Emergent Low-Rank Training Dynamics in MLPs with Smooth Activations
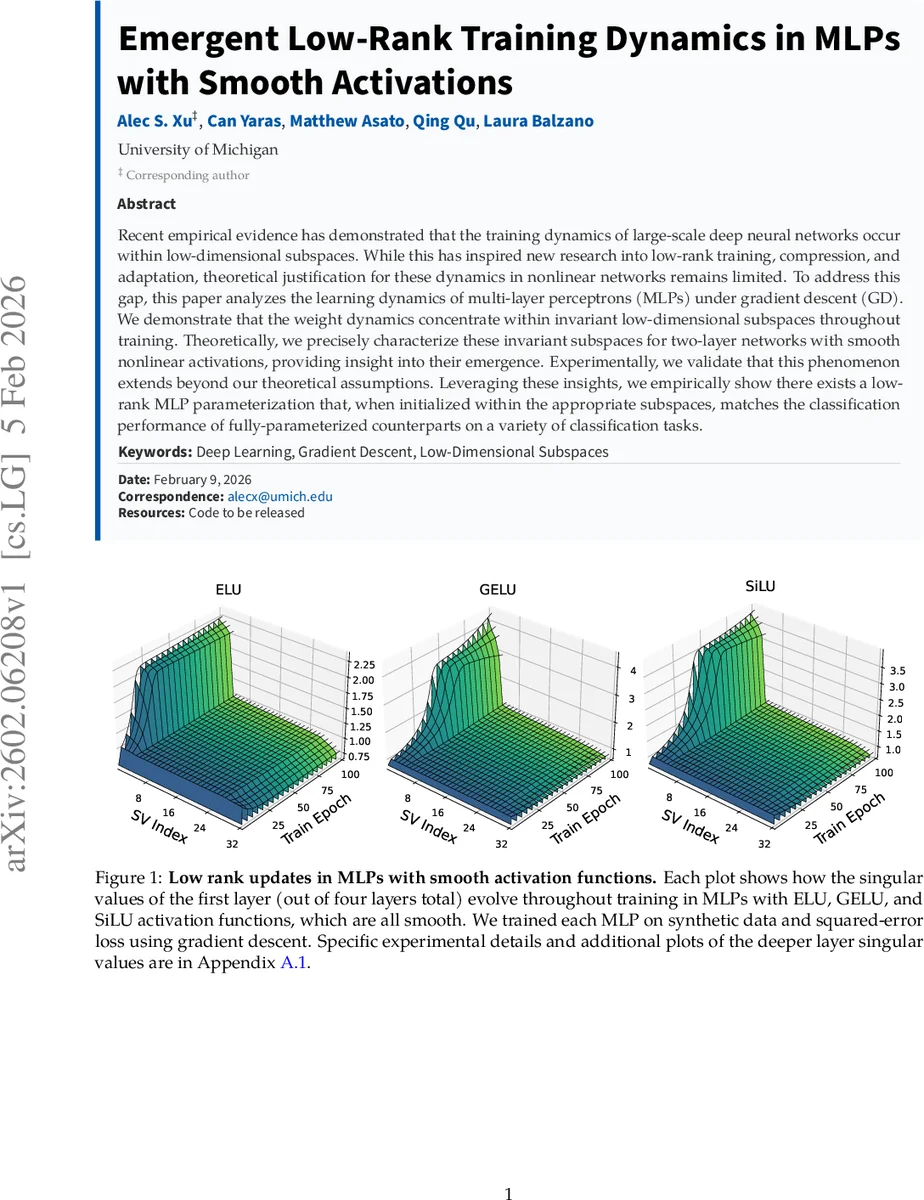
Recent empirical evidence has demonstrated that the training dynamics of large-scale deep neural networks occur within low-dimensional subspaces. While this has inspired new research into low-rank training, compression, and adaptation, theoretical justification for these dynamics in nonlinear networks remains limited. %compared to deep linear settings. To address this gap, this paper analyzes the learning dynamics of multi-layer perceptrons (MLPs) under gradient descent (GD). We demonstrate that the weight dynamics concentrate within invariant low-dimensional subspaces throughout training. Theoretically, we precisely characterize these invariant subspaces for two-layer networks with smooth nonlinear activations, providing insight into their emergence. Experimentally, we validate that this phenomenon extends beyond our theoretical assumptions. Leveraging these insights, we empirically show there exists a low-rank MLP parameterization that, when initialized within the appropriate subspaces, matches the classification performance of fully-parameterized counterparts on a variety of classification tasks.
💡 Research Summary
**
The paper “Emergent Low‑Rank Training Dynamics in MLPs with Smooth Activations” investigates why and how multi‑layer perceptrons (MLPs) trained with smooth nonlinear activation functions exhibit weight updates that remain confined to low‑dimensional subspaces throughout training. Recent empirical observations have shown that large neural networks often evolve within a small number of directions in parameter space, motivating a range of low‑rank training, adaptation, and compression techniques. However, a rigorous theoretical explanation for this phenomenon in nonlinear networks has been lacking, especially compared to the well‑studied deep linear case.
Problem setting
The authors focus on a two‑layer MLP of the form
(f_{\Theta}(X)=W_{2},\phi(W_{1}X))
where (X\in\mathbb{R}^{d\times N}) is a whitened input matrix, (Y\in\mathbb{R}^{K\times N}) are the targets, and the output dimension (K) is much smaller than the input dimension (d) (specifically (K<d/2)). The hidden width (m) satisfies (m\ge d). The activation (\phi) is assumed to be smooth: (\phi(0)=0), (|\phi’|\le\beta) and (|\phi’’|\le\mu) for all real arguments. The second‑layer matrix (W_{2}) is fixed during training and has full row rank. Training proceeds by full‑batch gradient descent (GD) on the squared‑error loss
(\mathcal{L}(W_{1})=\frac12|W_{2}\phi(W_{1}X)-Y|_{F}^{2}).
Two technical assumptions are introduced: (i) the residual (\Delta_{2}(t)=W_{2}\phi(W_{1}(t)X)-Y) remains element‑wise bounded throughout training, and (ii) the gradient (G_{1}(t)=\nabla_{W_{1}}\mathcal{L}(W_{1}(t))) satisfies a set of norm‑ and singular‑value‑growth bounds (Assumption 3.4). These assumptions are empirically validated in the appendix.
Main theoretical contribution
The central result, Theorem 3.5 (simplified), states that if the initialization satisfies (W_{1}(0)^{\top}W_{1}(0)=\varepsilon^{2}I_{d}) with (\varepsilon) small relative to (\sigma_{K}(W_{2}^{\top}YX^{\top})), and the step size (\eta) is chosen sufficiently small (on the order of (\bigl(|W_{2}|{1}+\sigma{1}^{2}(W_{2})\bigr)^{-1})), then there exist orthogonal matrices (U\in\mathbb{R}^{m\times m}) and (V\in\mathbb{R}^{d\times d}) that depend only on the initialization such that the top‑(K) left and right singular subspaces of the gradient, denoted (L_{1,1}(t)) and (R_{1,1}(t)), stay close to their initial positions for all GD iterations. Formally, the alignment measure
(A(t)=\max{| \sin\Theta(L_{1,1}(t),L_{1,1}(0))|{2},; | \sin\Theta(R{1,1}(t),R_{1,1}(0))|{2}})
remains bounded by a constant times (\eta t). In other words, the dominant directions of the gradient do not rotate appreciably; they are “invariant subspaces”. Consequently, each GD update modifies the weight matrix (W{1}) only within the span of these fixed subspaces, implying that the effective rank of the weight change never exceeds (K).
The proof proceeds in three parts. First, using Assumption 3.4, the authors show that the top‑(K) singular values of the gradient stay proportional to their initial values, while the ((K+1))‑th and higher singular values are uniformly small. Second, they apply Wedin’s sin‑θ theorem to bound the change in singular subspaces as a function of the ratio between the “signal” singular values (top‑(K)) and the “noise” singular values (the rest). Third, they substitute the GD update rule and demonstrate that the contribution of the small‑singular‑value components to the weight change is negligible, establishing the low‑rank nature of the dynamics.
Empirical validation
The authors conduct a series of experiments to test the theory beyond its strict assumptions. They train six MLPs on synthetic classification data with input dimension (d=32) and (K=4) classes, using three smooth activations (ELU, GELU, SiLU) and three non‑smooth activations (ReLU, Leaky‑ReLU, Randomized ReLU). For each model they track the singular values of the first‑layer weight matrix and the evolution of the top‑(K), middle ((d-2K)), and bottom‑(K) singular subspaces. Results (Figure 2) show that smooth activations keep the middle subspace almost static and the singular values close to their initialization, whereas non‑smooth activations cause rapid decay and large subspace rotations. Additional experiments on deeper networks (four layers), on real image datasets (Fashion‑MNIST, CIFAR‑10), and with different optimizers (SGD with momentum, Adam) reveal the same qualitative pattern: smooth activations lead to low‑rank dynamics even when the data are not whitened and the loss is cross‑entropy rather than squared error.
Low‑rank parameterization
Guided by the invariant‑subspace insight, the authors construct a low‑rank MLP where the first‑layer weight matrix is factorized as (W_{1}=U,S,V^{\top}) with (U) and (V) initialized to the orthogonal bases identified by the theory (i.e., the top‑(K) left/right singular vectors of the initial gradient). The rank of (S) is set to (K). Experiments demonstrate that this low‑rank model, when trained under the same GD schedule, matches the test accuracy of the full‑parameter model on both Fashion‑MNIST (using a deep MLP) and CIFAR‑10 (using a VGG‑16‑style architecture). Ablation studies show that mis‑aligning the initialization subspaces dramatically degrades performance, confirming the necessity of the invariant subspace alignment.
Implications and discussion
The work provides the first rigorous characterization of low‑dimensional training dynamics for nonlinear MLPs with smooth activations. It explains why low‑rank adaptation methods such as LoRA work well in practice: the gradient’s dominant directions are essentially fixed from the start, so a low‑rank adapter can capture most of the learning signal. Moreover, the analysis suggests that the choice of activation function is crucial; smoothness controls the Lipschitz constants of the derivative and second derivative, which in turn bound the gradient’s spectral decay. Although the theory assumes a fixed second layer and whitened inputs, the extensive empirical section shows that the phenomenon persists under more realistic conditions, indicating robustness of the underlying mechanism.
Conclusion
In summary, the paper demonstrates both theoretically and empirically that MLPs with smooth activation functions train within invariant low‑dimensional subspaces. This leads to emergent low‑rank weight updates, enabling a principled low‑rank parameterization that retains full‑model performance. The findings bridge a gap between empirical observations of low‑dimensional learning and formal theory for nonlinear networks, opening avenues for more efficient training, model compression, and understanding of implicit bias in deep learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment