AgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents
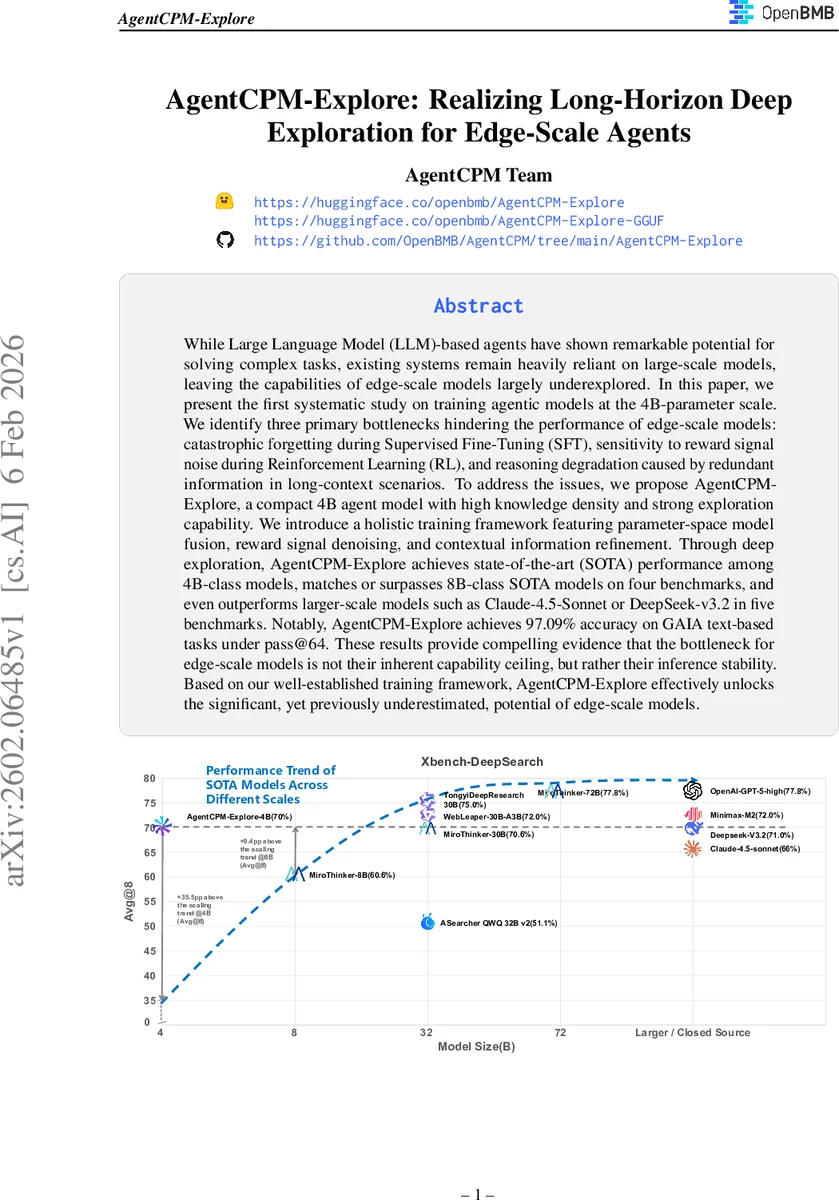
While Large Language Model (LLM)-based agents have shown remarkable potential for solving complex tasks, existing systems remain heavily reliant on large-scale models, leaving the capabilities of edge-scale models largely underexplored. In this paper, we present the first systematic study on training agentic models at the 4B-parameter scale. We identify three primary bottlenecks hindering the performance of edge-scale models: catastrophic forgetting during Supervised Fine-Tuning (SFT), sensitivity to reward signal noise during Reinforcement Learning (RL), and reasoning degradation caused by redundant information in long-context scenarios. To address the issues, we propose AgentCPM-Explore, a compact 4B agent model with high knowledge density and strong exploration capability. We introduce a holistic training framework featuring parameter-space model fusion, reward signal denoising, and contextual information refinement. Through deep exploration, AgentCPM-Explore achieves state-of-the-art (SOTA) performance among 4B-class models, matches or surpasses 8B-class SOTA models on four benchmarks, and even outperforms larger-scale models such as Claude-4.5-Sonnet or DeepSeek-v3.2 in five benchmarks. Notably, AgentCPM-Explore achieves 97.09% accuracy on GAIA text-based tasks under pass@64. These results provide compelling evidence that the bottleneck for edge-scale models is not their inherent capability ceiling, but rather their inference stability. Based on our well-established training framework, AgentCPM-Explore effectively unlocks the significant, yet previously underestimated, potential of edge-scale models.
💡 Research Summary
AgentCPM‑Explore presents the first systematic study of training agentic language models at the 4‑billion‑parameter scale, targeting the long‑standing challenge of deploying capable LLM‑driven agents on edge devices with limited compute and power budgets. The authors identify three fundamental bottlenecks that uniquely affect small‑scale agents: (1) catastrophic forgetting during supervised fine‑tuning (SFT), where a 4 B model quickly loses its general language understanding while trying to acquire task‑specific skills; (2) extreme sensitivity to noisy reward signals during reinforcement learning (RL), because sparse, error‑prone feedback from tools, network latency, or formatting mistakes can destabilize policy updates; and (3) information contamination in long‑context scenarios, where redundant observations overwhelm the limited context window and degrade reasoning quality.
To overcome these issues, the paper introduces a three‑stage training framework. First, a parameter‑space model merging step fuses a general‑purpose base model with a task‑specialized SFT model using the DELLA algorithm. By weighting and selectively pruning parameter deltas, the merged policy retains broad comprehension abilities while integrating specialized execution knowledge, thereby mitigating over‑fitting and catastrophic forgetting. Second, a reward signal denoising mechanism filters out trajectories that are likely corrupted by environmental noise (e.g., tool time‑outs, server errors), format errors (e.g., malformed JSON), or extreme length (overly short or excessively long episodes). Filtered trajectories are either removed from the batch or assigned a neutral reward, preventing misleading gradients from corrupting the RL update. Third, a context information refinement component compresses noisy long‑context inputs: it injects a search‑intent generation loss into the RL objective to encourage the agent to request only relevant information, and it distills a high‑quality summarizer from a large teacher model using multi‑sample knowledge distillation. The resulting concise summaries preserve essential facts while dramatically reducing context pollution.
Experiments span eight benchmark suites, including GAIA, DeepSearch, WebLeaper, and several proprietary tasks. AgentCPM‑Explore achieves state‑of‑the‑art performance among all 4 B models, matches or exceeds 8 B SOTA baselines on four benchmarks, and even outperforms larger closed‑source models such as Claude‑4.5‑Sonnet and DeepSeek‑V3.2 on five benchmarks. Notably, with 64 inference attempts (pass@64) on the GAIA text‑based tasks, the model solves 97.09 % of instances, effectively closing the gap between edge‑scale and large‑scale agents. Ablation studies confirm that each of the three core techniques contributes independently to the overall gain.
The authors argue that the primary limitation for edge‑scale agents is not an intrinsic capacity ceiling but rather inference stability, which can be restored through careful training pipelines. Limitations include the current focus on purely textual environments and reliance on manually set filtering thresholds. Future work will explore multimodal extensions, hardware‑aware quantization and pruning, and automated hyper‑parameter search for merging and denoising. In sum, AgentCPM‑Explore demonstrates that with a holistic training strategy, 4 B‑parameter agents can achieve deep, long‑horizon exploration comparable to much larger models, unlocking the previously underestimated potential of edge‑scale AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment