Sounding Highlights: Dual-Pathway Audio Encoders for Audio-Visual Video Highlight Detection
Audio-visual video highlight detection aims to automatically identify the most salient moments in videos by leveraging both visual and auditory cues. However, existing models often underutilize the audio modality, focusing on high-level semantic feat…
Authors: Seohyun Joo, Yoori Oh
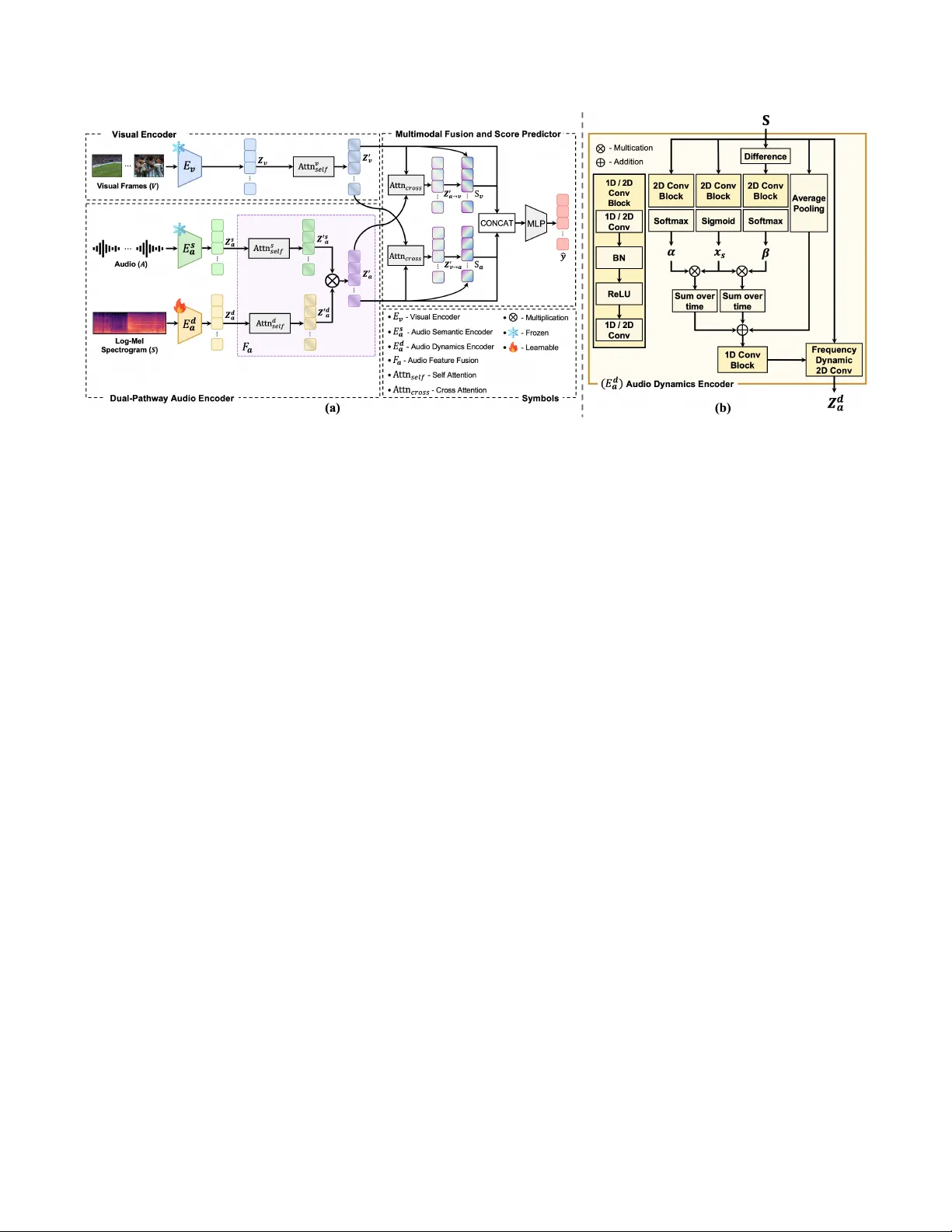
SOUNDING HIGHLIGHTS: DU AL-P A THW A Y A UDIO ENCODERS FOR A UDIO-VISU AL VIDEO HIGHLIGHT DETECTION Seohyun J oo 1 ∗ Y oori Oh 2 1 School of Electrical Engineering and Computer Science, GIST 2 Music and Audio Research Group, Seoul National Uni versity seohyunj@gm.gist.ac.kr , yoori0203@snu.ac.kr ABSTRA CT Audio-visual video highlight detection aims to automatically identify the most salient moments in videos by lev eraging both vi- sual and auditory cues. Howev er , existing models often underutilize the audio modality , focusing on high-lev el semantic features while failing to fully leverage the rich, dynamic characteristics of sound. T o address this limitation, we propose a nov el framew ork, Dual- Pathway Audio Encoders for V ideo Highlight Detection (D A V iHD). The dual-pathway audio encoder is composed of a semantic path- way for content understanding and a dynamic pathway that captures spectro-temporal dynamics. The semantic pathway extracts high- lev el information by identifying the content within the audio, such as speech, music, or specific sound ev ents. The dynamic pathway employs a frequenc y-adapti ve mechanism as time ev olves to jointly model these dynamics, enabling it to identify transient acoustic ev ents via salient spectral bands and rapid energy changes. W e integrate the no vel audio encoder into a full audio-visual frame work and achieve new state-of-the-art performance on the large-scale Mr .HiSum benchmark. Our results demonstrate that a sophisticated, dual-faceted audio representation is key to advancing the field of highlight detection. Index T erms — V ideo Highlight Detection, Audio-V isual Learning, Multimodal Fusion, Spectro-T emporal Dynamics 1. INTRODUCTION W ith the rapid growth of digital video, automated video understand- ing has become an essential area of research. A key task within this field is video highlight detection, which focuses on identifying the most interesting and engaging moments from a video. This capabil- ity is fundamental for applications such as ef fectiv e content summa- rization, retriev al, and recommendation. Initial research in video highlight detection primarily centered on visual-only approaches like PGL-SUM [1]. Subsequent w ork be- gan to integrate audio, with methods like Joint-V A [2] employing bimodal attention to model cross-modal interactions. More recently , the field has shifted towards large-scale, T ransformer-based archi- tectures. While models lik e V A TT [3], MBT [4], and UMT [5] intro- duced sophisticated multimodal fusion mechanisms, they often treat audio simplistically , relying on generic high-lev el semantic features from pre-trained backbones like P ANNs [6] while overlooking its rich spectro-temporal dynamics. This represents a significant gap, as the acoustic properties of sound itself are critical for identify- ing salient moments. The significance of these dynamics is partic- ularly apparent in video highlight detection in Figure 1. Baseline ∗ This work was done during an internship at Music and Audio Research Group, Seoul National Univ ersity . Fig. 1 : Comparison of baseline and proposed framework. The base- line model [2] produces uniform scores by relying on global audio- visual features, failing to match the ground-truth . Our proposed framew ork, howe ver , accurately captures the ground-truth dynam- ics by utilizing abrupt auditory changes, highlighted by the yellow boxes in the audio, as ke y features. approaches (blue) are insensiti ve to the transient acoustic events that signal key moments due to their reliance on general audio-visual in- formation. Our framew ork (red), ho we ver , le verages the abrupt audi- tory changes visualized in the spectrogram’ s yello w box es as crucial clues. By modeling these specific dynamics, it can predict highlight scores that closely mirror the green ground-truth pattern. T o address this, we draw inspiration from advances in audio representation learning. Early con volution-based methods [7, 8] e x- plored temporal properties but were limited by the spatial equiv- alence assumption of 2D conv olutions. A key breakthrough was Frequency-Dynamic Con volution (FDC) [9], which was proposed to address the physical inconsistencies of applying standard CNNs to spectrograms. Building on subsequent refinements of FDC that aim to capture ke y spectro-temporal information for transient acous- tic ev ents [10, 11], we propose a framework that utilizes two critical facets of sound: the semantic content of sound ( i.e., what is heard) and its spectro-temporal dynamics ( i.e., how the sound ev olves). T o this end, we introduce a novel framework, Dual-Pathw ay Audio Encoders for V ideo Highlight Detection (DA V iHD). Our ap- proach explicitly models both the high-lev el semantic content and the low-lev el spectro-temporal dynamics of the audio signal. The main contributions of our w ork are as follows: • W e propose the Dual-Pathway Audio Encoder, an architecture that disentangles the audio signal into two distinct streams to model both its semantic and dynamic properties. • By integrating our audio encoder into a unified audio-visual framew ork, we achiev e state-of-the-art (SO T A) performance on the large-scale Mr .HiSum [12] benchmark. The demo is av ailable at https://seohyj.github.io/ soundhd.github.io/ . Fig. 2 : (a) An overvie w of the DA V iHD framew ork. The model comprises a V isual Encoder ( E v ) and a Dual-Pathway Audio Encoder ( E s a , E d a ). Features from both audio encoders are fused via the Audio Feature Fusion module ( F a ), and the fused audio feature, Z ′ a , is passed to a cross-attention module and an MLP to predict the final score ˆ y . (b) Detailed architecture of the Audio Dynamics Encoder ( E d a ). It uses a multi-branch architecture to fuse two attention maps ( α, β ), modulated by a saliency gate ( x s ), with a global average-pooled feature. This information is then used to dynamically control a Frequency-Dynamic con volutional layer . 2. METHODS Figure 2 illustrates the architecture of our proposed D A V iHD frame- work. The framework processes visual and audio streams using a visual encoder and our nov el dual-pathway audio encoder , respec- tiv ely . The extracted multi-modal features are subsequently fused and fed into a score predictor to yield the final highlight scores. 2.1. Visual Encoder The visual stream takes a sequence of video frames V ∈ R T f × H × W × C as input, where T f , H , W , and C denote the number of frames, height, width, and channels, respectiv ely . Initially , a pre-trained con volutional neural network, E v , is employed as the visual back- bone [13, 14] to extract a sequence of frame-lev el features, Z v = E v ( V ) . The resulting feature sequence Z v ∈ R T f × D v , where D v is the visual embedding dimension, is then processed by a multi-head self-attention mechanism [15] to capture long-range contextual de- pendencies, yielding the final visual representation Z ′ v ∈ R T f × D v . 2.2. Dual-Pathway A udio Encoder As illustrated in Figure 2(a), the dual-pathway audio encoder ex- tracts a comprehensive audio representation by processing the au- dio stream through two parallel pathways. The first pathway , an audio semantic encoder , processes the raw audio wa veform in 1- second segments to model high-level semantic properties. Concur- rently , the second pathway , an audio dynamics encoder, takes a log- Mel spectrogram as input to capture low-lev el dynamic properties. The outputs from these pathways, audio semantic embeddings Z s a ∈ R T f × D s and audio dynamics features Z d a ∈ R T f × D d , are then fused by an audio feature fusion module. This creates a unified feature se- quence Z a ∈ R T f × D a , where D s , D d , and D a are the respectiv e dimensions of the semantic, dynamic, and fused audio embeddings. 2.2.1. Audio Semantic Encoder The audio semantic encoder, E s a , is designed to interpret the high- lev el meaning of the audio signal, essentially , what is being heard. T o achieve this, we employ the pre-trained P ANN model [6], which takes the raw audio waveform A ∈ R L as input, where L de- notes the number of samples. The model first segments the wa ve- form into a sequence of non-overlapping 1-second chunks. Each chunk is then processed independently by the encoder to extract a high-dimensional semantic embedding. Finally , these segment-lev el embeddings are concatenated chronologically to form the final se- quence of semantic embeddings Z s a ∈ R T f × D s . W e denote this entire procedure as Z s a = E s a ( A ) . 2.2.2. Audio Dynamics Encoder A standard con v olutional block is utilized throughout the model, termed the 1D/2D Con v block. It is defined as a sequence of a Con volutional layer (1D or 2D), Batch Normalization, a ReLU ac- tiv ation, and a final, dimension-matching Conv olutional layer . The audio dynamics encoder , E d a , is designed to capture low-le v el, time- varying patterns from a log-Mel spectrogram, S ∈ R F × T , where F is the number of frequency bins and T is the total number of time frames indexed by t . The encoder generates a final audio dynam- ics feature, Z d a = E d a ( S ) . As shown in Figure 2(b), it processes the input through parallel branches. T wo branches take the log-Mel spectrogram S as input and use 2D Conv blocks to generate a tem- poral attention map α via a softmax function and a salienc y gate x s via a sigmoid function. A third branch captures temporal changes by processing the frame-to-frame difference, ∆ S = | S t − S t − 1 | , which is calculated by a Dif ference module. ∆ S is then passed through the branch’ s own 2D Conv block and a softmax function to produce a velocity attention map, β . These maps are then used to compute time-aware features ( f T A ) and velocity-a ware features ( f V A ): f T A = X t ( α ⊗ x s ) , f V A = X t ( β ⊗ x s ) , (1) where ⊗ denotes element-wise multiplication. These features are then summed with a global context vector from a fourth av erage pooling branch to form a final combined vector , f combined . This vec- tor controls a Frequency-Dynamic 2D Conv layer [9]. The com- bined vector f combined is passed through a 1D Con v Block to generate frequency-specific weights γ k ( f ) , where f denotes a specific fre- quency bin, for a set of K learnable basis kernels { W k } K k =1 . These weights modulate the basis kernels, and the resulting dynamic fil- ter is applied to the original input spectrogram S . The final audio dynamics feature Z d a is computed as the following Eq.( 2), where ∗ denotes the 2D con volution. Z d a = K X k =1 γ k ⊗ ( W k ∗ S ) . (2) This mechanism, unlik e standard 2D con volutions that treat the time and frequency axes as spatially equiv alent, allows the layer to form an adaptiv e filter by dynamically combining the outputs of the fixed basis kernels. The feature map output from the Frequency Dynamic 2D Con v layer is transformed into the final sequence representation. The channel and frequency dimensions of the feature map are first flattened, then temporally aligned with the other modalities via adap- tiv e average pooling to match the temporal length of T f . Finally , a linear projection layer maps the sequence to the target embedding dimension, yielding the final audio dynamics representation Z d a . 2.2.3. Audio F eature Fusion The audio feature fusion module F a in Figure 2(a) integrates the representations from the semantic and dynamics pathways. T o contextualize each stream prior to fusion, the initial semantic fea- ture, Z s a , and dynamics feature, Z d a , are each passed through self- attention [15]. This approach of applying self-attention before fusion, which we term Early-SA, allows the model to indepen- dently capture the temporal dependencies in each stream. As will be demonstrated in our ablation study (Section 3.3), this prior con- textualization is crucial for effectiv e fusion. This operation yields refined, context-aware representations Z ′ s a = Attn s self ( Z s a ) and Z ′ d a = Attn d self ( Z d a ) , where Attn s self and Attn d self denote two inde- pendent self-attention blocks with their own learnable parameters. These contextualized features are then fused using element-wise multiplication. This fusion strategy acts as a gating mechanism, allowing the low-le v el dynamics features ( Z ′ d a ) to modulate the high-lev el semantic features ( Z ′ s a ) and amplify the salient infor- mation. The final unified audio representation, Z ′ a ∈ R T f × D a , is computed as: Z ′ a = Z ′ s a ⊗ Z ′ d a , (3) where ⊗ denotes element-wise multiplication. This representation is then passed directly to the multimodal fusion stage. 2.3. Multimodal Fusion and Score Pr ediction The final stage of our framework fuses the context-aw are visual and audio representation, Z ′ v , and Z ′ a . W e employ a bidirectional cross- modal attention Attn cross , following prior works [2–5, 16], to al- low each modality to attend to and incorporate features from the other . First, we compute an audio-contextualized visual representa- tion, Z ′ a → v , where the visual representations act as queries ( Q v ) and the audio representations provide the ke ys ( K a ) and values ( V a ): Z ′ a → v = softmax Q v K T a √ d k V a . (4) Symmetrically , we compute a visual-contextualized audio represen- tation, Z ′ v → a , by swapping the roles of the audio and visual streams. T o preserve original modality-specific information during this fu- sion, we then apply a residual connection [13] to each stream, re- sulting in the enhanced representations S v = Z ′ v + Z ′ a → v and S a = Z ′ a + Z ′ v → a . For the final prediction, the original self-attended features ( Z ′ v , Z ′ a ) and the enhanced cross-attended features ( S v , S a ) are all con- catenated together . The resulting concatenated vector is processed by a 3-layer MLP which regresses the final frame-lev el highlight score, normalized between 0 and 1. The model is optimized by min- imizing the Mean Squared Error (MSE) between the predicted scores ˆ y and the ground-truth scores y : L MSE = 1 T T X t =1 ( y t − ˆ y t ) 2 . (5) 3. EXPERIMENTS 3.1. Experimental Setups 3.1.1. Datasets The performance is evaluated on the TVSum [17] and Mr .HiSum [12] video highlight detection benchmarks. TVSum consists of 50 web videos from 10 di verse categories. Follo wing standard ev alua- tion protocols [1, 18], we use 5-fold cross-validation and report the av erage performance. Mr .HiSum is a large-scale dataset comprising 31,892 Y ouTube videos with an av erage length of 201.9 seconds. Its highlight scores are derived from Y ouT ube’ s ‘Most replayed’ statis- tics, providing a robust, user-dri ven measure. After filtering for un- av ailable videos, the experiments are conducted on 30,656 videos. 3.1.2. Evaluation Metrics W e use a set of metrics to assess dif ferent aspects of its performance. T o measure temporal localization accuracy , we use the F1-score. Follo wing standard ev aluation protocols, we con vert the continu- ous prediction scores into a binary summary by selecting the top 50% of segments and measure its temporal intersection with the ground-truth summary . For ranking quality , we report mean A verage Precision (mAP). W e compute mAP at two thresholds, mAP ρ =15% and mAP ρ =50% , which ev aluate whether ground-truth highlight seg- ments are ranked within the top 15% and 50% of all predictions. Finally , to ev aluate the alignment with human perception, we use Spearman’ s ρ and Kendall’ s τ rank correlation coefficients. These metrics directly measure the monotonic agreement between the pre- dicted score sequence and the ground-truth annotations. 3.1.3. Implementation Details All input videos are processed into 1-second segments at a rate of 1 fps. For the visual stream, the feature dimension D v is adapted for each benchmark to align with standard practices. On the TVSum dataset, we follow prior work [2, 20] and extract 512-dimensional visual features ( D v = 512 ) for each segment using a 3D CNN [21] with a ResNet-34 [13] backbone pre-trained on Kinetics-400 [22]. For the Mr .HiSum dataset [12], we adhere to its standard proto- col, extracting 1024-dimensional visual features ( D v = 1024 ) from an Inception-v3 [14] model pre-trained on ImageNet [23], followed by PCA. For the audio stream, our dual-pathway audio encoder processes two parallel inputs. The audio semantic encoder utilizes P ANNs [6] pre-trained on AudioSet [24] to extract 2048- dimensional semantic embeddings ( D s = 2048 ). The Dynamic Pathway takes a log-Mel spectrogram (16 kHz, 2048 FFT , 256 hop, 128 mel frequency bins) as input. This spectrogram is fed into the Audio Dynamics Encoder( 2.2.2), which internally downsamples the feature representation using K = 4 learnable basis kernels, to a final resolution of 1 fps to align with the semantic features, yielding a 2048-dimensional dynamic feature sequence ( D d = 2048 ). Finally , the semantic and dynamic features are fused, resulting in a unified audio representation with a final dimension of D a = 2048 . Our model is trained using the Adam optimizer [25]. For the Mr .HiSum T able 1 : Main results and comparison on the Mr .HiSum and TVSum datasets. All metrics are reported as mean ± std. over 5 runs. Higher values indicate better performance, and the best results for each metric are highlighted in bold. Model Mr .HiSum TVSum F1 ↑ mAP ρ =50% ↑ mAP ρ =15% ↑ ρ ↑ τ ↑ F1 ↑ mAP ρ =50% ↑ mAP ρ =15% ↑ ρ ↑ τ ↑ PGL-SUM † [1] 53.34 ± 0.10 59.73 ± 0.17 25.71 ± 0.30 0.104 ± 0.003 0.070 ± 0.002 52.93 ± 1.75 56.68 ± 2.33 23.18 ± 1.96 0.056 ± 0.040 0.038 ± 0.027 CST A † [19] 54.32 ± 0.17 61.12 ± 0.39 28.35 ± 0.48 0.138 ± 0.005 0.095 ± 0.004 57.32 ± 1.99 62.36 ± 2.81 27.52 ± 5.08 0.205 ± 0.056 0.141 ± 0.041 Joint-V A ‡ [2] 54.71 ± 0.04 61.82 ± 0.11 29.09 ± 0.22 0.152 ± 0.001 0.104 ± 0.001 55.03 ± 2.20 60.94 ± 3.19 26.66 ± 3.40 0.142 ± 0.046 0.097 ± 0.031 UMT ‡ [5] 58.18 ± 0.29 65.81 ± 0.31 33.79 ± 0.35 0.239 ± 0.006 0.174 ± 0.004 57.54 ± 0.87 61.49 ± 2.91 25.24 ± 5.05 0.175 ± 0.022 0.121 ± 0.015 DA ViHD (Ours) ‡ 59.73 ± 0.41 67.27 ± 0.52 36.55 ± 0.51 0.299 ± 0.012 0.213 ± 0.009 57.67 ± 1.27 63.52 ± 2.58 28.94 ± 3.11 0.200 ± 0.032 0.138 ± 0.022 † video only , ‡ video and audio T able 2 : Ablation study results for each modality’ s contribution. V denotes the visual modality , while A s and A d represent the audio semantic and dynamics pathways, respecti vely . V A s A d F1 ↑ mAP ρ =50% ↑ mAP ρ =15% ↑ ρ ↑ τ ↑ ✓ 52.98 58.93 25.31 0.101 0.069 ✓ 53.25 60.11 28.21 0.109 0.075 ✓ 57.53 63.88 33.15 0.244 0.175 ✓ ✓ 54.79 61.95 28.94 0.153 0.105 ✓ ✓ 58.25 65.84 35.51 0.269 0.191 ✓ ✓ 59.09 66.12 35.62 0.282 0.203 ✓ ✓ ✓ 60.17 68.01 36.96 0.312 0.224 T able 3 : Ablation study on different audio fusion strategies. W e analyze the impact of the self-attention (SA) layer placement (Early vs. Late) and the feature combination method (Concat vs. Multiply). SA Placement Combination F1 ↑ mAP ρ =50% ↑ mAP ρ =15% ↑ ρ ↑ τ ↑ Late Concat 58.71 66.24 35.61 0.280 0.198 Late Multiply 58.40 66.01 35.93 0.276 0.195 Early Concat 59.42 67.36 36.21 0.294 0.208 Early Multiply 60.17 68.01 36.96 0.312 0.224 dataset, we train for 200 epochs with a learning rate of 1 × 10 − 5 and a batch size of 16. For TVSum dataset, we train for 400 epochs with a learning rate of 5 × 10 − 6 and a batch size of 8. For both datasets, we use a weight decay of 1 × 10 − 4 and apply gradient clipping with a maximum norm of 0.5. 3.2. Main Results T able 1 compares the performance of the proposed D A V iHD model against sev eral highlight detection methods, including PGL- SUM [1], Joint-V A [2], UMT [5] and CST A [19]. The results indicate that our model outperforms the baseline models in most ev aluation metrics, achieving SO T A performance especially on the large-scale Mr .HiSum dataset. T o demonstrate the benefits of the audio modality , the D A V iHD model is compared against a strong vision-only model (PGL-SUM and CST A). Furthermore, it is benchmarked against two recent audio-visual models (Joint-V A and UMT). Joint-V A is considered a primary baseline due to its structural similarity to our approach. F or UMT , its text-search functionality was disabled during ev aluation to ensure a fair comparison. T o ensure the reliability of the results, each experiment was conducted fiv e times with dif ferent random initializations, and the reported scores represent the average of these runs. Notably , the proposed model outperforms even the powerful audio-visual baselines. This result highlights the effecti veness of the dual-pathway audio encoder in extracting and utilizing rich, informative features from the audio stream to identify salient moments in videos. A detailed analysis of each model component is presented in the following section. 3.3. Ablation Studies W e conduct a series of ablation studies to analyze the contribution of each component in our proposed framework. All ablation experi- ments are performed on the large-scale, Mr .HiSum dataset. Contribution of each Modality W e e v aluate the effecti v e- ness of each input modality in an ablation study . As shown in T a- ble 2, our ablation study reveals several key insights into the con- tribution of each modality . First, when considering single streams, the audio dynamics pathway ( A d ) alone significantly outperforms configurations using only the visual ( V ) or audio semantic ( A s ) streams, demonstrating that spectro-temporal dynamics are highly effecti v e for identifying highlights. Furthermore, the combination of our two audio streams ( A s + A d ) yields remarkable performance. This audio-only configuration is nearly on par with the proposed model ( V + A s + A d ) and substantially surpasses the conv entional bimodal combination of V + A s . These findings strongly indicate that a sophisticated audio representation that integrates both seman- tic and dynamic features can provide cues for highlight detection. A udio Fusion Strategy W e examine the key design choices within our Audio Feature Fusion module (described in Section 2.2.3) to verify the effecti veness of our proposed architecture. Our model employs an Early-SA configuration, where self-attention is applied to each auditory stream before fusion, combined with element-wise Multiplication for the fusion operation itself (Eq. 3). W e compare this design against three alternativ es: Early-SA with Concatenation, and two Late-SA configurations with Concatenation and Multiplica- tion. In the Late-SA configuration, self-attention is applied single time, after the initial semantic( Z s a ) and dynamic( Z d a ) features are fused. As shown in T able 3, the results confirm that our proposed configuration (Early-SA with Multiplication) achieves the best per- formance. The most critical factor is the SA placement, with Early- SA consistently outperforming Late-SA. This finding suggests that modeling temporal context within each audio stream individually is crucial before they are fused. Furthermore, the superiority of Mul- tiplication over Concatenation within the effecti ve Early-SA setting can be attrib uted to its function as a gating mechanism. A key f actor in our model’s success is the synergy between pathways, wherein dynamic features effecti v ely modulate semantic features to produce a more discriminative representation. This mechanism allows the model to amplify semantic content that is temporally correlated with salient dynamic e v ents, leading to a more robust highlight detection. 4. CONCLUSION In this work, we introduced a nov el Dual-Pathway Audio Encoders for Audio-V isual V ideo Highlight Detection. Our architecture is designed to explicitly model both the high-level semantic content and t he lo w-le vel spectro-temporal dynamics of the audio signal, ad- dressing a key limitation in prior works where audio is often treated superficially . Our experiments demonstrate the effecti veness of our approach, achieving new state-of-the-art performance on the large- scale Mr .HiSum benchmark. Notably , our audio-only configuration surpassed con ventional audio-visual models, underscoring the im- portance of a sophisticated audio representation. Acknowledgements. This work w as partly supported by Institute of Information & communications T echnology Planning & Evaluation (IITP) grant funded by the K orea go vernment(MSIT)[No. RS-2022- II220320, 20220-00320, 50%] and [No. RS2022-II220641, 50%]. 5. REFERENCES [1] Evlampios Apostolidis, Georgios Balaouras, V asileios Mezaris, and Ioannis Patras, “Combining global and local attention with positional encoding for video summarization, ” in 2021 IEEE international symposium on multimedia (ISM) . IEEE, 2021, pp. 226–234. [2] T aiv anbat Badamdorj, Mrigank Rochan, Y ang W ang, and Li Cheng, “Joint visual and audio learning for video high- light detection, ” in Pr oceedings of the IEEE/CVF International Confer ence on Computer V ision , 2021, pp. 8127–8137. [3] Hassan Akbari, Liangzhe Y uan, Rui Qian, W ei-Hong Chuang, Shih-Fu Chang, Y in Cui, and Boqing Gong, “V att: Transform- ers for multimodal self-supervised learning from raw video, audio and text, ” Advances in neural information pr ocessing systems , vol. 34, pp. 24206–24221, 2021. [4] Arsha Nagrani, Shan Y ang, Anurag Arnab, Aren Jansen, Cordelia Schmid, and Chen Sun, “ Attention bottlenecks for multimodal fusion, ” Advances in neural information process- ing systems , v ol. 34, pp. 14200–14213, 2021. [5] Y e Liu, Siyuan Li, Y ang W u, Chang-W en Chen, Y ing Shan, and Xiaohu Qie, “Umt: Unified multi-modal transformers for joint video moment retrieval and highlight detection, ” in Pr o- ceedings of the IEEE/CVF confer ence on computer vision and pattern r ecognition , 2022, pp. 3042–3051. [6] Qiuqiang Kong, Y in Cao, T urab Iqbal, Y uxuan W ang, W enwu W ang, and Mark D Plumbley , “P anns: Large-scale pre- trained audio neural networks for audio pattern recognition, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , v ol. 28, pp. 2880–2894, 2020. [7] Fanyi Xiao, Y ong Jae Lee, Kristen Grauman, Jitendra Malik, and Christoph Feichtenhofer , “ Audiovisual slo wfast networks for video recognition, ” arXiv preprint , 2020. [8] Evangelos Kazakos, Arsha Nagrani, Andrew Zisserman, and Dima Damen, “Slow-fast auditory streams for audio recogni- tion, ” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) . IEEE, 2021, pp. 855–859. [9] Hyeonuk Nam, Seong-Hu Kim, Byeong-Y un Ko, and Y ong- Hwa Park, “Frequency dynamic con volution: Frequency- adaptiv e pattern recognition for sound event detection, ” in Pr oc. Interspeech 2022 , 2022, pp. 2763–2767. [10] Hyeonuk Nam, Seong-Hu Kim, Deokki Min, Junhyeok Lee, and Y ong-Hwa Park, “Diversifying and expanding frequency- adaptiv e conv olution kernels for sound ev ent detection, ” in Pr oc. Interspeech 2024 , 2024, pp. 97–101. [11] Hyeonuk Nam and Y ong-Hwa Park, “T emporal attention pool- ing for frequency dynamic con volution in sound ev ent detec- tion, ” arXiv pr eprint arXiv:2504.12670 , 2025. [12] Jinhwan Sul, Jihoon Han, and Joonseok Lee, “Mr . hisum: A large-scale dataset for video highlight detection and summa- rization, ” Advances in Neural Information Processing Systems , vol. 36, pp. 40542–40555, 2023. [13] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition, ” in Pr oceed- ings of the IEEE confer ence on computer vision and pattern r ecognition , 2016, pp. 770–778. [14] Christian Szegedy , V incent V anhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew W ojna, “Rethinking the inception ar- chitecture for computer vision, ” in Proceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2016, pp. 2818–2826. [15] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Lukasz Kaiser , and Illia Polosukhin, “ Attention is all you need, ” Advances in neural information pr ocessing systems , vol. 30, 2017. [16] Y an-Bo Lin, Jie Lei, Mohit Bansal, and Gedas Bertasius, “Eclipse: Ef ficient long-range video retriev al using sight and sound, ” in Eur opean Conference on Computer V ision . Springer , 2022, pp. 413–430. [17] Y ale Song, Jordi V allmitjana, Amanda Stent, and Alejandro Jaimes, “Tvsum: Summarizing web videos using titles, ” in Pr oceedings of the IEEE confer ence on computer vision and pattern r ecognition , 2015, pp. 5179–5187. [18] Min Jung Lee, Dayoung Gong, and Minsu Cho, “V ideo sum- marization with large language models, ” in Proceedings of the Computer V ision and P attern Recognition Confer ence , 2025, pp. 18981–18991. [19] Jaewon Son, Jaehun Park, and Kwangsu Kim, “Csta: Cnn- based spatiotemporal attention for video summarization, ” in Pr oceedings of the IEEE/CVF Confer ence on Computer V ision and P attern Recognition , 2024, pp. 18847–18856. [20] Lezi W ang, Dong Liu, Rohit Puri, and Dimitris N Metaxas, “Learning trailer moments in full-length movies with co- contrastiv e attention, ” in European Confer ence on Computer V ision . Springer , 2020, pp. 300–316. [21] Kensho Hara, Hirokatsu Kataoka, and Y utaka Satoh, “Can spa- tiotemporal 3d cnns retrace the history of 2d cnns and ima- genet?, ” in Pr oceedings of the IEEE conference on Computer V ision and P attern Recognition , 2018, pp. 6546–6555. [22] Joao Carreira and Andrew Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset, ” in proceed- ings of the IEEE Conference on Computer V ision and P attern Recognition , 2017, pp. 6299–6308. [23] Jia Deng, W ei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei, “Imagenet: A large-scale hierarchical image database, ” in 2009 IEEE conference on computer vision and pattern r ecognition . Ieee, 2009, pp. 248–255. [24] Jort F Gemmeke, Daniel PW Ellis, Dylan Freedman, Aren Jansen, W ade Lawrence, R Channing Moore, Manoj Plakal, and Marvin Ritter , “ Audio set: An ontology and human-labeled dataset for audio e vents, ” in 2017 IEEE international con- fer ence on acoustics, speech and signal pr ocessing (ICASSP) . IEEE, 2017, pp. 776–780. [25] Diederik P Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment