AEGPO: Adaptive Entropy-Guided Policy Optimization for Diffusion Models
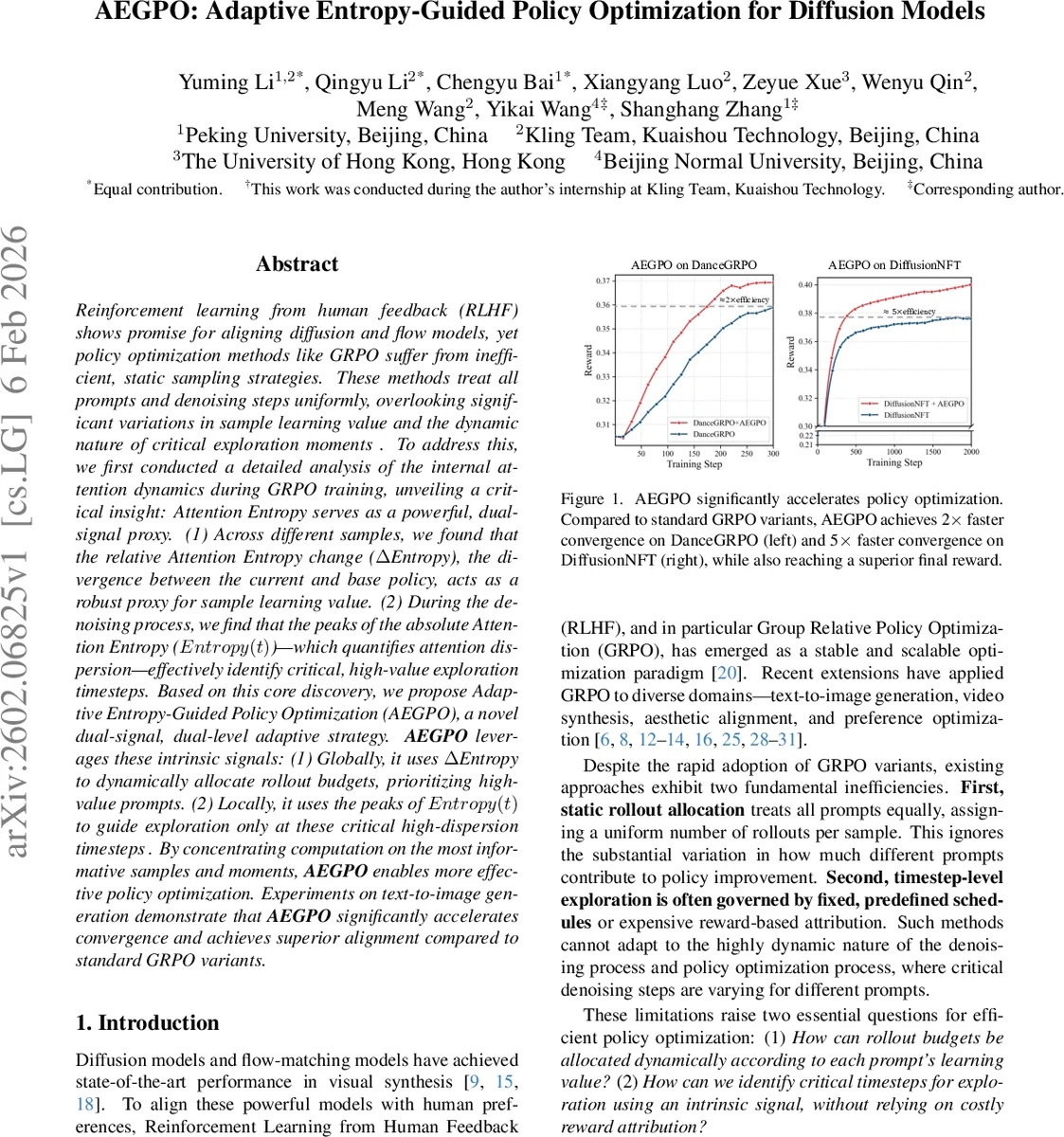
Reinforcement learning from human feedback (RLHF) shows promise for aligning diffusion and flow models, yet policy optimization methods such as GRPO suffer from inefficient and static sampling strategies. These methods treat all prompts and denoising steps uniformly, ignoring substantial variations in sample learning value as well as the dynamic nature of critical exploration moments. To address this issue, we conduct a detailed analysis of the internal attention dynamics during GRPO training and uncover a key insight: attention entropy can serve as a powerful dual-signal proxy. First, across different samples, the relative change in attention entropy (ΔEntropy), which reflects the divergence between the current policy and the base policy, acts as a robust indicator of sample learning value. Second, during the denoising process, the peaks of absolute attention entropy (Entropy(t)), which quantify attention dispersion, effectively identify critical timesteps where high-value exploration occurs. Building on this observation, we propose Adaptive Entropy-Guided Policy Optimization (AEGPO), a novel dual-signal, dual-level adaptive optimization strategy. At the global level, AEGPO uses ΔEntropy to dynamically allocate rollout budgets, prioritizing prompts with higher learning value. At the local level, it exploits the peaks of Entropy(t) to guide exploration selectively at critical high-dispersion timesteps rather than uniformly across all denoising steps. By focusing computation on the most informative samples and the most critical moments, AEGPO enables more efficient and effective policy optimization. Experiments on text-to-image generation tasks demonstrate that AEGPO significantly accelerates convergence and achieves superior alignment performance compared to standard GRPO variants.
💡 Research Summary
The paper introduces Adaptive Entropy‑Guided Policy Optimization (AEGPO), a method designed to improve the efficiency of reinforcement learning from human feedback (RLHF) for diffusion and flow models, specifically addressing the shortcomings of existing Group Relative Policy Optimization (GRPO) approaches. Traditional GRPO variants allocate a uniform number of rollouts per prompt and follow fixed exploration schedules across denoising timesteps. This uniform treatment ignores two crucial realities: (1) different prompts contribute unevenly to policy improvement, and (2) during the denoising process, only certain timesteps are truly critical for exploration.
To uncover intrinsic signals that could guide a more adaptive strategy, the authors conduct a detailed analysis of attention dynamics inside the transformer‑based diffusion model during GRPO training. They define two entropy‑based metrics: (i) Relative Entropy Change (ΔEntropy), the average absolute difference between the attention entropy of the current policy and that of a frozen base policy across all denoising steps; and (ii) Absolute Attention Entropy (Entropy(t)), the mean Shannon entropy of the attention distribution at each denoising timestep. ΔEntropy quantifies how much a sample forces the model to deviate from its prior behavior, while Entropy(t) captures how dispersed the model’s attention is at a particular step.
Empirical findings show a strong positive correlation between ΔEntropy and reward improvement (ΔReward). Samples with high ΔEntropy induce larger visual changes, require more substantial attention re‑allocation, and consequently drive faster policy gains. Training exclusively on high‑ΔEntropy samples yields markedly faster convergence and higher final reward than training on low‑ΔEntropy samples, confirming that ΔEntropy is a reliable proxy for sample‑level learning value.
At the timestep level, the distribution of Entropy(t) peaks is bimodal: early peaks correspond to coarse structural decisions, while later peaks align with fine‑grained refinement. These peaks are not uniformly distributed and vary across prompts. Experiments comparing fixed exploration schedules to entropy‑peak‑guided exploration demonstrate that focusing exploration on the top‑K Entropy(t) peaks yields higher reward variance and greater generative diversity (measured by LPIPS MPD and TCE) than any fixed schedule. This indicates that Entropy(t) peaks mark moments where the denoising trajectory is most sensitive to perturbations and thus most beneficial for exploration.
AEGPO leverages both signals in a dual‑level adaptive framework while keeping the overall rollout budget constant. Global Adaptive Allocation uses ΔEntropy to dynamically assign more rollouts to high‑value prompts and fewer rollouts to low‑value prompts. Local Adaptive Exploration monitors Entropy(t) in real time and triggers exploration only at timesteps where Entropy(t) exceeds a learned threshold (i.e., at identified peaks). The implementation is lightweight: entropy computation reuses existing attention outputs, requiring no additional forward passes or external reward models.
The method is evaluated across several GRPO variants—including DanceGRPO, Branch‑GRPO, Flow‑GRPO, and DiffusionNFT—and on multiple diffusion backbones such as FLUX‑1‑dev and SD3.5‑M. Across all settings, AEGPO achieves 2× faster convergence on DanceGRPO and up to 5× faster convergence on DiffusionNFT, while also attaining higher final reward scores and improved image quality. The gains are consistent regardless of the underlying model architecture or the specific RLHF task, demonstrating the generality of the entropy‑guided approach.
In summary, the paper makes three key contributions: (1) it identifies attention entropy as a dual‑signal intrinsic proxy for both sample importance (ΔEntropy) and critical timesteps (Entropy(t)); (2) it proposes AEGPO, a plug‑and‑play framework that adaptively reallocates computation across prompts and across denoising steps; and (3) it validates that this entropy‑driven adaptation yields substantial efficiency and performance improvements across a broad spectrum of diffusion‑model alignment tasks. The work opens avenues for further research into other information‑theoretic signals (e.g., KL divergence, mutual information) and their integration into RLHF pipelines for generative AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment