A Unified Assessment of the Poverty of the Stimulus Argument for Neural Language Models
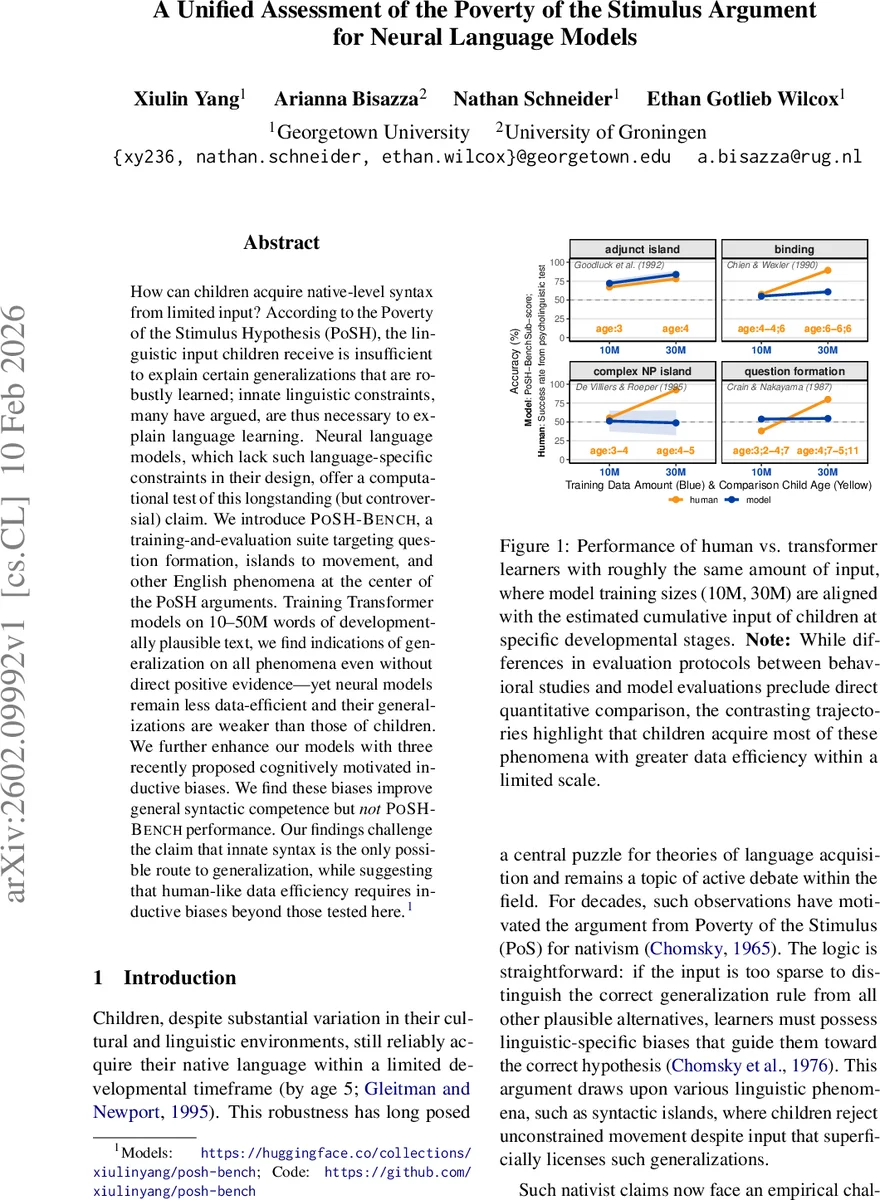
How can children acquire native-level syntax from limited input? According to the Poverty of the Stimulus Hypothesis (PoSH), the linguistic input children receive is insufficient to explain certain generalizations that are robustly learned; innate linguistic constraints, many have argued, are thus necessary to explain language learning. Neural language models, which lack such language-specific constraints in their design, offer a computational test of this longstanding (but controversial) claim. We introduce \poshbench, a training-and-evaluation suite targeting question formation, islands to movement, and other English phenomena at the center of the PoSH arguments. Training Transformer models on 10–50M words of developmentally plausible text, we find indications of generalization on all phenomena even without direct positive evidence – yet neural models remain less data-efficient and their generalizations are weaker than those of children. We further enhance our models with three recently proposed cognitively motivated inductive biases. We find these biases improve general syntactic competence but not \poshbench performance. Our findings challenge the claim that innate syntax is the only possible route to generalization, while suggesting that human-like data efficiency requires inductive biases beyond those tested here.
💡 Research Summary
The paper tackles the classic Poverty of the Stimulus (PoS) argument, which claims that children must possess innate linguistic constraints because the linguistic input they receive is too sparse to uniquely determine the correct grammatical generalizations. To test this claim computationally, the authors introduce POSH‑Bench, a targeted evaluation suite that probes four canonical PoS phenomena in English: (1) yes/no question formation (main‑auxiliary movement), (2) island constraints (complex NP, wh‑clause, adjunct islands), (3) Principle A of Binding Theory, and (4) the “wanna” contraction restriction. Each phenomenon is broken down into ten minimal‑pair test items, mirroring the stimuli used in developmental psycholinguistic studies.
The experimental setup is carefully aligned with child language exposure. The authors train standard Transformer language models on three sizes of developmentally plausible corpora—10 M, 30 M, and 50 M words—derived from child‑directed speech. Crucially, they manipulate the presence of direct positive evidence (e.g., sentences containing multiple auxiliaries that would explicitly teach the hierarchical rule for question formation) to create conditions where the stimulus is truly impoverished. Model performance is then compared against human success rates extracted from the literature, allowing a direct data‑efficiency comparison.
Results show that even without any direct positive evidence, the models achieve above‑chance accuracy on all four phenomena, indicating that indirect statistical cues in the input are richer than traditionally assumed by PoS proponents. However, a substantial gap remains: children acquire near‑adult performance with far fewer words, whereas the models require the full 30–50 M word range and still lag behind (e.g., ~60 % accuracy on question formation versus >90 % in children). This demonstrates that while distributional learning can produce some of the required generalizations, it is far less data‑efficient than human learners.
To probe whether specific inductive biases could bridge this gap, the authors augment the base models with three cognitively motivated biases: (i) a structural attention mechanism that explicitly encodes tree‑like dependencies, (ii) multi‑task training with syntactic parse labels, and (iii) a domain‑general meta‑learning framework that encourages rapid adaptation to small data. These biases improve overall syntactic competence on broad benchmarks (e.g., BLiMP, Zorro) but do not yield significant gains on the POSH‑Bench items. In other words, the biases help models learn generic grammar but do not make them more sensitive to the sparse, indirect evidence that characterizes PoS phenomena.
The paper situates its contribution relative to the BabyLM and related challenges, noting that prior work either used data scales outside the 10–50 M window or evaluated on broad linguistic benchmarks that do not isolate PoS cases. By providing a unified framework that matches child‑scale input, manipulates evidence availability, and targets canonical PoS tests, the study offers a more stringent empirical probe of the PoS argument.
Limitations are acknowledged: only textual input is used, ignoring the multimodal richness of children’s language environments; the study is limited to English, so cross‑linguistic generalization remains open; and the three tested biases may not capture the full range of innate constraints hypothesized by nativist theories.
In sum, the findings challenge the strong claim that innate syntax is the sole route to acquiring these grammatical constraints. Transformers can learn them from limited input, but they do so far less efficiently than children, and the specific inductive biases examined do not close the efficiency gap. This suggests that human‑like language acquisition likely relies on additional, perhaps more language‑specific, innate mechanisms beyond the distributional learning and structural biases currently explored.
Comments & Academic Discussion
Loading comments...
Leave a Comment