LEAD: Layer-wise Expert-aligned Decoding for Faithful Radiology Report Generation
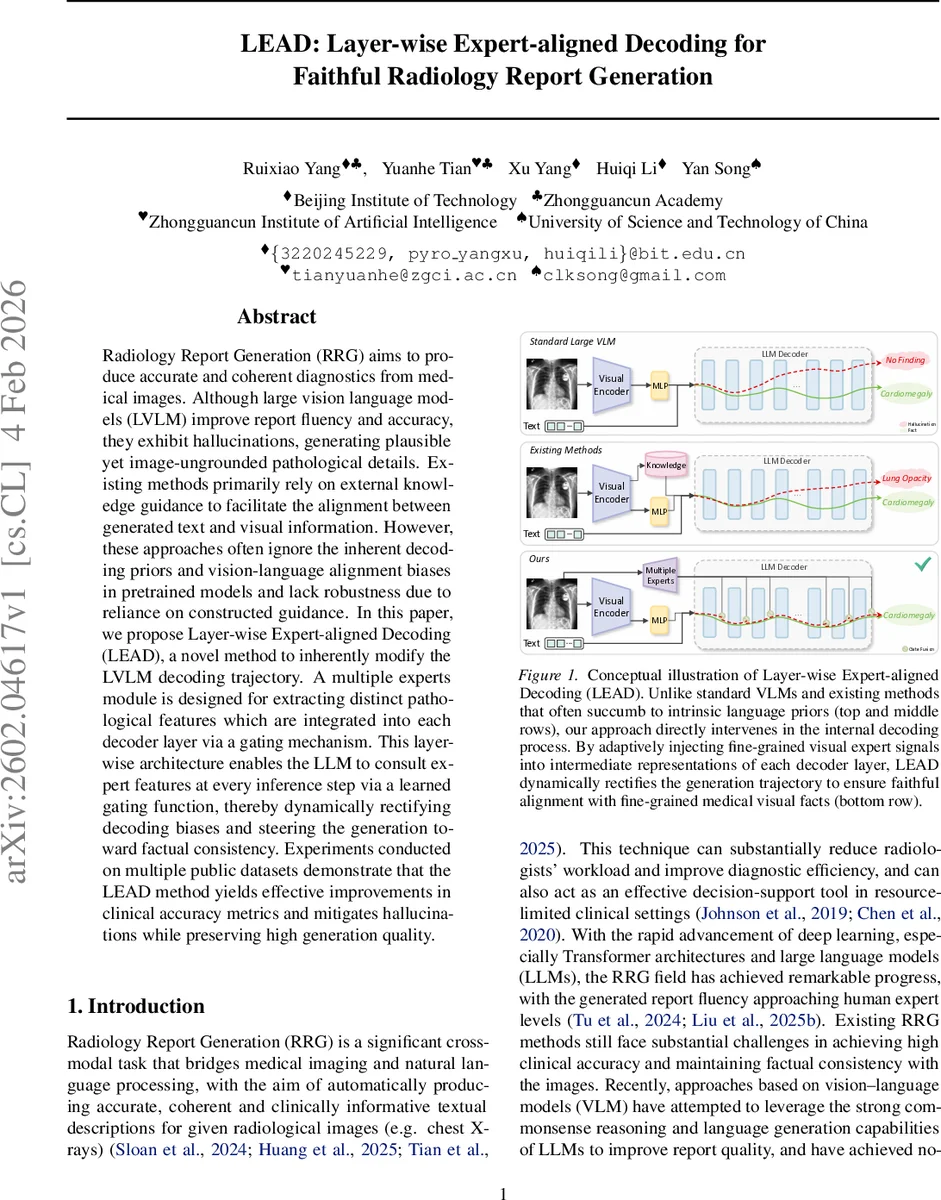
Radiology Report Generation (RRG) aims to produce accurate and coherent diagnostics from medical images. Although large vision language models (LVLM) improve report fluency and accuracy, they exhibit hallucinations, generating plausible yet image-ungrounded pathological details. Existing methods primarily rely on external knowledge guidance to facilitate the alignment between generated text and visual information. However, these approaches often ignore the inherent decoding priors and vision-language alignment biases in pretrained models and lack robustness due to reliance on constructed guidance. In this paper, we propose Layer-wise Expert-aligned Decoding (LEAD), a novel method to inherently modify the LVLM decoding trajectory. A multiple experts module is designed for extracting distinct pathological features which are integrated into each decoder layer via a gating mechanism. This layer-wise architecture enables the LLM to consult expert features at every inference step via a learned gating function, thereby dynamically rectifying decoding biases and steering the generation toward factual consistency. Experiments conducted on multiple public datasets demonstrate that the LEAD method yields effective improvements in clinical accuracy metrics and mitigates hallucinations while preserving high generation quality.
💡 Research Summary
Radiology Report Generation (RRG) aims to automatically produce clinically accurate textual descriptions from medical images such as chest X‑rays. Recent advances in large vision‑language models (LVLMs) have markedly improved fluency and overall quality, yet they remain prone to “hallucinations”: the generation of plausible‑looking pathological statements that are not grounded in the visual evidence. Existing mitigation strategies typically rely on external knowledge bases, retrieval‑augmented generation, or contrastive learning to guide the model toward better image‑text alignment. While these methods can boost performance, they do not address the intrinsic decoding biases introduced by the pretrained language model, and they depend heavily on the quality of the constructed guidance, which can limit robustness.
The paper introduces Layer‑wise Expert‑aligned Decoding (LEAD), a novel framework that directly intervenes in the LVLM’s decoding trajectory. The core idea is to treat the LVLM as a “student” that consults a set of visual experts at every decoding step. A visual expert module is built on top of the image encoder (ViT) and consists of multiple binary classifiers, each dedicated to a specific pathology (e.g., cardiomegaly, pleural effusion). These classifiers are three‑layer MLPs trained with multi‑label supervision extracted from the reports. During inference, each classifier produces an intermediate feature vector; the vector is weighted by a confidence score derived from the classifier’s logit (sigmoid‑scaled) to suppress noisy or irrelevant experts. All weighted features are concatenated and linearly projected into a global expert embedding e.
Because each decoder layer of the language model captures information at a different abstraction level, LEAD projects e into a layer‑specific embedding eₗ using a small MLP ϕₗ. At decoding step t of layer l, the hidden state hₗₜ is concatenated with eₗ, and a context‑aware gating network ϕ_gate computes a scalar gate gₗₜ = σ(ϕ_gate(
Comments & Academic Discussion
Loading comments...
Leave a Comment