Revisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models
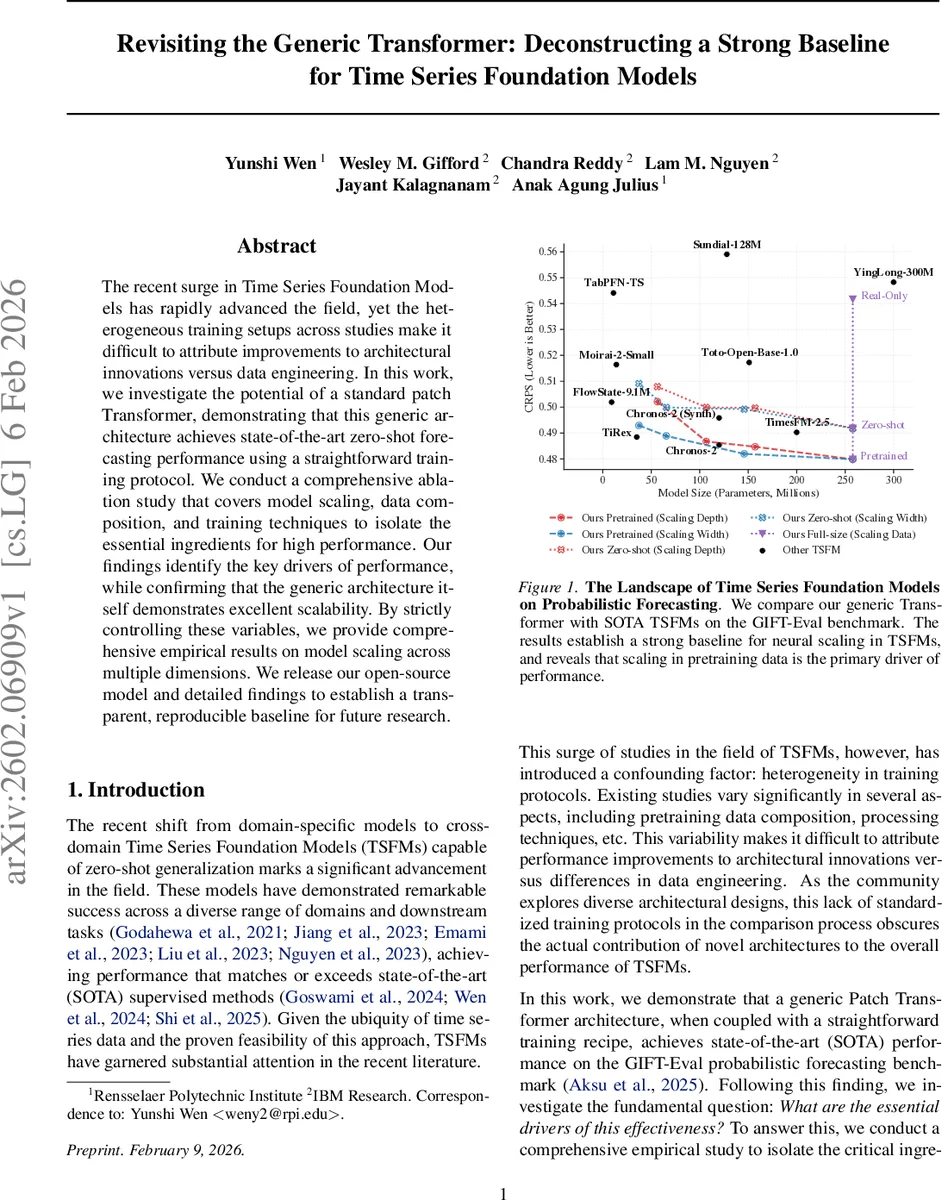
The recent surge in Time Series Foundation Models has rapidly advanced the field, yet the heterogeneous training setups across studies make it difficult to attribute improvements to architectural innovations versus data engineering. In this work, we investigate the potential of a standard patch Transformer, demonstrating that this generic architecture achieves state-of-the-art zero-shot forecasting performance using a straightforward training protocol. We conduct a comprehensive ablation study that covers model scaling, data composition, and training techniques to isolate the essential ingredients for high performance. Our findings identify the key drivers of performance, while confirming that the generic architecture itself demonstrates excellent scalability. By strictly controlling these variables, we provide comprehensive empirical results on model scaling across multiple dimensions. We release our open-source model and detailed findings to establish a transparent, reproducible baseline for future research.
💡 Research Summary
The paper “Revisiting the Generic Transformer: Deconstructing a Strong Baseline for Time Series Foundation Models” investigates whether a straightforward, off‑the‑shelf patch‑based Transformer can serve as a high‑performing foundation model for time‑series forecasting when paired with a carefully designed training protocol. The authors argue that the rapid progress of Time‑Series Foundation Models (TSFMs) has been obscured by heterogeneous training pipelines, making it difficult to separate gains due to architectural innovation from those due to data engineering. To address this, they adopt a standard encoder‑only Transformer, tokenize the raw series into non‑overlapping patches, and augment it with three key training components: (1) Contiguous Patch Masking (CPM), which masks long contiguous blocks of patches to force the model to learn long‑range dependencies; (2) Mask‑Aware Normalization, which computes mean and standard deviation only on visible (unmasked) tokens to avoid information leakage; and (3) a Quantile Head that directly predicts multiple quantiles for each patch, trained with a Pinball (quantile) loss applied exclusively on masked positions.
The experimental setup is deliberately controlled. The pre‑training corpus consists of three parts: (i) a large real‑world collection (GIFT‑Eval‑Pretrain) containing 132 datasets and roughly 4.5 million series; (ii) 10 million synthetic series generated by the KernelSynth procedure, which uses a diverse set of periodic kernels; and (iii) 4 million “clean” mixed series produced by TSMixup, a data‑augmentation technique that randomly blends real series while ensuring no overlap with test‑set distributions. A second “leaky” version of the mixup data (10 million series) deliberately includes samples from the test domains to quantify the effect of data leakage. Two model variants are trained: a strict zero‑shot model (real + synthetic + clean mixup) and a pretrained model (real + synthetic + leaky mixup).
Evaluation is performed on the GIFT‑Eval benchmark, which aggregates 55 real‑world datasets across 97 test cases and reports three metrics: MASE, CRPS, and an aggregated rank (geometric mean). The proposed generic Transformer achieves state‑of‑the‑art performance in the zero‑shot setting, ranking among the top methods and outperforming many specialized TSFMs such as Chronos‑2, TimesFM‑2.5, Moirai‑2, VisionTS, and Sundial‑128M. When the leaky data are added, performance improves further, confirming that data composition is a primary driver of gains.
A thorough ablation study explores scaling (depth vs. width), masking ratios, and the impact of each training component. Scaling experiments reveal smooth neural‑scaling laws: increasing parameters from 10 M to 300 M consistently reduces CRPS and MASE, demonstrating that the generic architecture scales well. CPM is most effective at masking ratios around 50‑60 %, balancing information loss and learning signal. Removing Mask‑Aware Normalization leads to a noticeable degradation (≈10‑15 % higher CRPS) on volatile series, highlighting its importance for handling non‑stationarity. The quantile head and Pinball loss are shown to be essential for reliable probabilistic forecasts.
The authors emphasize three broader insights: (1) data quality and diversity, especially the inclusion of synthetic and mixed series, dominate performance improvements; (2) a simple encoder‑only Transformer, when trained with CPM and proper normalization, can match or exceed more complex decoder‑only or state‑space models, offering faster single‑step inference and reduced error propagation; (3) providing a transparent, reproducible baseline is crucial for fair comparison in the rapidly evolving TSFM field.
To foster reproducibility, the paper releases the pretrained checkpoints, the full training pipeline, and detailed logs on a public repository. The authors also outline future directions, such as extending the approach to multivariate series, domain‑adaptive fine‑tuning, and applying the same training principles to related tasks like imputation or anomaly detection. In summary, the work demonstrates that a generic patch‑Transformer, combined with a disciplined training regimen, constitutes a powerful and scalable baseline for time‑series foundation models, shifting the community’s focus toward data engineering and systematic evaluation rather than continual architectural embellishment.
Comments & Academic Discussion
Loading comments...
Leave a Comment