Real-Time Detection of Hallucinated Entities in Long-Form Generation
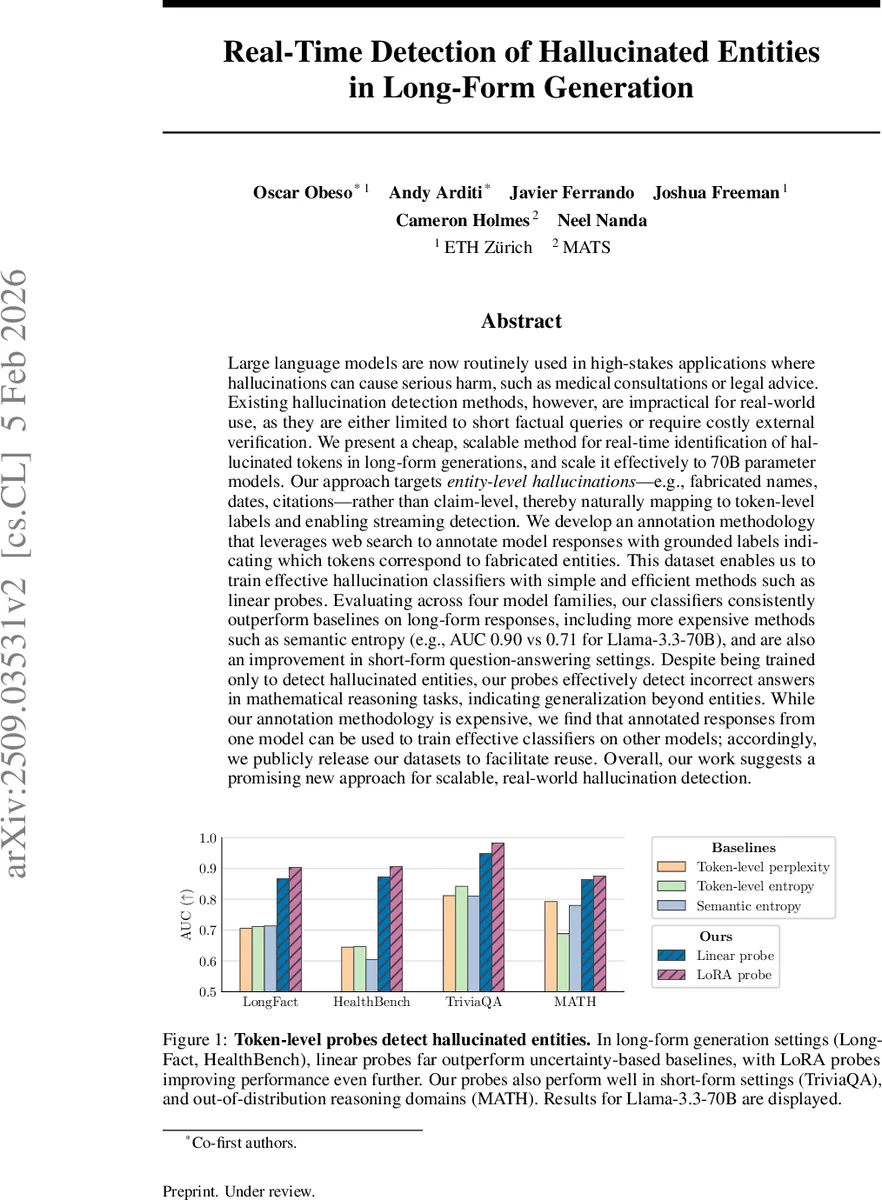
Large language models are now routinely used in high-stakes applications where hallucinations can cause serious harm, such as medical consultations or legal advice. Existing hallucination detection methods, however, are impractical for real-world use, as they are either limited to short factual queries or require costly external verification. We present a cheap, scalable method for real-time identification of hallucinated tokens in long-form generations, and scale it effectively to 70B parameter models. Our approach targets entity-level hallucinations-e.g., fabricated names, dates, citations-rather than claim-level, thereby naturally mapping to token-level labels and enabling streaming detection. We develop an annotation methodology that leverages web search to annotate model responses with grounded labels indicating which tokens correspond to fabricated entities. This dataset enables us to train effective hallucination classifiers with simple and efficient methods such as linear probes. Evaluating across four model families, our classifiers consistently outperform baselines on long-form responses, including more expensive methods such as semantic entropy (e.g., AUC 0.90 vs 0.71 for Llama-3.3-70B), and are also an improvement in short-form question-answering settings. Despite being trained only to detect hallucinated entities, our probes effectively detect incorrect answers in mathematical reasoning tasks, indicating generalization beyond entities. While our annotation methodology is expensive, we find that annotated responses from one model can be used to train effective classifiers on other models; accordingly, we publicly release our datasets to facilitate reuse. Overall, our work suggests a promising new approach for scalable, real-world hallucination detection.
💡 Research Summary
The paper tackles the pressing problem of hallucinations in large language models (LLMs) when they generate long‑form text for high‑stakes applications such as medical advice or legal analysis. Existing detection methods either focus on short question‑answering settings or rely on expensive multi‑step pipelines that extract claims, retrieve external evidence, and verify each claim—processes that are too slow for real‑time monitoring. To fill this gap, the authors propose a cheap, scalable approach that detects hallucinated entities (names, dates, citations, etc.) at the token level as the model generates text, enabling streaming detection even for 70‑billion‑parameter models.
The core of the method is a two‑stage annotation pipeline. First, they expand the LongFact benchmark into LongFact++, a ten‑fold larger collection of fact‑seeking prompts covering topics, biographies, citations, and legal cases. For each target LLM (e.g., Llama‑3.3‑70B), the prompts elicit detailed, entity‑dense completions. Second, a frontier model (Claude 4 Sonnet) equipped with web‑search capabilities extracts every entity span from the generated text, searches the web for supporting evidence, and labels each span as “Supported”, “Not Supported”, or “Insufficient Information”. Because the labels are attached to the original token indices, the resulting dataset provides token‑level supervision for hallucination detection. Human verification shows 84 % agreement with the automated labels, and a controlled error‑injection test yields 80.6 % recall with a 15.8 % false‑positive rate.
Using this dataset, the authors train lightweight classifiers that operate directly on the hidden states of the target LLM during generation. The primary classifier is a linear probe—a single linear map from each token’s hidden representation to a hallucination probability. A second, higher‑performing variant adds low‑rank adapters (LoRA) during training, which improves AUC without adding noticeable latency. Both classifiers run in the same forward pass as the LLM, so they add virtually no computational overhead and can flag hallucinated tokens as soon as they appear.
Empirical evaluation spans four model families (Llama‑3.3‑70B, Llama‑2‑70B, Falcon‑180B, Mistral‑7B) and four benchmark suites: Long‑Fact and HealthBench (long‑form factual generation), TriVAQA (short‑form QA), and MA‑TH (mathematical reasoning). Across all settings, the linear probe consistently outperforms uncertainty‑based baselines (token‑level perplexity, token‑level entropy) and a sampling‑based semantic‑entropy method. For Llama‑3.3‑70B on long‑form data, the linear probe achieves 0.87 AUC, the LoRA‑enhanced probe reaches 0.90 AUC, while semantic entropy lags at 0.71 AUC. Notably, a model trained only on entity‑level hallucinations also detects incorrect answers in the math reasoning benchmark, indicating that the learned representations capture broader factual inconsistency beyond explicit entities.
A key finding is cross‑model transferability: probes trained on hallucination‑annotated outputs from one model can effectively detect hallucinations in the outputs of other models, suggesting that the signals are model‑agnostic rather than architecture‑specific. The authors also demonstrate a proof‑of‑concept intervention where the streaming detector triggers an “abstain” decision when hallucination risk exceeds a threshold, thereby improving overall factual reliability.
Limitations include the high cost of the annotation pipeline (requiring a powerful LLM with web search) and its current reliance on English‑language web resources, which may hinder multilingual deployment. Moreover, the approach focuses on entity‑level errors; more subtle factual mistakes that do not involve a distinct entity (e.g., incorrect causal relations) remain challenging. Future work is suggested in three directions: (1) reducing annotation cost via weak supervision or semi‑automatic labeling, (2) extending the method to multimodal evidence sources and non‑English corpora, and (3) enriching the detection framework to capture claim‑level inconsistencies that lack explicit entity markers.
In summary, the paper presents a practical, low‑overhead solution for real‑time hallucination monitoring in long‑form LLM generation. By reframing the problem as token‑level entity detection and leveraging linear probes (with optional LoRA adapters), the authors achieve state‑of‑the‑art performance while maintaining streaming capability, opening a concrete path toward safer deployment of LLMs in high‑risk domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment