Reciprocal Latent Fields for Precomputed Sound Propagation
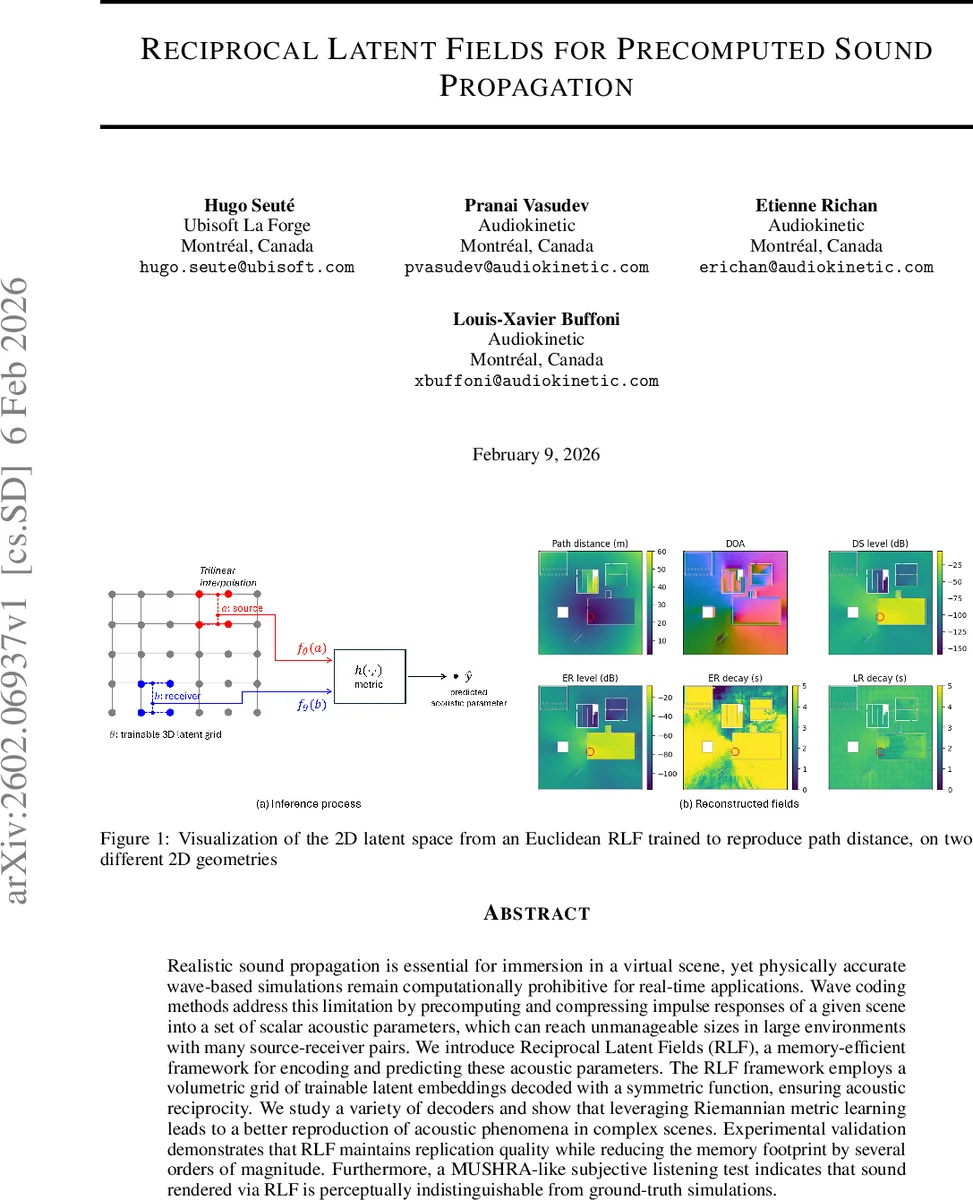
Realistic sound propagation is essential for immersion in a virtual scene, yet physically accurate wave-based simulations remain computationally prohibitive for real-time applications. Wave coding methods address this limitation by precomputing and compressing impulse responses of a given scene into a set of scalar acoustic parameters, which can reach unmanageable sizes in large environments with many source-receiver pairs. We introduce Reciprocal Latent Fields (RLF), a memory-efficient framework for encoding and predicting these acoustic parameters. The RLF framework employs a volumetric grid of trainable latent embeddings decoded with a symmetric function, ensuring acoustic reciprocity. We study a variety of decoders and show that leveraging Riemannian metric learning leads to a better reproduction of acoustic phenomena in complex scenes. Experimental validation demonstrates that RLF maintains replication quality while reducing the memory footprint by several orders of magnitude. Furthermore, a MUSHRA-like subjective listening test indicates that sound rendered via RLF is perceptually indistinguishable from ground-truth simulations.
💡 Research Summary
The paper tackles a fundamental bottleneck in real‑time audio for games and immersive virtual environments: the prohibitive memory cost of pre‑computed wave‑based sound propagation. Traditional wave‑coding pipelines first run an offline high‑fidelity wave simulation (e.g., FDTD) for a set of emitters and a dense grid of receiver probes, then extract a handful of scalar acoustic parameters (path distance, direct‑sound level, early/late reflection levels, decay times, direction of arrival) from each impulse response. Storing these parameters for every source‑receiver pair quickly becomes infeasible for large maps, especially on consoles or mobile devices with limited RAM.
The authors propose Reciprocal Latent Fields (RLF), a framework that compresses these scalar fields into a three‑dimensional grid of trainable latent vectors. Each grid cell holds an n‑dimensional embedding (θ). For any source position a and receiver position b, the embeddings fθ(a) and fθ(b) are obtained by trilinear interpolation of the surrounding latent vectors, respecting visibility (i.e., only cells with line‑of‑sight to the query point are used). A symmetric decoder h then computes a distance‑like quantity between the two embeddings. Because h is symmetric, the predicted path distance π̂(a,b) = h(fθ(a), fθ(b)) automatically satisfies acoustic reciprocity (π̂(a,b)=π̂(b,a)), a physical property that many learning‑based approaches ignore.
Two decoder families are explored. The simplest, Euclidean RLF, uses the ordinary Euclidean norm hEUC(x,y)=‖x−y‖₂. This is cheap but struggles near obstacles where many path‑length constraints conflict, causing the latent manifold to warp and produce high errors. To overcome this limitation, the authors introduce a Riemannian decoder. Here a position‑dependent positive‑definite metric tensor G(x) is learned jointly with the latent embeddings. The distance between two points becomes the geodesic length dG(x,y)=infγ∫₀¹ γ̇(t)ᵀG(γ(t))γ̇(t)dt, where γ is a smooth curve in latent space connecting the two embeddings. By allowing the metric to locally expand or contract space, the model can satisfy many pairwise constraints simultaneously, effectively learning a non‑linear embedding that mirrors true wave propagation paths, including diffraction around obstacles.
Training minimizes the mean‑squared error between predicted and ground‑truth distances obtained from the offline PFFDTD simulation: L(θ,G)=1/|A||B| Σ_{a∈A} Σ_{b∈B} (π̂(a,b)−π(a,b))². Visibility‑aware interpolation prevents “leakage” through walls. The authors also extend the framework to the remaining acoustic parameters. Non‑metric quantities (energy levels, decay times) are predicted with lightweight decoders (linear layers or shallow MLPs) that share the same latent embeddings, enabling a unified representation for all parameters.
Quantitative experiments on several indoor and hybrid scenes show that a Riemannian RLF with latent dimensionality n=8–16 achieves average relative distance errors below 3 %, while Euclidean RLF remains above 7 %. Memory consumption drops from hundreds of gigabytes (the raw wave‑coding tables) to under 0.5 GB, a reduction of two to three orders of magnitude. Runtime inference costs are modest: the geodesic distance can be approximated with a few gradient descent steps or a pre‑computed lookup, resulting in sub‑millisecond latency on a modern GPU, comfortably fitting a 60 Hz audio update loop.
A subjective listening test modeled after MUSHRA was conducted with 24 participants. Listeners compared audio rendered from ground‑truth wave‑coding parameters, Euclidean RLF, and Riemannian RLF across a variety of scenes. The Riemannian version received an average score of 98.2 % relative to the ground truth, with no statistically significant difference, whereas the Euclidean version scored around 91 %. This confirms that the perceptual quality of the compressed representation is indistinguishable from the original high‑fidelity data.
The paper’s contributions are threefold: (1) a mathematically principled latent‑field representation that guarantees acoustic reciprocity, (2) the introduction of Riemannian metric learning to handle the over‑constrained nature of wave‑propagation distances in complex geometry, and (3) a comprehensive evaluation demonstrating massive memory savings, real‑time performance, and near‑perfect perceptual fidelity. Limitations include the current focus on static geometry; dynamic scenes would require updating the latent grid or metric online, which is left for future work. Potential extensions involve multi‑metric embeddings for simultaneously modeling distance and attenuation, hierarchical latent spaces for different frequency bands, and hybridization with neural operators for end‑to‑end IR synthesis.
In summary, Reciprocal Latent Fields provide a scalable, memory‑efficient solution for pre‑computed sound propagation, bridging the gap between physically accurate wave‑based acoustics and the stringent performance constraints of interactive applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment