Different Time, Different Language: Revisiting the Bias Against Non-Native Speakers in GPT Detectors
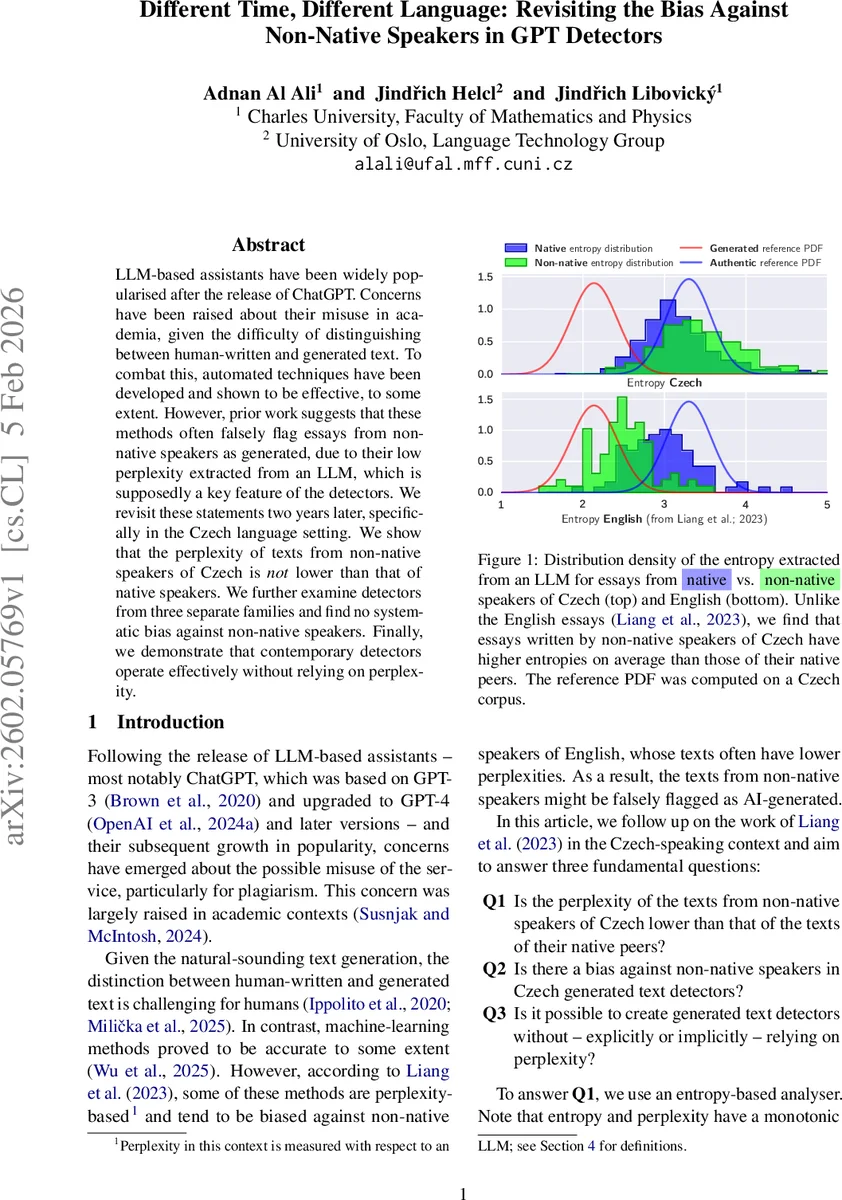
LLM-based assistants have been widely popularised after the release of ChatGPT. Concerns have been raised about their misuse in academia, given the difficulty of distinguishing between human-written and generated text. To combat this, automated techniques have been developed and shown to be effective, to some extent. However, prior work suggests that these methods often falsely flag essays from non-native speakers as generated, due to their low perplexity extracted from an LLM, which is supposedly a key feature of the detectors. We revisit these statements two years later, specifically in the Czech language setting. We show that the perplexity of texts from non-native speakers of Czech is not lower than that of native speakers. We further examine detectors from three separate families and find no systematic bias against non-native speakers. Finally, we demonstrate that contemporary detectors operate effectively without relying on perplexity.
💡 Research Summary
The paper revisits the claim that AI‑generated text detectors systematically misclassify essays written by non‑native speakers as machine‑generated, a hypothesis originally put forward by Liang et al. (2023) based on English data. The authors focus on Czech, constructing a diverse set of corpora that include authentic news, Wikipedia articles, academic abstracts, and, crucially, essays written by both native Czech speakers and learners of Czech. They also generate parallel synthetic texts using GPT‑4o, GPT‑4o‑mini, and Llama 3.1 to create balanced training and evaluation sets.
To address the first research question (Q1) – whether non‑native Czech writers produce lower‑perplexity (higher‑entropy) texts – the authors adopt an entropy‑based analysis rather than raw perplexity. Entropy is defined as the per‑token average negative log‑likelihood under a language model, preserving the monotonic relationship with perplexity while yielding a distribution that approximates a Gaussian. They use Llama 3.2 1B as the reference model because GPT‑2 performs poorly on Czech. After truncating each document to 512 tokens and discarding the first 50 tokens for context, they compute entropy for all datasets. The results show that non‑native essays have a mean entropy of 3.48 ± 0.57, significantly higher than native youth essays (3.19 ± 0.49, p < 10⁻¹⁴). Thus, contrary to the English‑based findings, Czech non‑native texts are not “simpler” for the model; they actually appear more unpredictable.
The second question (Q2) investigates detector bias. Three families of detectors are evaluated: (1) classical bag‑of‑words models with SVM/Random Forest, (2) a fine‑tuned RoBERTa‑like transformer trained on the Czech corpora, and (3) a closed‑source commercial detector. All models are trained on the SYNV9 corpus (news/magazine) and validated on Wikipedia and news splits. They are then tested on four groups: native essays, non‑native essays, advanced non‑native essays, and synthetic texts. Across all domains, false‑positive rates on non‑native essays remain below 5 %, comparable to those on native essays. The fine‑tuned transformer shows strong domain transferability, and the commercial system, despite being a black box, does not rely on explicit entropy features yet achieves high F1 (>0.90). Hence, no systematic bias against Czech non‑native writers is observed.
The third question (Q3) asks whether effective detectors can be built without (explicit or implicit) reliance on perplexity. To probe this, the authors compute Pearson correlations between each detector’s confidence scores and the entropy values for both human‑written and synthetic texts. Correlations are weak (|r| < 0.2) across all models, indicating that the detectors are not using entropy as a primary cue. Further analysis of internal representations (e.g., attention patterns) suggests that stylistic, syntactic, and semantic features dominate the decision process. Consequently, modern detectors can indeed operate effectively without depending on perplexity.
Overall, the study demonstrates that the alleged bias against non‑native speakers is language‑specific and does not generalize to Czech. It also confirms that contemporary detection methods have moved beyond simple perplexity‑based heuristics, leveraging richer linguistic signals to achieve robust performance. The findings advise caution when extrapolating bias results across languages and underscore the importance of multilingual evaluation in the development of AI‑generated text detectors.
Comments & Academic Discussion
Loading comments...
Leave a Comment