environment steps.
- The computational overhead is negligible; training time and memory usage remain comparable to the original algorithms because no ensemble, Gaussian‑process, or explicit uncertainty estimator is required.
- Ablation studies confirm that the optimism coefficient α(t) and the advantage‑weighted term are essential for the observed gains, while the entropy regularizer prevents collapse of the dynamics distribution.
The paper’s contributions are threefold: (1) a fully gradient‑based implementation of RBMLE for deep MBRL, (2) a plug‑and‑play optimistic dynamics loss that introduces principled optimism without extra architectural complexity, and (3) strong empirical evidence that this approach substantially improves sample efficiency in both sparse‑ and dense‑reward domains.
In summary, Optimistic World Models provide a theoretically grounded yet practically simple mechanism to inject optimism into model‑based RL. By biasing the learned dynamics toward high‑reward imagined outcomes, OWM resolves the closed‑loop identification problem, accelerates exploration, and preserves the scalability of modern world‑model architectures. Future directions include learning the optimism schedule α(t) via meta‑learning, extending the method to multi‑objective settings, and integrating it with recent advances in latent‑space planning and hierarchical RL.
Comments & Academic Discussion
Loading comments...
Leave a Comment