Euphonium: Steering Video Flow Matching via Process Reward Gradient Guided Stochastic Dynamics
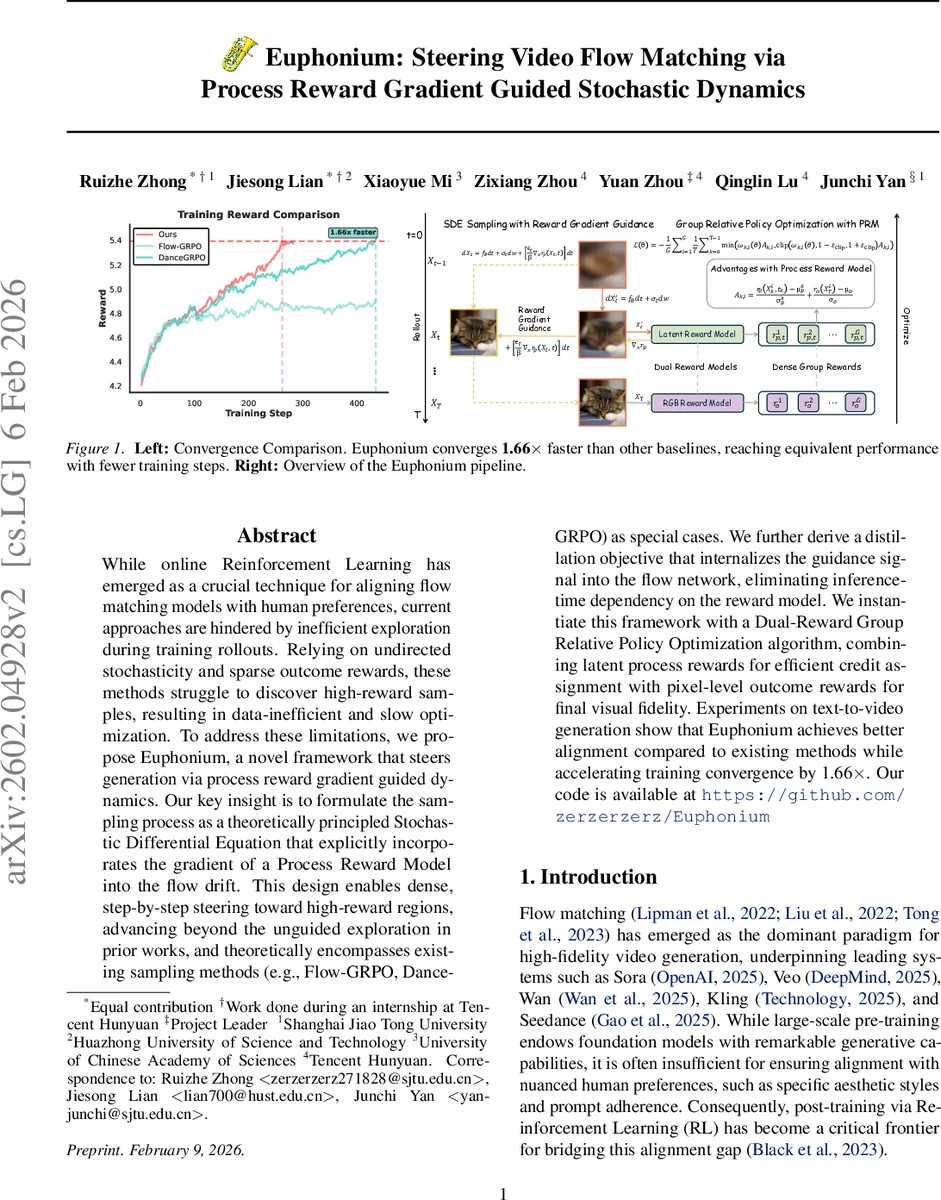
While online Reinforcement Learning has emerged as a crucial technique for aligning flow matching models with human preferences, current approaches are hindered by inefficient exploration during training rollouts. Relying on undirected stochasticity and sparse outcome rewards, these methods struggle to discover high-reward samples, resulting in data-inefficient and slow optimization. To address these limitations, we propose Euphonium, a novel framework that steers generation via process reward gradient guided dynamics. Our key insight is to formulate the sampling process as a theoretically principled Stochastic Differential Equation that explicitly incorporates the gradient of a Process Reward Model into the flow drift. This design enables dense, step-by-step steering toward high-reward regions, advancing beyond the unguided exploration in prior works, and theoretically encompasses existing sampling methods (e.g., Flow-GRPO, DanceGRPO) as special cases. We further derive a distillation objective that internalizes the guidance signal into the flow network, eliminating inference-time dependency on the reward model. We instantiate this framework with a Dual-Reward Group Relative Policy Optimization algorithm, combining latent process rewards for efficient credit assignment with pixel-level outcome rewards for final visual fidelity. Experiments on text-to-video generation show that Euphonium achieves better alignment compared to existing methods while accelerating training convergence by 1.66x. Our code is available at https://github.com/zerzerzerz/Euphonium
💡 Research Summary
The paper introduces Euphonium, a novel framework for aligning video flow‑matching models with human preferences by steering the sampling process with dense, step‑wise reward information. Traditional post‑training reinforcement‑learning approaches for flow‑matching models, such as Flow‑GRPO and DanceGRPO, inject stochasticity into deterministic ODE samplers to enable exploration, but they rely on undirected noise and receive feedback only after an entire video is generated. This results in sparse reward signals, inefficient exploration, and slow convergence.
Euphonium addresses these shortcomings by incorporating the gradient of a Process Reward Model (PRM) directly into the drift term of a stochastic differential equation (SDE) that governs the generative dynamics. Starting from the Non‑Equilibrium Transport Sampling (NETS) formulation, the authors define a time‑dependent potential
Uₜ(x) = –log pₜ(x) – (1/β) rₚ(x, t) + Cₜ,
where pₜ(x) is the marginal flow density, rₚ(x, t) is the PRM output, β controls a KL‑regularization term, and Cₜ is a constant. Substituting this potential into the NETS SDE yields:
dXₜ = (u_θ(Xₜ, t) – εₜ∇Uₜ(Xₜ)) dt + √(2εₜ) dWₜ
= (reference drift) dt + εₜβ ∇ₓ rₚ(Xₜ, t) dt + √(2εₜ) dWₜ.
The additional term εₜβ∇ₓ rₚ provides dense, per‑step guidance toward high‑reward regions, turning exploration from a blind random walk into a purposeful ascent on the reward landscape. By adjusting β, the method interpolates between pure reward‑driven dynamics (small β) and the original flow‑matching dynamics (large β), thereby unifying prior SDE‑based approaches as special cases.
To supply the required dense reward signal, the authors train a latent‑space Process Reward Model. The PRM receives a noisy latent video representation, the current timestep, and the text prompt, and outputs a scalar reward. Training uses a Bradley‑Terry pairwise ranking loss on human‑annotated preference pairs, sampled across the entire linear optimal‑transport path. This design avoids back‑propagation through the full video decoder and reduces variance compared with zeroth‑order gradient estimators.
Euphonium’s policy optimization employs a Dual‑Reward Group Relative Policy Optimization (GRPO) scheme. Two reward signals are combined: (i) the step‑wise latent reward rₚ(x, t) and (ii) a final‑frame pixel‑level outcome reward rₒ(x). For each trajectory, group‑normalized advantages are computed for both rewards and summed to form the total advantage used in the GRPO update. This dual‑reward formulation enables rapid credit assignment from early latent states while still enforcing high visual fidelity at the video level.
A practical concern is the inference‑time dependency on the PRM. The authors propose a distillation objective that forces the flow network’s drift to mimic the reward‑augmented drift. By minimizing the squared difference between the original drift and the drift with the reward gradient, the guidance signal is internalized into the network weights. After distillation, inference proceeds with the standard flow ODE/SDE without any external reward model, eliminating extra latency and memory overhead.
Experiments on the VBench2 text‑to‑video benchmark demonstrate that Euphonium outperforms Flow‑GRPO, DanceGRPO, MixGRPO, and other recent methods in both human preference scores and automatic metrics (e.g., lower FVD, higher CLIPScore). Training converges 1.66× faster, confirming the efficiency gains from guided exploration. Ablation studies reveal that (a) removing the reward gradient (β → ∞) degrades performance to the level of prior baselines, (b) using only the process reward accelerates early learning but harms final visual quality, and (c) using only the outcome reward yields good final quality but suffers from poor sample diversity and slower learning. The distilled model incurs less than 1% performance loss while reducing inference time by roughly 15%.
In summary, Euphonium contributes three key innovations: (1) a theoretically grounded reward‑augmented SDE that provides dense, step‑wise guidance, (2) a dual‑reward GRPO algorithm that efficiently assigns credit across the generation trajectory, and (3) a distillation technique that removes reward‑model dependence at inference. The framework unifies and extends prior stochastic flow‑matching methods, offering a more data‑efficient and faster route to aligning generative video models with nuanced human preferences. Future work may explore multi‑modal reward integration, scaling the PRM with larger human feedback datasets, and deploying lightweight distilled models in real‑time streaming scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment