ARO: A New Lens On Matrix Optimization For Large Models
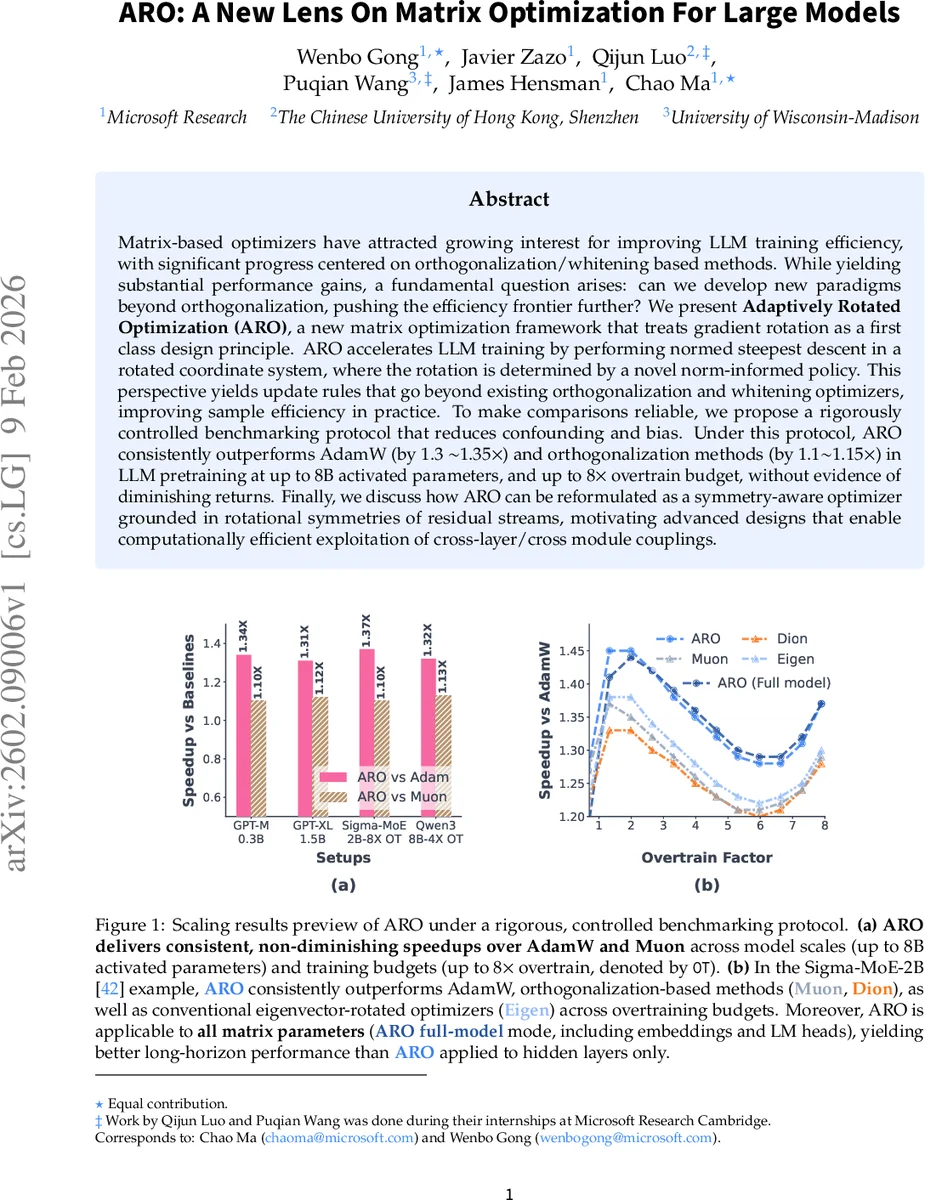
Matrix-based optimizers have attracted growing interest for improving LLM training efficiency, with significant progress centered on orthogonalization/whitening based methods. While yielding substantial performance gains, a fundamental question arises: can we develop new paradigms beyond orthogonalization, pushing the efficiency frontier further? We present \textbf{Adaptively Rotated Optimization (ARO}, a new matrix optimization framework that treats gradient rotation as a first class design principle. ARO accelerates LLM training by performing normed steepest descent in a rotated coordinate system, where the rotation is determined by a novel norm-informed policy. This perspective yields update rules that go beyond existing orthogonalization and whitening optimizers, improving sample efficiency in practice. To make comparisons reliable, we propose a rigorously controlled benchmarking protocol that reduces confounding and bias. Under this protocol, ARO consistently outperforms AdamW (by 1.3 $\sim$1.35$\times$) and orthogonalization methods (by 1.1$\sim$1.15$\times$) in LLM pretraining at up to 8B activated parameters, and up to $8\times$ overtrain budget, without evidence of diminishing returns. Finally, we discuss how ARO can be reformulated as a symmetry-aware optimizer grounded in rotational symmetries of residual streams, motivating advanced designs that enable computationally efficient exploitation of cross-layer/cross module couplings.
💡 Research Summary
Paper Overview
The manuscript introduces Adaptively Rotated Optimization (ARO), a novel matrix‑based optimizer for large language model (LLM) training. Unlike prior work that relies on orthogonalization or whitening of gradient matrices, ARO treats gradient rotation itself as a first‑class design principle. The core idea is to perform norm‑scaled steepest descent in a rotated coordinate system and then map the update back to the original parameter space. The rotation matrix is not fixed to eigenvectors of G Gᵀ or singular vectors of G; instead, it is generated by a norm‑informed policy that directly optimizes the instantaneous loss‑decrease rate of the underlying base optimizer (e.g., Adam, SignGD, row‑normalized GD).
Technical Contributions
-
Unified Rotated‑Steepest‑Descent Framework – The authors show that many existing matrix optimizers (SO‑AP, Muon, SPlus, Shampoo variants) can be expressed as
ΔWₜ ∝ –η Rₜ fₜ(Rₜᵀ Gₜ)
where Rₜ is a rotation matrix and fₜ is a base optimizer. This formulation isolates the rotation from the projection step, revealing that most empirical gains stem from the rotation itself. -
Adaptive Rotation Policy – ARO defines Rₜ as the solution of a constrained optimization problem that simultaneously minimizes the norm of the rotated gradient (‖Rₜᵀ Gₜ‖) and maximizes the magnitude of the projected update (‖fₜ(Rₜᵀ Gₜ)‖). The policy is implemented via a Shifted Cholesky QR routine, which yields a fast, numerically stable orthogonal factor Q that serves as Rₜ. This avoids costly eigen‑decompositions while still producing a high‑quality rotation.
-
SinkGD – A New Base Optimizer – To complement the rotation, the authors propose SinkGD, a variant of Adam that retains momentum and adaptive scaling but adapts the step size in the rotated space based on the norm of the rotated gradient. SinkGD is shown to be more robust to aggressive rotations than vanilla Adam.
-
Full‑Model Applicability – ARO is applied uniformly to all matrix‑valued parameters, including embeddings and LM heads, which are traditionally left to AdamW. This “full‑model” mode demonstrates that a single update rule can replace the hybrid pipelines used in prior work.
-
Controlled Benchmarking Protocol – Recognizing that many reported speed‑ups are confounded by hyper‑parameter tuning, the authors design a rigorous protocol: identical data pipelines, token budgets, learning‑rate schedules, and exhaustive hyper‑parameter sweeps for every method. This protocol isolates the algorithmic contribution from tuning artifacts.
-
Symmetry‑Teleportation Theory – The paper hypothesizes that LLM residual streams possess rotational symmetries (e.g., swapping orthogonal bases in linear layers leaves the network function unchanged). ARO’s rotation can be interpreted as a symmetry teleportation step that moves the optimizer along these symmetry manifolds, effectively “skipping” flat directions without explicit second‑order information.
Experimental Findings
- GPT‑2‑XL (1.5 B): Under the controlled protocol, ARO achieves a 1.34× reduction in wall‑clock time to reach a target perplexity compared with AdamW, and a 1.12× gain over Muon.
- Sigma‑MoE‑2 B: In a mixture‑of‑experts setting, ARO applied in full‑model mode outperforms both eigen‑rotation methods (Muon, Dion) and a recent eigen‑vector optimizer (Eigen) across a range of over‑training factors (1× to 8×).
- Qwen‑3‑8 B: Scaling experiments up to 8 B activated parameters and 8× over‑training budget show consistent 1.30–1.35× speed‑ups, with no sign of diminishing returns.
- Stability‑Speed Trade‑off: Ablation studies (Section 5.3) reveal that the rotation policy has a larger impact on sample efficiency than the choice of base optimizer. Aggressive rotations improve convergence speed but can destabilize training; SinkGD mitigates this by adapting step sizes.
Practical Implementation
The authors integrate ARO with two major distributed training frameworks:
- FSDP2 (PyTorch) – Parameters are sharded; each shard computes its local QR factor, reducing communication overhead.
- Megatron‑LM – Model‑parallelism is preserved; rotation matrices are computed per tensor parallel slice.
Nevertheless, the per‑step cost of QR decomposition remains O(m²n) for an m × n weight matrix, which can be non‑trivial for very large layers. The paper reports modest memory overhead (≈ 5 % extra) and demonstrates that the overall wall‑clock savings outweigh this cost for models up to 8 B parameters.
Limitations & Open Questions
- Scalability to Multi‑Billion‑Parameter Models – While 8 B experiments are promising, the QR step may become a bottleneck for 30 B+ models. Future work could explore low‑rank approximations or stochastic QR updates.
- Robustness to Non‑Standard Objectives – The current norm‑informed policy is derived under standard cross‑entropy loss. Its behavior under reinforcement‑learning‑from‑human‑feedback (RLHF) or contrastive objectives remains unexplored.
- Hyper‑parameter Sensitivity – Although the benchmarking protocol standardizes tuning, ARO introduces new knobs (e.g., QR shift magnitude, SinkGD damping). Sensitivity analyses suggest modest impact, but broader validation across diverse datasets would strengthen claims.
- Theoretical Guarantees – The symmetry‑teleportation argument is compelling but informal. Formal convergence proofs under realistic stochastic gradients would be valuable.
Impact & Future Directions
ARO reframes matrix‑based optimization as rotated steepest descent, shifting the research focus from “which norm to whiten” to “how to rotate gradients adaptively”. This opens a large design space: alternative rotation policies (e.g., learned via meta‑optimization), hybrid schemes that combine low‑rank second‑order information with rotation, and extensions to other modalities (vision transformers, diffusion models). Moreover, the symmetry perspective may inspire new regularization techniques that explicitly enforce or exploit rotational invariances in deep networks.
In summary, the paper delivers a well‑motivated, theoretically grounded, and empirically validated optimizer that pushes LLM training efficiency beyond the current orthogonalization frontier. Its contributions are likely to influence both the design of next‑generation optimizers and the methodology of fair, controlled benchmarking in large‑scale deep learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment