MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm
We introduce MonkeyOCR, a document parsing model that advances the state of the art by leveraging a Structure-Recognition-Relation (SRR) triplet paradigm. This design simplifies what would otherwise be a complex multi-tool pipeline and avoids the inefficiencies of processing full pages with giant end-to-end models. In SRR, document parsing is abstracted into three fundamental questions - Where is it?'' (structure), What is it?’’ (recognition), and ``How is it organized?’’ (relation) - corresponding to structure detection, content recognition, and relation prediction. To support this paradigm, we present MonkeyDoc, a comprehensive dataset with 4.5 million bilingual instances spanning over ten document types, which addresses the limitations of existing datasets that often focus on a single task, language, or document type. Leveraging the SRR paradigm and MonkeyDoc, we trained a 3B-parameter document foundation model. We further identify parameter redundancy in this model and propose contiguous parameter degradation (CPD), enabling the construction of models from 0.6B to 1.2B parameters that run faster with acceptable performance drop. MonkeyOCR achieves state-of-the-art performance, surpassing previous open-source and closed-source methods, including Gemini 2.5-Pro. Additionally, the model can be efficiently deployed for inference on a single RTX 3090 GPU. Code and models will be released at https://github.com/Yuliang-Liu/MonkeyOCR.
💡 Research Summary
MonkeyOCR introduces a novel “Structure‑Recognition‑Relation” (SRR) paradigm that reframes document parsing as three fundamental questions: “Where is it?” (structure detection), “What is it?” (content recognition), and “How is it organized?” (relation prediction). By decomposing the task into these three stages, the authors replace the cumbersome multi‑tool pipelines that suffer from cumulative error propagation with a streamlined three‑model system, while also avoiding the inefficiencies of processing whole‑page images with massive end‑to‑end models.
To support SRR, the authors built MonkeyDoc, a large‑scale bilingual dataset containing 4.5 million instances across more than ten document types (financial reports, textbooks, academic papers, legal documents, etc.) and covering five parsing tasks: layout detection, reading order prediction, text recognition, table recognition, and formula recognition. MonkeyDoc combines manually curated annotations, programmatic synthesis, and LLM‑driven automatic labeling, providing both English and Chinese samples and ensuring a diverse, high‑quality training corpus.
Using MonkeyDoc, a 3 billion‑parameter multimodal foundation model was trained. The model consists of three components: a DETR‑based structure detector that predicts bounding boxes and categories; a content recognizer that crops each detected block, encodes it into visual tokens, and feeds the tokens together with a task‑specific prompt into a large language model (LLM) to generate text, LaTeX, or table markup; and a relation predictor that embeds block coordinates, passes them through transformer layers, and classifies the reading order among blocks. This block‑level parallel processing dramatically reduces sequence length, cutting the quadratic attention cost and eliminating the hallucination problems typical of long‑context end‑to‑end models.
The authors also observed substantial parameter redundancy in the 3 B model. They propose Contiguous Parameter Degradation (CPD), a systematic method that skips contiguous layers in the transformer stack to create lighter models ranging from 0.6 B to 1.2 B parameters. CPD preserves the input‑output dimensionality of each block, so performance loss is minimal: text recognition remains virtually unchanged, while more complex tasks such as table recognition see only a 1‑2 % drop, but inference speed improves by up to 34 %.
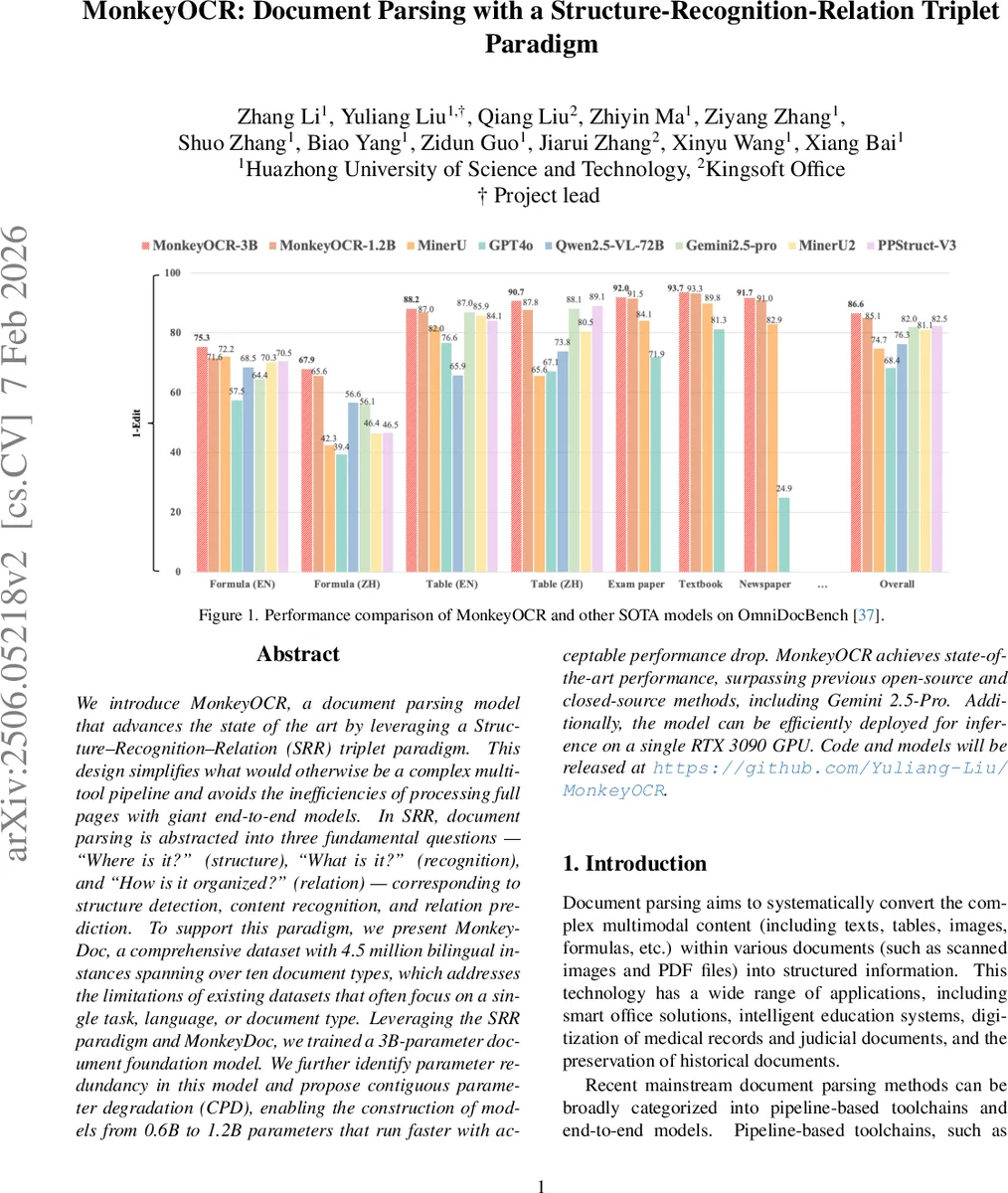
Extensive evaluation on OmniDocBench and internal test sets shows that MonkeyOCR outperforms the best open‑source pipeline (PPStruct‑V3) by 4.1 % in overall F1, surpasses the large multimodal model Qwen2.5‑VL‑72B, and exceeds the closed‑source Gemini 2.5‑Pro. It achieves a 2.09× speedup over the end‑to‑end baseline and can run in real‑time on a single RTX 3090 GPU (3 B model) or with a 34 % speed gain at only 1.5 % accuracy loss (1.2 B model).
In summary, MonkeyOCR delivers a practical, high‑performance solution for document understanding by (1) redefining the problem with the SRR triplet, (2) providing a comprehensive bilingual dataset, (3) training a robust multimodal foundation model, and (4) introducing CPD for scalable deployment. The code and models are released publicly, paving the way for broader adoption in smart office automation, educational technology, medical record digitization, and historical document preservation.
Comments & Academic Discussion
Loading comments...
Leave a Comment