DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
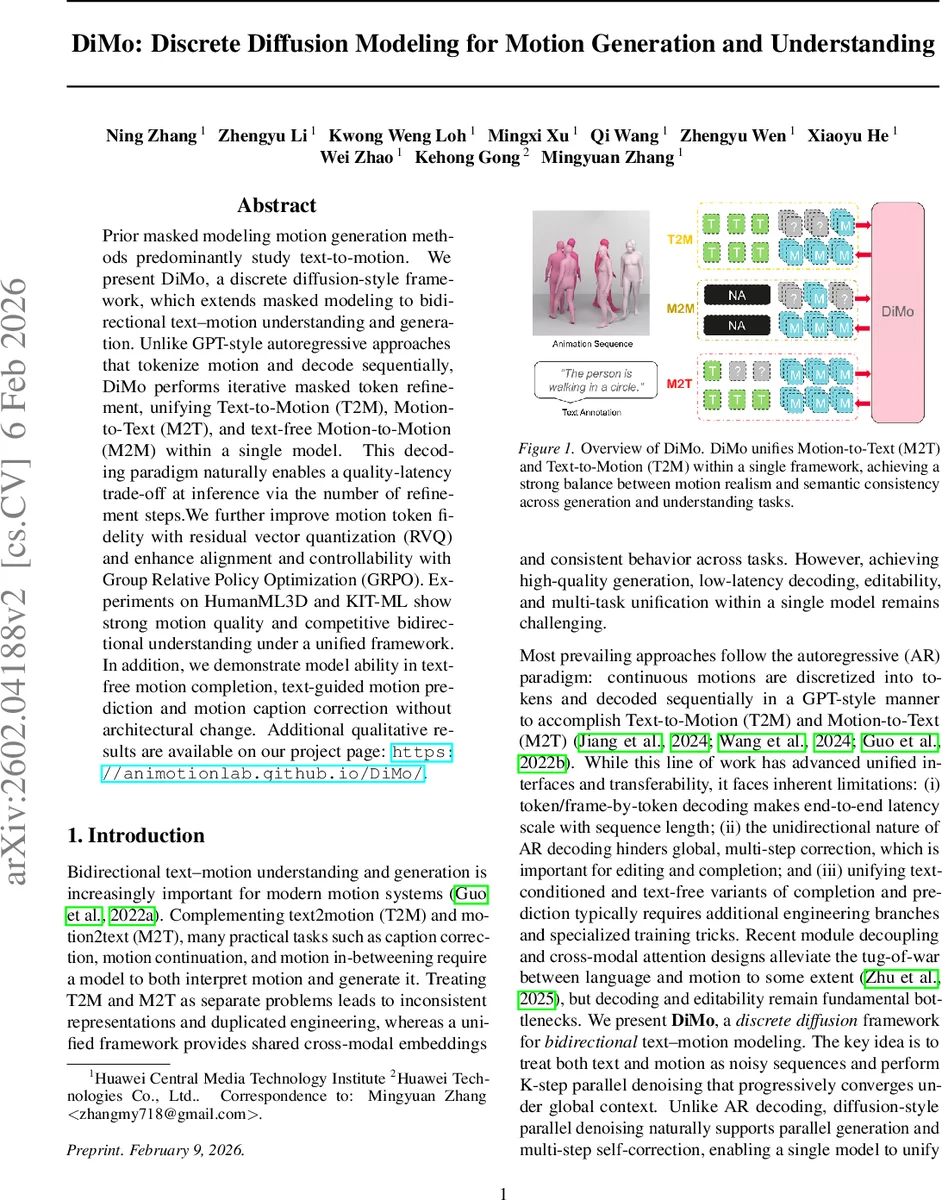
Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text–motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps. We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change. Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.
💡 Research Summary
DiMo (Discrete Diffusion Modeling) introduces a unified framework that simultaneously handles text‑to‑motion (T2M), motion‑to‑text (M2T), and text‑free motion‑to‑motion (M2M) tasks. The core idea is to treat both natural language and human motion as discrete token sequences, corrupt them with random masks, and train a single model to iteratively denoise the corrupted tokens. This diffusion‑style denoising replaces the traditional left‑to‑right autoregressive decoding used in GPT‑style models, offering parallel generation, multi‑step self‑correction, and a controllable quality‑latency trade‑off by varying the number of denoising steps at inference time.
Motion tokenization is performed with Residual Vector Quantization (RVQ). RVQ employs multiple codebooks in a residual fashion, allowing a compact representation while dramatically reducing quantization error compared to single‑codebook VQ. The resulting hierarchical motion tokens retain fine‑grained dynamics (e.g., finger articulation) and can be decoded back to 3D joint trajectories with high fidelity.
Model architecture builds on a pretrained BERT‑style masked language model as the textual backbone. Text tokens are processed unchanged, while motion tokens are embedded via a dedicated motion encoder that maps each RVQ level to the same hidden space. A shared transformer then fuses text and motion embeddings, and a motion decoder predicts logits over the RVQ vocabularies for each level. Special mask and padding tokens enable the model to handle multimodal sequences uniformly.
Training regime uses a multi‑task scheduler: each training sample is randomly assigned to one of three objectives—T2M (mask motion tokens, keep text intact), M2T (mask text tokens, keep motion intact), or M2M (mask only motion tokens). A linear masking schedule samples a per‑sample masking probability (u \sim U(0,1)), exposing the network to a wide spectrum of corruption levels and encouraging robustness. The loss is a standard masked cross‑entropy over the masked positions.
Inference follows a confidence‑guided progressive strategy. At each denoising step the model outputs a probability distribution for every currently masked token; tokens with the highest confidence (maximum probability) are committed, the rest remain masked, and the process repeats for a predefined number of steps (S). This yields a natural mechanism for early high‑confidence predictions and later refinement of uncertain regions, effectively reducing sensitivity to early mistakes and improving long‑range coherence.
Alignment and controllability are enhanced with Group Relative Policy Optimization (GRPO). GRPO is a value‑free variant of PPO that normalizes rewards within sampled candidate groups, lowering computational overhead. For T2M, the reward is the cosine similarity between CLIP embeddings of a pseudo‑caption (generated by a frozen M2T branch from the generated motion) and the ground‑truth caption, encouraging semantic consistency without hand‑crafted metrics. For M2T, the reward combines verb overlap, CLIP similarity, and a length penalty to discourage degenerate sentences. These rewards are used to fine‑tune the model after maximum‑likelihood training.
Experiments on HumanML3D and KIT‑ML demonstrate that DiMo achieves competitive or superior results compared to strong baselines such as MotionGPT, MotionGPT‑2, and recent diffusion‑based text‑motion models. Pareto curves show that with as few as 4–6 denoising steps DiMo already outperforms many autoregressive baselines in FID, R‑Precision, and Diversity, while increasing the step count further narrows the gap to state‑of‑the‑art GAN/VAEs. In the M2T direction, BLEU‑4, ROUGE‑L, and CIDEr scores are on par with or slightly better than existing methods.
Beyond the core tasks, the unified architecture naturally supports text‑free motion completion, text‑conditioned motion prediction, and motion caption correction without any architectural modifications, highlighting the extensibility of the diffusion‑based paradigm.
In summary, DiMo combines three key innovations: (1) masked‑diffusion parallel denoising for flexible, low‑latency generation; (2) RVQ‑based high‑fidelity motion tokenization; and (3) GRPO‑driven semantic alignment. This synergy yields a single model capable of bidirectional text‑motion understanding and generation, with controllable trade‑offs suitable for real‑time applications such as virtual avatar animation, embodied AI, and human‑robot interaction.
Comments & Academic Discussion
Loading comments...
Leave a Comment