Attention Retention for Continual Learning with Vision Transformers
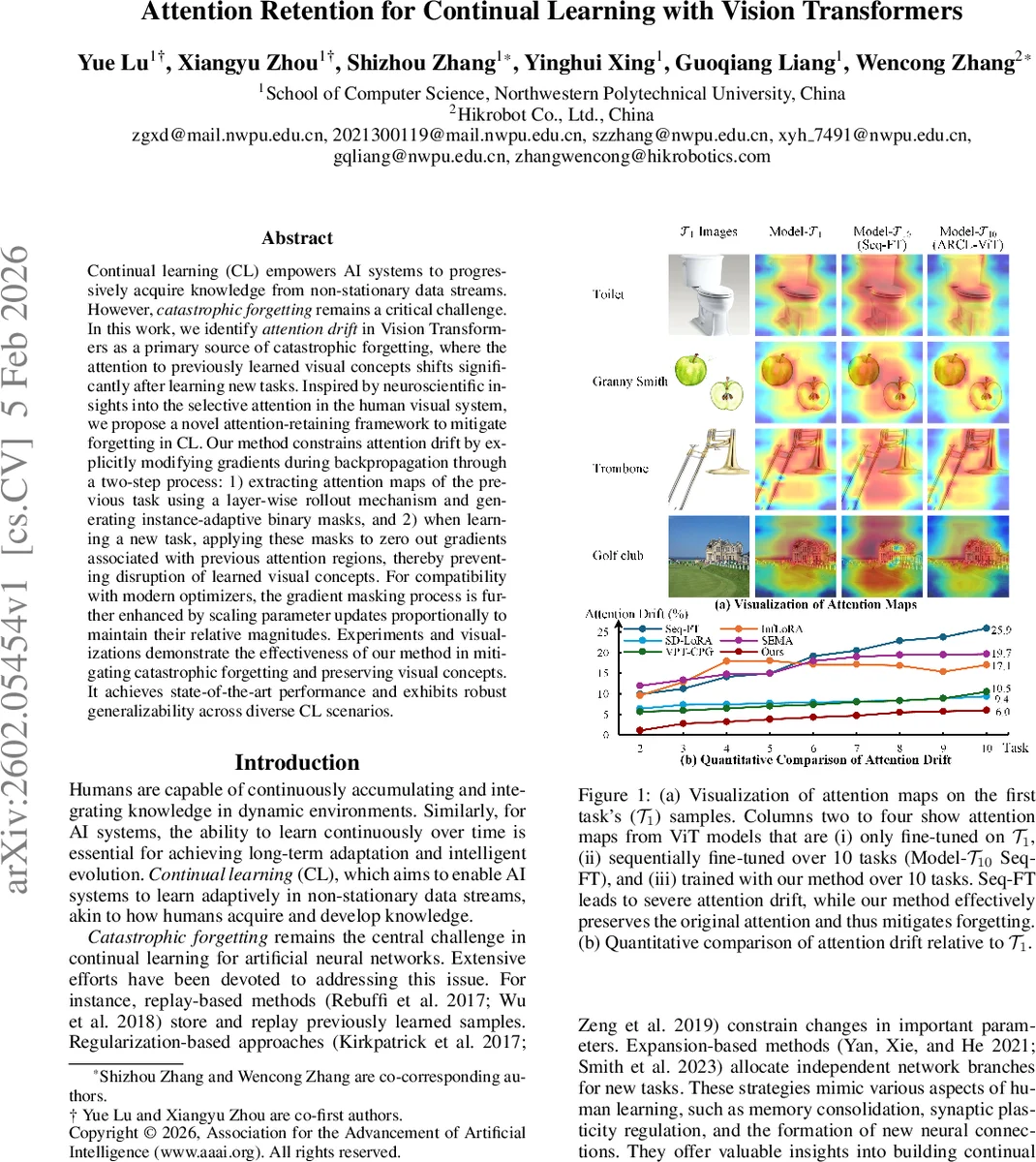
Continual learning (CL) empowers AI systems to progressively acquire knowledge from non-stationary data streams. However, catastrophic forgetting remains a critical challenge. In this work, we identify attention drift in Vision Transformers as a primary source of catastrophic forgetting, where the attention to previously learned visual concepts shifts significantly after learning new tasks. Inspired by neuroscientific insights into the selective attention in the human visual system, we propose a novel attention-retaining framework to mitigate forgetting in CL. Our method constrains attention drift by explicitly modifying gradients during backpropagation through a two-step process: 1) extracting attention maps of the previous task using a layer-wise rollout mechanism and generating instance-adaptive binary masks, and 2) when learning a new task, applying these masks to zero out gradients associated with previous attention regions, thereby preventing disruption of learned visual concepts. For compatibility with modern optimizers, the gradient masking process is further enhanced by scaling parameter updates proportionally to maintain their relative magnitudes. Experiments and visualizations demonstrate the effectiveness of our method in mitigating catastrophic forgetting and preserving visual concepts. It achieves state-of-the-art performance and exhibits robust generalizability across diverse CL scenarios.
💡 Research Summary
Continual learning (CL) aims to enable AI systems to acquire new knowledge from a stream of non‑stationary data without forgetting previously learned tasks. While many CL approaches have been proposed—replay, parameter expansion, regularization—this paper identifies a previously under‑explored source of catastrophic forgetting in Vision Transformers (ViTs): attention drift. The authors empirically show that after sequential fine‑tuning on multiple tasks, the attention maps of a ViT shift dramatically away from the regions that were important for earlier tasks, leading to a loss of previously acquired visual concepts.
Inspired by the biological visual system, which maintains stable saliency maps for previously learned objects, the authors argue that preserving the attention patterns of earlier tasks is essential for CL. Directly constraining attention drift would require storing old data, which is impractical. Instead, they propose an indirect yet effective strategy: suppress gradients that would modify the previously attended regions during back‑propagation. This eliminates the need for any replay buffer while still protecting the learned attention.
The proposed framework, ARCL‑ViT (Attention‑Retention for Continual Learning with Vision Transformers), consists of two main components:
-
Adaptive Mask Generation – After completing task (T_{t-1}), the model processes a representative sample (or a few samples) from that task and extracts the activated attention matrices (S_1, …, S_L) from all transformer layers. Using a layer‑wise rollout technique (based on the roll‑out method of Abnar & Zuidema, 2020), the authors compute a cumulative attention matrix for each layer: (\hat{S}l = \prod{i=1}^{l}(I + S_i)). This rollout captures how each input token contributes to the final class token across layers. An instance‑adaptive threshold is then applied to (\hat{S}l) to produce a binary mask (\bar{M}{t-1}) where high‑attention positions are set to 0 (to be protected) and the rest to 1.
-
Gradient Masking with Optimizer‑Aware Scaling – When training on the new task (T_t), the standard gradients w.r.t. the query, key, and value projection matrices ((\nabla W_q, \nabla W_k, \nabla W_v)) are first element‑wise multiplied by the mask (\bar{M}_{t-1}) (or its transpose for the key gradient). This operation zeroes out any gradient contribution that would alter the previously important attention entries. However, simply zero‑ing gradients can distort the dynamics of modern optimizers such as Adam, whose updates depend on first and second moments of the gradients. To preserve the relative magnitude of updates, the authors introduce a scaling rule: the ratio of the masked update to the original update should equal the ratio of the masked gradient to the original gradient. Concretely, \
Comments & Academic Discussion
Loading comments...
Leave a Comment