D$^2$Quant: Accurate Low-bit Post-Training Weight Quantization for LLMs
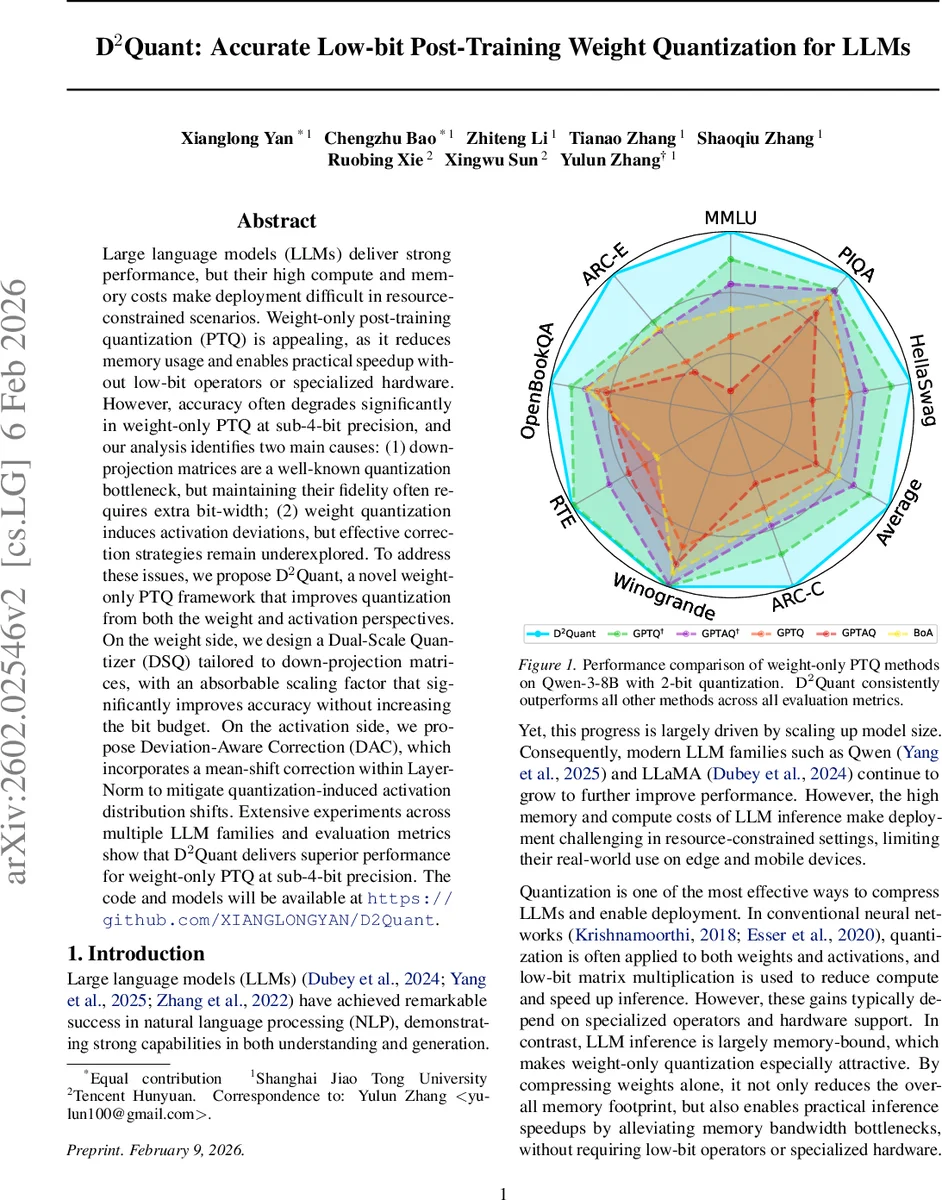
Large language models (LLMs) deliver strong performance, but their high compute and memory costs make deployment difficult in resource-constrained scenarios. Weight-only post-training quantization (PTQ) is appealing, as it reduces memory usage and enables practical speedup without low-bit operators or specialized hardware. However, accuracy often degrades significantly in weight-only PTQ at sub-4-bit precision, and our analysis identifies two main causes: (1) down-projection matrices are a well-known quantization bottleneck, but maintaining their fidelity often requires extra bit-width; (2) weight quantization induces activation deviations, but effective correction strategies remain underexplored. To address these issues, we propose D$^2$Quant, a novel weight-only PTQ framework that improves quantization from both the weight and activation perspectives. On the weight side, we design a Dual-Scale Quantizer (DSQ) tailored to down-projection matrices, with an absorbable scaling factor that significantly improves accuracy without increasing the bit budget. On the activation side, we propose Deviation-Aware Correction (DAC), which incorporates a mean-shift correction within LayerNorm to mitigate quantization-induced activation distribution shifts. Extensive experiments across multiple LLM families and evaluation metrics show that D$^2$Quant delivers superior performance for weight-only PTQ at sub-4-bit precision. The code and models will be available at https://github.com/XIANGLONGYAN/D2Quant.
💡 Research Summary
**
The paper tackles a critical challenge in deploying large language models (LLMs): the dramatic accuracy loss that occurs when weight‑only post‑training quantization (PTQ) is pushed below 4‑bit precision. The authors identify two primary sources of degradation. First, the down‑projection matrices (W_down) in the MLP blocks are highly sensitive to quantization because their values have a large dynamic range. Traditional per‑channel quantization cannot adequately compress these matrices without allocating extra bits, which defeats the purpose of low‑bit inference. Second, even though only weights are quantized, the quantization errors propagate to activations, causing systematic shifts—especially a mean shift after the attention module’s LayerNorm. This activation drift is less pronounced after MLP quantization, indicating a non‑uniform effect across transformer components.
To address these issues, the authors propose D²Quant, a weight‑only PTQ framework that improves both weight representation and activation fidelity. On the weight side, they introduce a Dual‑Scale Quantizer (DSQ). By inserting an equivalent scaling vector η between the up‑projection (W_up) and down‑projection (W_down), the up‑projection’s quantization remains unchanged while the down‑projection benefits from a smoothing effect. Rather than applying η as a static post‑processing step, DSQ treats the additional column‑wise scale s_c as an integral part of the quantization process: the quantized weight becomes Q(W) ⊙ s_c. An iterative optimization alternates between solving for s_c in closed form (with Q fixed) and re‑quantizing the normalized weights (with s_c fixed). After convergence, s_c can be folded into the existing per‑channel scales of W_up, incurring zero runtime overhead and preserving the original bit budget.
On the activation side, the authors conduct a Signal‑to‑Noise Ratio (SNR) analysis. They define SNR = |μ|/σ² where μ and σ² are the mean and variance of the activation deviation ΔY = Y_fp − Y_q at a given LayerNorm. Empirical measurements on several LLMs (e.g., LLaMA‑3‑8B) show that post‑attention LayerNorm consistently exhibits a much higher SNR than pre‑LayerNorm, confirming a strong, directional mean shift caused by attention quantization. Guided by this insight, they design Deviation‑Aware Correction (DAC), which adds a lightweight bias term to the post‑attention LayerNorm to counteract the measured mean shift. The bias is estimated from a small calibration dataset, and the correction requires only a simple addition during inference. Theoretical analysis demonstrates that the expected reduction in mean‑squared error is proportional to the SNR, validating the effectiveness of DAC.
The complete D²Quant pipeline proceeds as follows: (1) collect per‑layer activation statistics and down‑projection scaling factors using a calibration set; (2) apply DSQ to quantize down‑projections with the dual‑scale formulation; (3) merge the column‑wise scale into the up‑projection’s per‑channel scale; (4) compute and inject DAC bias into each post‑attention LayerNorm. Importantly, neither step increases the bit width nor adds noticeable latency, making D²Quant compatible with existing inference engines that lack low‑bit arithmetic support.
Extensive experiments are conducted on multiple LLM families, including Qwen‑3‑8B, LLaMA‑3‑8B, and GPT‑NeoX‑20B. The models are quantized to 2‑bit and 3‑bit weight precision while keeping activations in FP16. Evaluation spans seven zero‑shot benchmarks (MMLU, HellaSwag, PIQA, ARC, OpenBookQA, etc.). In the 2‑bit regime, D²Quant achieves an average accuracy of 57.22 %, surpassing the previous state‑of‑the‑art weight‑only PTQ method (54.05 %). The gains are especially pronounced on tasks that heavily rely on attention mechanisms, where DAC effectively neutralizes the mean shift. DSQ contributes the most to preserving performance in MLP‑heavy layers by reducing the quantization error of down‑projections. Memory footprint and FLOPs remain comparable to standard PTQ, and no specialized hardware is required, confirming the practicality of the approach for edge or mobile deployments.
The paper’s contributions are threefold: (1) a novel dual‑scale quantization scheme that improves down‑projection fidelity without extra bits; (2) a deviation‑aware correction that directly addresses activation drift induced by weight quantization; and (3) a unified framework (D²Quant) that combines both techniques to enable accurate sub‑4‑bit weight‑only quantization of LLMs. While the current DAC focuses on mean‑shift correction in LayerNorm, future work could explore handling higher‑order activation distortions and reducing reliance on calibration data. Nonetheless, D²Quant represents a significant step toward cost‑effective, high‑performance LLM inference in resource‑constrained environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment