SWE-Dev: Evaluating and Training Autonomous Feature-Driven Software Development
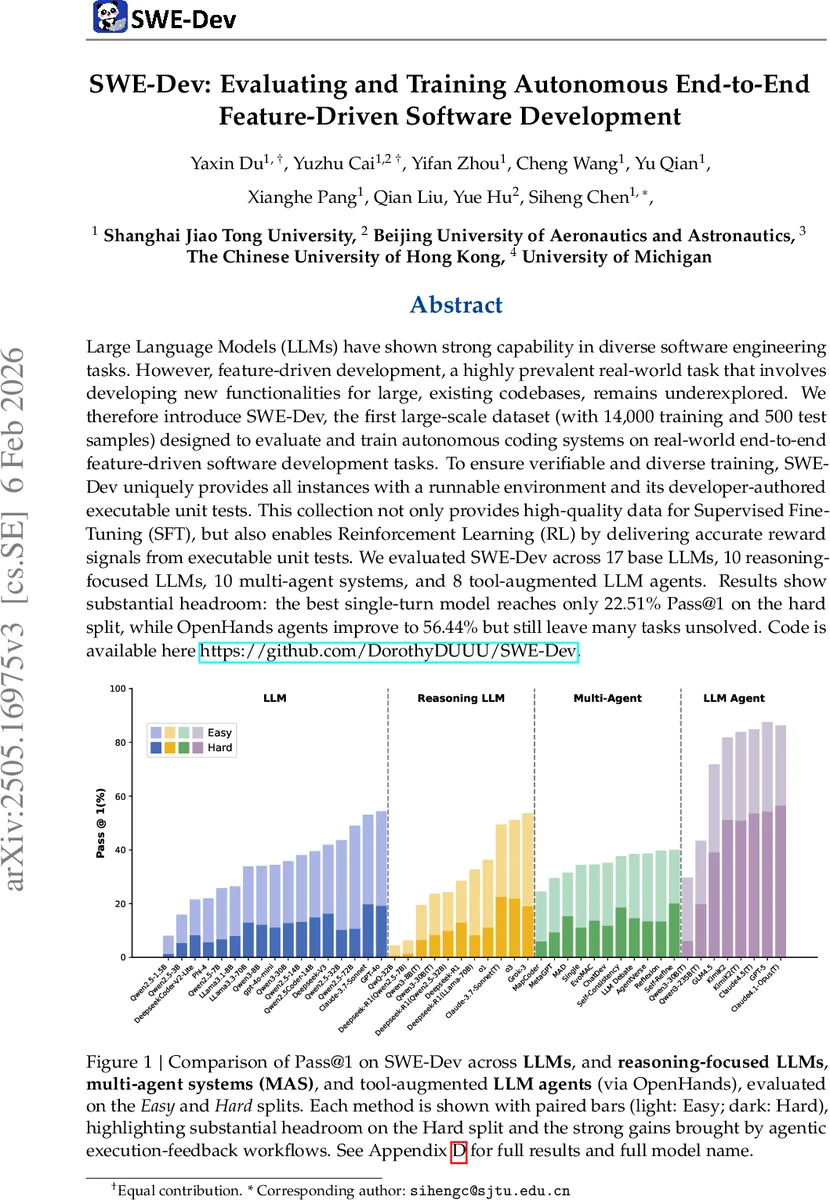
Large Language Models (LLMs) have shown strong capability in diverse software engineering tasks. However, feature-driven development, a highly prevalent real-world task that involves developing new functionalities for large, existing codebases, remains underexplored. We therefore introduce SWE-Dev, the first large-scale dataset (with 14,000 training and 500 test samples) designed to evaluate and train autonomous coding systems on real-world end-to-end feature-driven software development tasks. To ensure verifiable and diverse training, SWE-Dev uniquely provides all instances with a runnable environment and its developer-authored executable unit tests. This collection not only provides high-quality data for Supervised Fine-Tuning (SFT), but also enables Reinforcement Learning (RL) by delivering accurate reward signals from executable unit tests. We evaluated SWE-Dev across 17 base LLMs, 10 reasoning-focused LLMs, 10 multi-agent systems, and 8 tool-augmented LLM agents. Results show substantial headroom: the best single-turn model reaches only 22.51% Pass@1 on the hard split, while OpenHands agents improve to 56.44% but still leave many tasks unsolved. Code is available here https://github.com/DorothyDUUU/SWE-Dev.
💡 Research Summary
The paper introduces SWE‑Dev, the first large‑scale benchmark specifically designed for autonomous, end‑to‑end feature‑driven software development. While existing code generation benchmarks such as HumanEval, MBPP, and APPS focus on isolated, short‑context function synthesis, and repository‑level suites like SWE‑Bench or RepoBench evaluate only small bug‑fixes or unrelated function completions, none capture the real‑world workflow where developers add new capabilities to large, existing codebases. SWE‑Dev fills this gap with 14 000 training instances and 500 test instances drawn from over 1 000 open‑source Python projects. Each instance consists of (1) a realistic code repository, (2) a natural‑language Project Requirement Document (PRD) describing the new feature, (3) a masked version of the repository where the implementation of the target feature is removed, and (4) a Dockerized environment together with developer‑authored unit tests that serve as the ground‑truth verification mechanism.
Dataset construction proceeds in three stages. First, the authors collect the top 8 000 PyPI packages by star count, then filter for those that contain a test suite (pytest or unittest) that can be executed successfully in a Docker container. This strict filtering yields 1 072 validated repositories and 9 314 passing test files. Second, they dynamically trace each test execution using Python’s trace module, recording every function call in the source code. The recorded call sequences are merged into hierarchical call trees rooted at the test functions; the depth and breadth of these trees quantify task complexity and expose cross‑file dependencies. Third, they generate the actual development task by (a) identifying key nodes in the call tree (typically functions whose removal would break the feature), masking their implementations, and (b) synthesizing a PRD with GPT‑4o that combines a high‑level description derived from the test file with enriched docstrings from the masked functions. The final task presents the model with the incomplete repository and the PRD, and expects it to fill in the missing code such that the original unit tests pass.
SWE‑Dev’s design enables two complementary training paradigms. Supervised Fine‑Tuning (SFT) can use the original implementation as a target label, while Reinforcement Learning (RL) can treat the pass/fail outcome of the unit tests as an exact reward signal, allowing policy gradient updates based on functional correctness rather than proxy metrics. Because every training sample includes an executable environment, large‑scale RL on realistic software tasks becomes feasible.
The authors evaluate 45 autonomous coding systems across four categories: (1) 17 base LLMs (chatbot‑style and instruction‑tuned), (2) 10 reasoning‑focused LLMs, (3) 10 multi‑agent systems (MAS), and (4) 8 tool‑augmented agents built with the OpenHands framework. Performance is measured by Pass@1 on two difficulty splits: Easy (call‑tree depth 1–2) and Hard (depth ≥ 3). On the Easy split, the best single‑turn model (Claude‑3.7‑Sonnet) reaches 49.47% Pass@1, but on the Hard split it drops dramatically to 22.51%. OpenHands agents, which incorporate execution feedback loops, improve Hard‑split performance to 56.44%, yet still leave nearly half the tasks unsolved. MAS approaches yield modest gains (from 11.09% to 20.03% on Hard), and simple refinement strategies such as Self‑Consistency or Self‑Refine often outperform more complex multi‑turn workflows, suggesting diminishing returns from heavyweight agent orchestration in this setting.
A notable finding is that fine‑tuning a relatively small 7B model on the SWE‑Dev training set closes the gap to GPT‑4o on the Hard split, demonstrating that high‑quality, executable supervision can dramatically boost smaller models. This underscores SWE‑Dev’s utility not only as an evaluation benchmark but also as a training resource that can accelerate the development of capable coding agents.
In summary, SWE‑Dev contributes (1) a realistic, large‑scale dataset of feature‑level development tasks with substantial code modifications (average 190 LOC across three files), (2) a robust, execution‑based evaluation protocol using real unit tests in isolated Docker environments, and (3) a versatile training substrate supporting SFT, RL, and multi‑agent learning. The authors release all data and code publicly, inviting the community to benchmark, extend, and build more autonomous software development systems. The benchmark reveals substantial headroom for current models, especially on complex, cross‑file feature implementations, and sets a clear direction for future research in autonomous programming.
Comments & Academic Discussion
Loading comments...
Leave a Comment