Dataset Distillation via Relative Distribution Matching and Cognitive Heritage
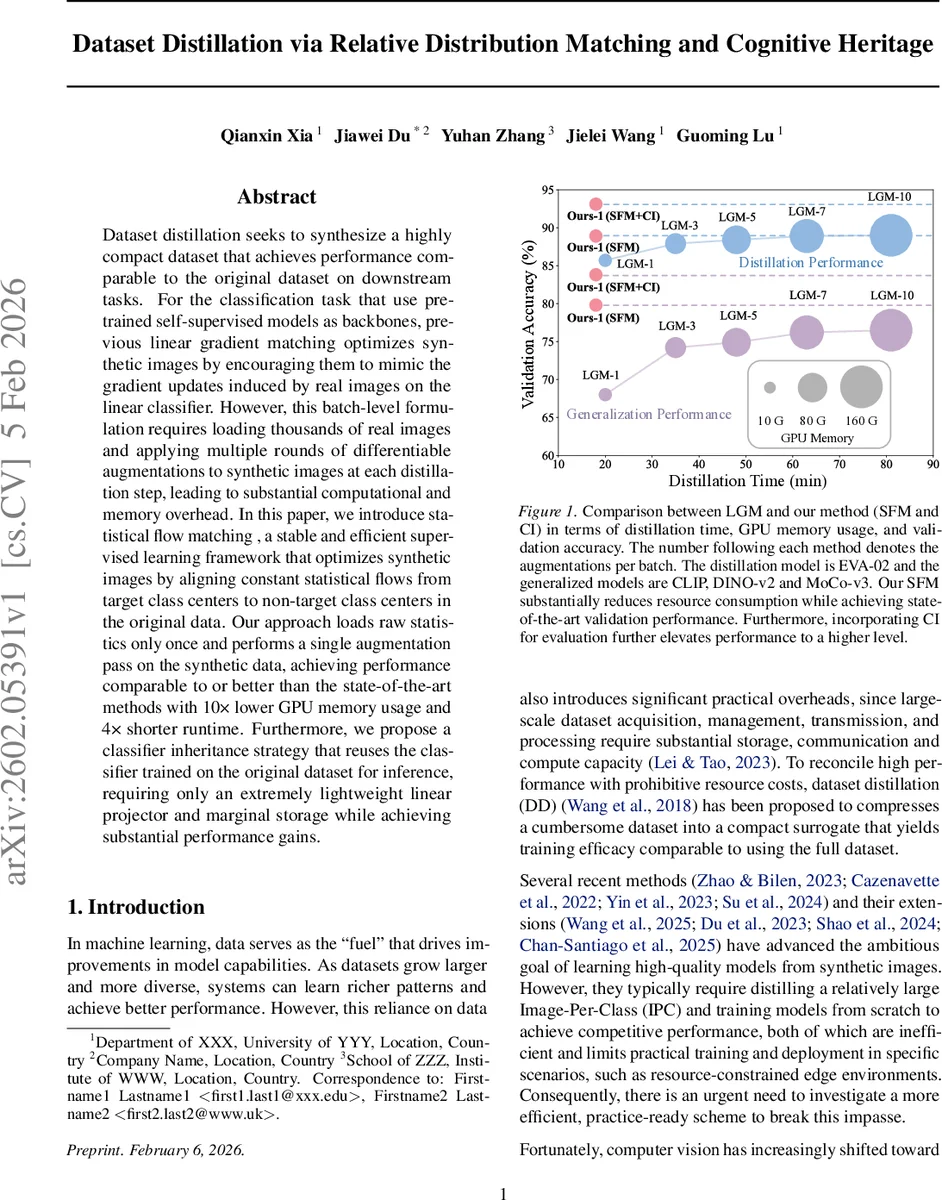
Dataset distillation seeks to synthesize a highly compact dataset that achieves performance comparable to the original dataset on downstream tasks. For the classification task that use pre-trained self-supervised models as backbones, previous linear gradient matching optimizes synthetic images by encouraging them to mimic the gradient updates induced by real images on the linear classifier. However, this batch-level formulation requires loading thousands of real images and applying multiple rounds of differentiable augmentations to synthetic images at each distillation step, leading to substantial computational and memory overhead. In this paper, we introduce statistical flow matching , a stable and efficient supervised learning framework that optimizes synthetic images by aligning constant statistical flows from target class centers to non-target class centers in the original data. Our approach loads raw statistics only once and performs a single augmentation pass on the synthetic data, achieving performance comparable to or better than the state-of-the-art methods with 10x lower GPU memory usage and 4x shorter runtime. Furthermore, we propose a classifier inheritance strategy that reuses the classifier trained on the original dataset for inference, requiring only an extremely lightweight linear projector and marginal storage while achieving substantial performance gains.
💡 Research Summary
The paper tackles the problem of dataset distillation—compressing a large training set into a tiny synthetic one—under the increasingly common scenario where a powerful self‑supervised vision model (e.g., CLIP, DINO‑v2, EVA‑02, MoCo‑v3) is frozen and only a lightweight classifier is trained on top. Existing approaches, most notably Linear Gradient Matching (LGM), require loading thousands of real images and repeatedly applying differentiable augmentations to synthetic images at every distillation step. This batch‑level formulation creates massive GPU memory footprints and long runtimes because the full computational graph for both real and synthetic data must be retained for back‑propagation.
The authors first analyze LGM mathematically. They show that, given a randomly initialized linear classifier W, the soft‑max probabilities for each sample become essentially uniform (1/C) when the number of classes C is moderate to large. Consequently, the gradient of the cross‑entropy loss with respect to W depends almost entirely on the difference between the feature means of the target class and the non‑target classes. They formalize this difference as a “flow” vector that points from the target class center to the non‑target class center in the feature space of the frozen backbone.
Building on this insight, the paper introduces two key contributions:
-
Statistical Flow Matching (SFM)
- For each class, the method pre‑computes a global statistical center (the mean feature vector of all real images belonging to that class) once.
- The flow for class c is defined as the difference between the non‑target mean and the target mean: (F^{*}c = \mu{c}^{\text{non‑target}} - \mu_{c}^{\text{target}}).
- Synthetic images are optimized so that their induced flow (F^{s}_c) aligns with the pre‑computed flow (F^{}c). Alignment is measured by a cosine similarity loss: (L{\text{SFM}} = 1 - \cos(F^{}_c, F^{s}_c)).
- Because the statistical centers are fixed, the method eliminates the need to load large batches of real images or to perform multiple augmentations on synthetic images. This dramatically reduces memory usage (by a factor of ~10) and speeds up distillation (by ~4×) while preserving or improving accuracy.
-
Classifier Inheritance (CI)
- Synthetic datasets are extremely compact (often only one image per class). Training a new linear classifier from scratch on such data struggles to capture the decision boundaries learned by a classifier trained on the full original set.
- The authors propose re‑using the “golden” classifier that was originally trained on the full dataset. During downstream evaluation, only a tiny linear projector (a single linear layer) is trained on the synthetic images to map their features into the space expected by the golden classifier.
- This strategy yields substantial performance gains over training a fresh classifier or using soft‑label guidance, while adding negligible storage or compute overhead.
Empirical results are compelling. On ImageNet‑100 with a single synthetic image per class, the method achieves 80‑95 % validation accuracy across multiple self‑supervised backbones, rivaling or surpassing state‑of‑the‑art distillation techniques. Memory consumption drops from ~165 GB (LGM) to ~16 GB, and total distillation time shrinks from ~80 minutes to ~18 minutes. Ablation studies confirm that the specific initialization of the linear classifier W (random, fixed, or analytically derived) has virtually no impact on performance, supporting the theoretical claim that the flow is independent of W.
The paper’s strengths lie in its clear theoretical grounding, practical efficiency gains, and the novel reuse of a pre‑trained classifier—a concept not previously explored in dataset distillation. Limitations include the reliance on a single global mean per class, which may be insufficient for highly multimodal class distributions, and the current focus on image classification; extending the approach to detection, segmentation, or multimodal tasks remains an open question.
In summary, by reframing gradient matching as a global statistical flow alignment and by inheriting a high‑quality classifier, the authors deliver a dataset distillation pipeline that is both computationally lightweight and performance‑competitive, making it highly suitable for resource‑constrained environments and rapid model deployment scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment