ScaleBITS: Scalable Bitwidth Search for Hardware-Aligned Mixed-Precision LLMs
Post-training weight quantization is crucial for reducing the memory and inference cost of large language models (LLMs), yet pushing the average precision below 4 bits remains challenging due to highly non-uniform weight sensitivity and the lack of principled precision allocation. Existing solutions use irregular fine-grained mixed-precision with high runtime overhead or rely on heuristics or highly constrained precision allocation strategies. In this work, we propose ScaleBITS, a mixed-precision quantization framework that enables automated, fine-grained bitwidth allocation under a memory budget while preserving hardware efficiency. Guided by a new sensitivity analysis, we introduce a hardware-aligned, block-wise weight partitioning scheme, powered by bi-directional channel reordering. We formulate global bitwidth allocation as a constrained optimization problem and develop a scalable approximation to the greedy algorithm, enabling end-to-end principled allocation. Experiments show that ScaleBITS significantly improves over uniform-precision quantization (up to +36%) and outperforms state-of-the-art sensitivity-aware baselines (up to +13%) in ultra-low-bit regime, without adding runtime overhead.
💡 Research Summary
ScaleBITS addresses the long‑standing challenge of quantizing large language models (LLMs) to ultra‑low bit‑widths (≤ 4 bits) while preserving model quality and maintaining hardware efficiency. The authors identify two fundamental obstacles: (1) weight sensitivity is highly non‑uniform, with a small subset of weights disproportionately affecting performance, and (2) existing mixed‑precision schemes either operate at a coarse granularity (e.g., layer‑wise) that cannot capture this heterogeneity, or at a fine granularity (e.g., element‑wise) that incurs prohibitive metadata, control‑flow, and memory‑access overheads.
The proposed framework, ScaleBITS, introduces three key innovations. First, a progressive‑quantization sensitivity estimator computes the importance of each weight component by expanding the loss around the currently quantized model rather than the full‑precision model. This first‑order Taylor approximation uses gradients ∇L(w_Q) evaluated on the partially quantized network, yielding a reliable ranking of sensitivities even when the model is far from a local optimum. Empirical validation shows that this estimator preserves the correct ordering of layer‑wise sensitivities, whereas traditional full‑precision‑based metrics fail.
Second, the authors discover a bi‑directional structural pattern: highly sensitive weights cluster in a few rows and columns of each weight matrix. Exploiting this, they apply a bi‑directional channel reordering that simultaneously permutes output (row) and input (column) channels, concentrating sensitive weights into contiguous blocks. These blocks are then partitioned into hardware‑aligned tiles (e.g., 64 × 64 or 128 × 128). Because each tile is processed with a uniform bit‑width, the scheme maps directly onto existing matrix‑multiplication kernels without extra indexing or irregular sparsity, preserving runtime regularity.
Third, ScaleBITS formulates the global bit‑width allocation under a memory budget B as an integer optimization problem: minimize the loss of the quantized model subject to Σ_i b_i ≤ B, where b_i denotes the bit‑width of tile i. Under mild monotonicity assumptions the objective becomes a monotone submodular function over the integer lattice, a classic NP‑hard knapsack problem with a known (1 − 1/e) greedy approximation guarantee. Direct greedy search is infeasible at LLM scale (O(N²) forward passes). The authors therefore develop a scalable greedy approximation that leverages the sensitivity estimates to approximate marginal loss reductions. By sorting tiles according to their estimated gain per additional bit, the algorithm achieves an O(N log N) runtime while preserving the essential decision structure of the exact greedy method.
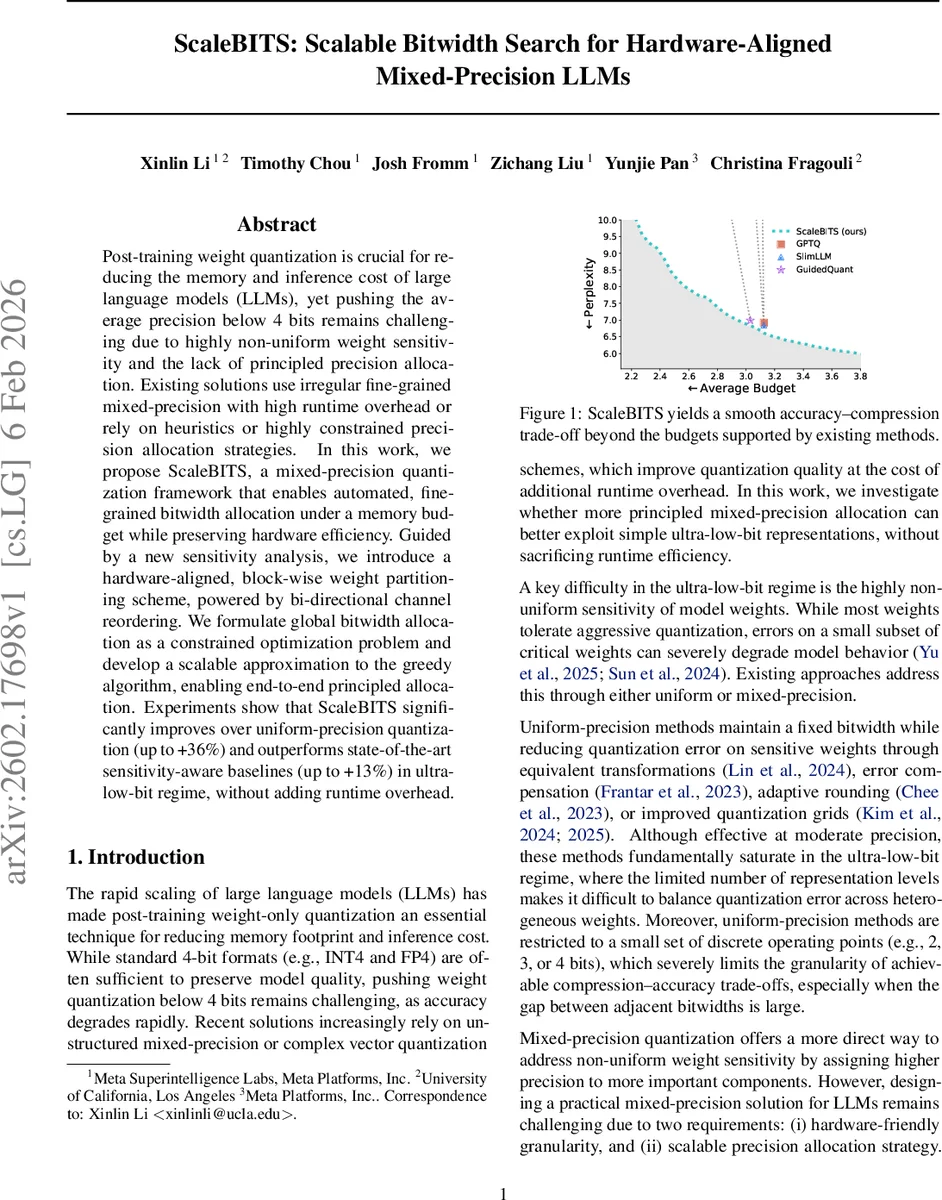
Experiments on models such as Gemma‑2‑9B, LLaMA‑2‑7B, and GPT‑NeoX demonstrate that ScaleBITS consistently outperforms uniform‑precision baselines (up to +36% lower perplexity) and state‑of‑the‑art sensitivity‑aware mixed‑precision methods (up to +13% improvement) in the ultra‑low‑bit regime (2–3 bits). The block‑wise allocation enables a smooth Pareto frontier that reaches operating points unattainable by prior techniques. Importantly, because the partitions align with hardware kernels, the inference latency remains unchanged; the reported overhead is effectively zero.
The paper also discusses limitations: it currently quantizes weights only, leaving activation quantization for future work; block size and reordering strategies may need model‑specific tuning; and extending the approach to include binary or higher‑precision (e.g., 8‑bit) components could further broaden its applicability.
In summary, ScaleBITS delivers a principled, end‑to‑end solution for ultra‑low‑bit LLM quantization by (1) using a quantization‑centric sensitivity metric, (2) clustering sensitive weights via bi‑directional channel reordering into hardware‑friendly blocks, and (3) allocating bits efficiently with a scalable greedy approximation. This combination achieves superior accuracy‑memory trade‑offs without sacrificing inference speed, setting a new benchmark for practical mixed‑precision quantization of large language models.
Comments & Academic Discussion
Loading comments...
Leave a Comment