Pre-optimization of quantum circuits, barren plateaus and classical simulability: tensor networks to unlock the variational quantum eigensolver
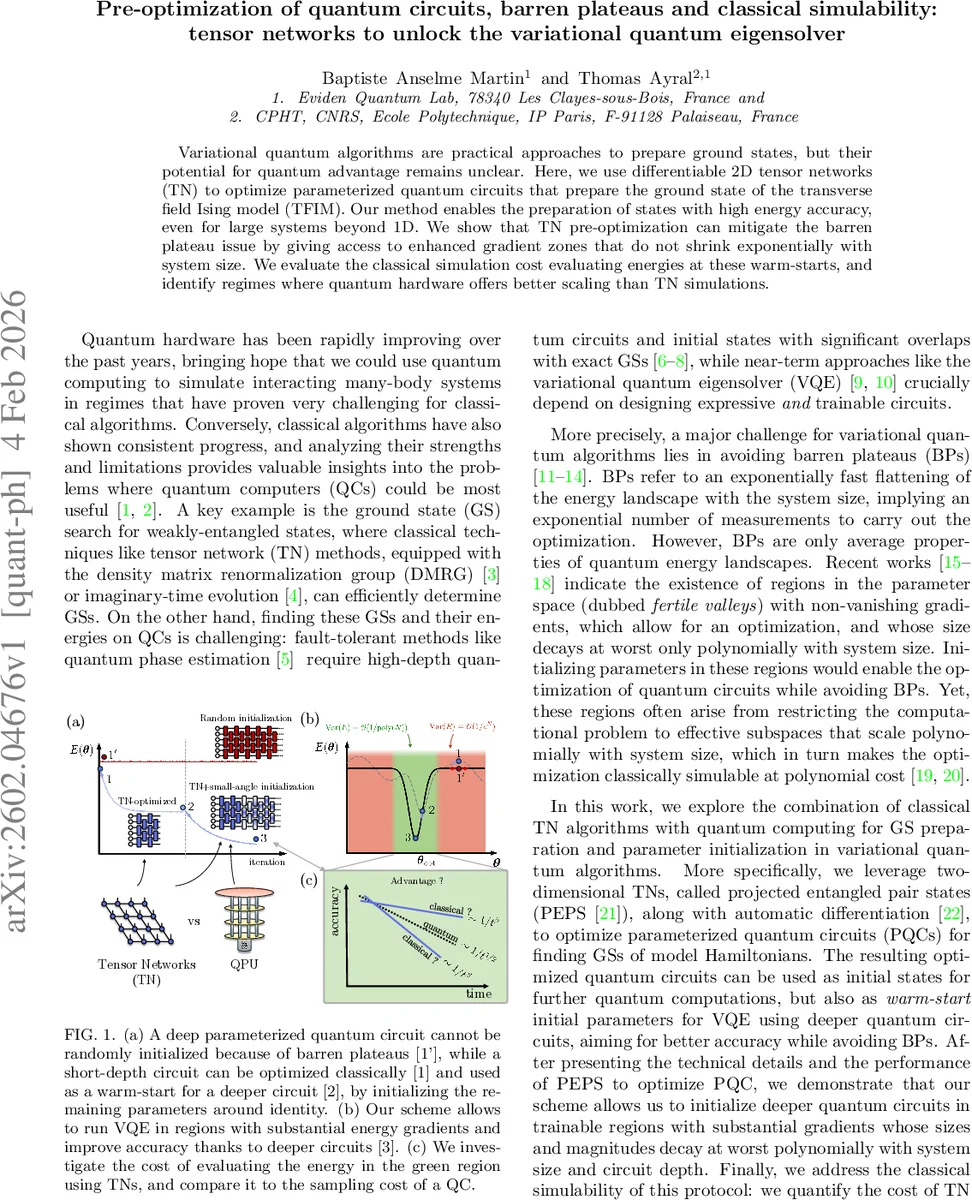
Variational quantum algorithms are practical approaches to prepare ground states, but their potential for quantum advantage remains unclear. Here, we use differentiable 2D tensor networks (TN) to optimize parameterized quantum circuits that prepare the ground state of the transverse field Ising model (TFIM). Our method enables the preparation of states with high energy accuracy, even for large systems beyond 1D. We show that TN pre-optimization can mitigate the barren plateau issue by giving access to enhanced gradient zones that do not shrink exponentially with system size. We evaluate the classical simulation cost evaluating energies at these warm-starts, and identify regimes where quantum hardware offers better scaling than TN simulations.
💡 Research Summary
This paper addresses one of the most pressing challenges in variational quantum algorithms (VQAs)—the emergence of barren plateaus (BPs) that cause gradients to vanish exponentially with system size—by introducing a classical pre‑optimization scheme based on two‑dimensional tensor networks (TNs). The authors employ projected entangled pair states (PEPS), a 2D tensor‑network ansatz, together with automatic differentiation to optimize the parameters of a parameterized quantum circuit (PQC) that prepares the ground state of the transverse‑field Ising model (TFIM). By optimizing only the first D* layers of a deeper circuit (total depth D) with PEPS, they obtain a “warm‑start” set of parameters θ_opt that can be used as the initial point for a subsequent quantum VQE run.
The technical pipeline consists of: (i) representing the quantum state after each brick‑wall layer of SO(4) two‑qubit gates as a PEPS with bond dimension χ; (ii) applying the simple‑update (SU) algorithm to contract the network efficiently (cost O(χ^{d+1}) where d is the coordination number); (iii) computing the energy expectation value either via SU‑type local updates (O(χ^{d})) or via an MPS boundary contraction; (iv) obtaining gradients through automatic differentiation and feeding them to a classical L‑BFGS‑B optimizer. This avoids the costly parameter‑shift rule on quantum hardware and enables the optimization of circuits with up to 127 qubits on realistic heavy‑hex connectivity.
Results on the heavy‑hex topology show that, for bond dimension χ=8, the relative energy error δE can be reduced below 10^{-4} across a range of transverse‑field strengths g and circuit depths D. Near the critical point (g_c≈1.5) deeper circuits (larger D) consistently yield lower energies, confirming that the PEPS‑guided optimization scales favorably even for large 2D lattices. In contrast, square‑lattice instances are more demanding; the SU approximation becomes less accurate due to stronger loop correlations, indicating that more sophisticated contraction schemes would be required for comparable performance.
To probe the BP phenomenon, the authors sample 1 000 points uniformly in a hypercube of radius r around θ_opt and compute the energy variance Var(E). Randomly initialized parameters exhibit an exponentially decaying variance with system size, characteristic of BPs. However, around the warm‑start point a region of substantially larger variance appears, indicating non‑vanishing gradients. The size of this “fertile valley” (denoted r_max) scales linearly with the number of qubits N and inversely with √D, i.e., r_max ∝ N / √D. This polynomial scaling contrasts sharply with the exponential shrinkage of gradient‑rich regions in unoptimized circuits, confirming recent theoretical predictions that pre‑optimized subspaces can avoid BPs.
The paper then evaluates the classical simulability of this approach. For a given accuracy ε_TN, the wall‑clock time t required by the PEPS simulation follows ε_TN = α t^{‑β}. Empirically, β≈1.5 for D* = 2 and β≈1.2 for D* = 6 on the heavy‑hex architecture, both substantially larger than the quantum sampling exponent β_QC = ½ (since ε_QC ∝ 1/√M ∝ 1/√t). Consequently, achieving a target precision would require more classical time than quantum sampling, suggesting a potential quantum advantage. Importantly, increasing D* (thus reducing the fraction of identity‑initialized gates) only modestly reduces β, indicating robustness of the advantage across different warm‑start depths. The scaling β shows little dependence on system size when moving from 53 to 127 qubits, implying that the advantage persists for larger devices within the studied regime.
Nevertheless, the authors acknowledge limitations. The computational cost of PEPS grows rapidly with bond dimension χ and network coordination, especially for highly connected lattices where SU updates lose accuracy. Moreover, the analysis assumes ideal quantum hardware for the subsequent VQE; real‑world noise, gate errors, and measurement imperfections could diminish the practical benefit of the warm‑start. Finally, the study focuses on the TFIM; extending the methodology to more complex Hamiltonians (e.g., fermionic models) may require tailored ansätze or higher‑order tensor networks.
In summary, the work demonstrates that classical 2D tensor‑network pre‑optimization can effectively locate gradient‑rich regions in the parameter space of deep quantum circuits, thereby mitigating barren plateaus and providing high‑quality initializations for VQE. By quantitatively comparing the scaling of classical simulation time against quantum sampling cost, the authors identify regimes where quantum hardware could achieve a polynomial speed‑up. This hybrid approach offers a concrete pathway toward practical quantum advantage in ground‑state problems of two‑dimensional many‑body systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment