Annotation Free Spacecraft Detection and Segmentation using Vision Language Models
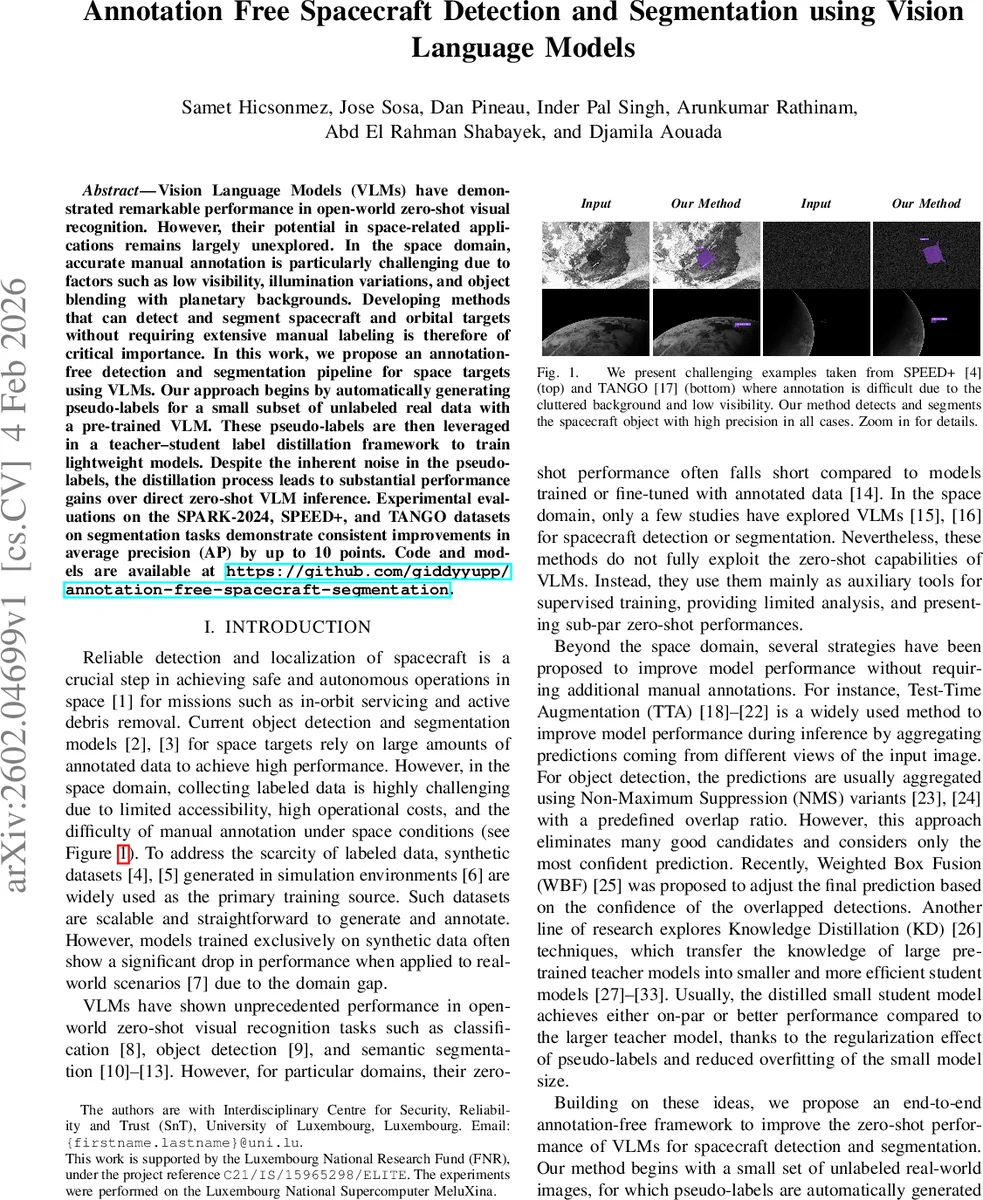
Vision Language Models (VLMs) have demonstrated remarkable performance in open-world zero-shot visual recognition. However, their potential in space-related applications remains largely unexplored. In the space domain, accurate manual annotation is particularly challenging due to factors such as low visibility, illumination variations, and object blending with planetary backgrounds. Developing methods that can detect and segment spacecraft and orbital targets without requiring extensive manual labeling is therefore of critical importance. In this work, we propose an annotation-free detection and segmentation pipeline for space targets using VLMs. Our approach begins by automatically generating pseudo-labels for a small subset of unlabeled real data with a pre-trained VLM. These pseudo-labels are then leveraged in a teacher-student label distillation framework to train lightweight models. Despite the inherent noise in the pseudo-labels, the distillation process leads to substantial performance gains over direct zero-shot VLM inference. Experimental evaluations on the SPARK-2024, SPEED+, and TANGO datasets on segmentation tasks demonstrate consistent improvements in average precision (AP) by up to 10 points. Code and models are available at https://github.com/giddyyupp/annotation-free-spacecraft-segmentation.
💡 Research Summary
The paper tackles a critical bottleneck in space situational awareness (SSA): the scarcity of high‑quality annotated imagery for training object detection and segmentation models. To eliminate the need for manual labeling, the authors devise a fully annotation‑free pipeline that leverages the zero‑shot capabilities of pre‑trained Vision‑Language Models (VLMs) and refines their outputs through test‑time augmentation (TTA), Weighted Box Fusion (WBF), and knowledge distillation.
Pipeline Overview
- Pseudo‑label Generation – A pre‑trained VLM (e.g., Grounding‑DINO, SAM) is prompted with the fixed text “spacecraft”. For each unlabeled real‑world space image the model produces a bounding‑box and an instance‑mask prediction. Because most space datasets contain a single object per frame, only the top‑ranked prediction is retained, yielding one pseudo‑label per image.
- Label Refinement – The raw VLM predictions suffer from domain shift (synthetic training data vs. real space imagery) and low‑visibility conditions. To mitigate this, the authors apply a set of K augmentations (flips, scales, color jitter) to each image, run the VLM on all K variants, and map the results back to the original coordinate system. All boxes are then clustered by Intersection‑over‑Union (IoU) and fused using WBF, which computes a confidence‑weighted average of box coordinates. After fusion, a confidence threshold θ discards low‑confidence detections, producing a cleaner set of pseudo‑labels.
- Label Distillation (Teacher‑Student) – The refined pseudo‑labels act as the “teacher” output. A lightweight student detector/segmenter (e.g., a YOLO‑Nano‑style backbone combined with a compact mask head) is trained using a standard supervised loss: a weighted sum of classification loss (L_cls) and bounding‑box regression loss (L_reg). The student model learns from hard (one‑hot) labels derived from the teacher, which simplifies training and reduces the impact of residual noise. After the first training round, the student itself generates new pseudo‑labels for the training set, and a second iteration of training can be performed. In the reported experiments only a single iteration is used, but the framework supports multiple rounds.
- Inference – The final student model, being orders of magnitude smaller than the original VLM, can run in real time on modest hardware (e.g., onboard processors). It retains most of the teacher’s accuracy while offering a favorable trade‑off between computational cost and performance.
Experimental Validation
The authors evaluate the pipeline on three publicly available space datasets: SPARK‑2024, SPEED+, and TANGO. These datasets contain real spacecraft images captured under challenging conditions such as low illumination, cluttered planetary backgrounds, and motion blur. Baseline zero‑shot performance of the VLM alone yields average precision (AP) scores of roughly 38–42 %. After applying the full pipeline, AP improves by up to 10 points (e.g., from 38.2 % to 48.9 % on SPARK‑2024). Ablation studies show that TTA + WBF alone contributes a 4–5 % AP gain, while the teacher‑student distillation adds an additional 5–6 % gain. The student models achieve inference speeds of 30–45 FPS on an NVIDIA GTX 1080Ti, demonstrating suitability for real‑time on‑orbit deployment.
Key Contributions and Insights
- Zero‑Shot Pseudo‑Labeling – Demonstrates that a generic VLM, with a simple “spacecraft” prompt, can generate usable detection and segmentation masks without any domain‑specific fine‑tuning.
- Robust Refinement – Shows that TTA combined with WBF and confidence thresholding effectively bridges the domain gap, substantially reducing label noise.
- Efficient Knowledge Distillation – By treating refined pseudo‑labels as hard teacher outputs, a compact student model can surpass the teacher’s raw zero‑shot performance while being lightweight enough for embedded use.
- Practical Impact – The method removes the costly manual annotation step, accelerates model development for new SSA scenarios (e.g., emerging debris types), and provides a scalable solution that can be adapted to other remote‑sensing domains.
Future Directions
The paper suggests several extensions: (i) exploring prompt engineering or multi‑prompt ensembles to capture a broader variety of spacecraft shapes; (ii) handling multi‑object scenes where several satellites or debris pieces appear simultaneously; (iii) iterative distillation beyond a single round to further polish pseudo‑labels; and (iv) applying the pipeline to other modalities such as infrared or hyperspectral space imagery.
In summary, the work presents a compelling, end‑to‑end framework that converts the impressive zero‑shot abilities of modern VLMs into a practical, annotation‑free solution for spacecraft detection and segmentation, delivering both accuracy gains and computational efficiency essential for real‑world space operations.
Comments & Academic Discussion
Loading comments...
Leave a Comment