ConvexBench: Can LLMs Recognize Convex Functions?
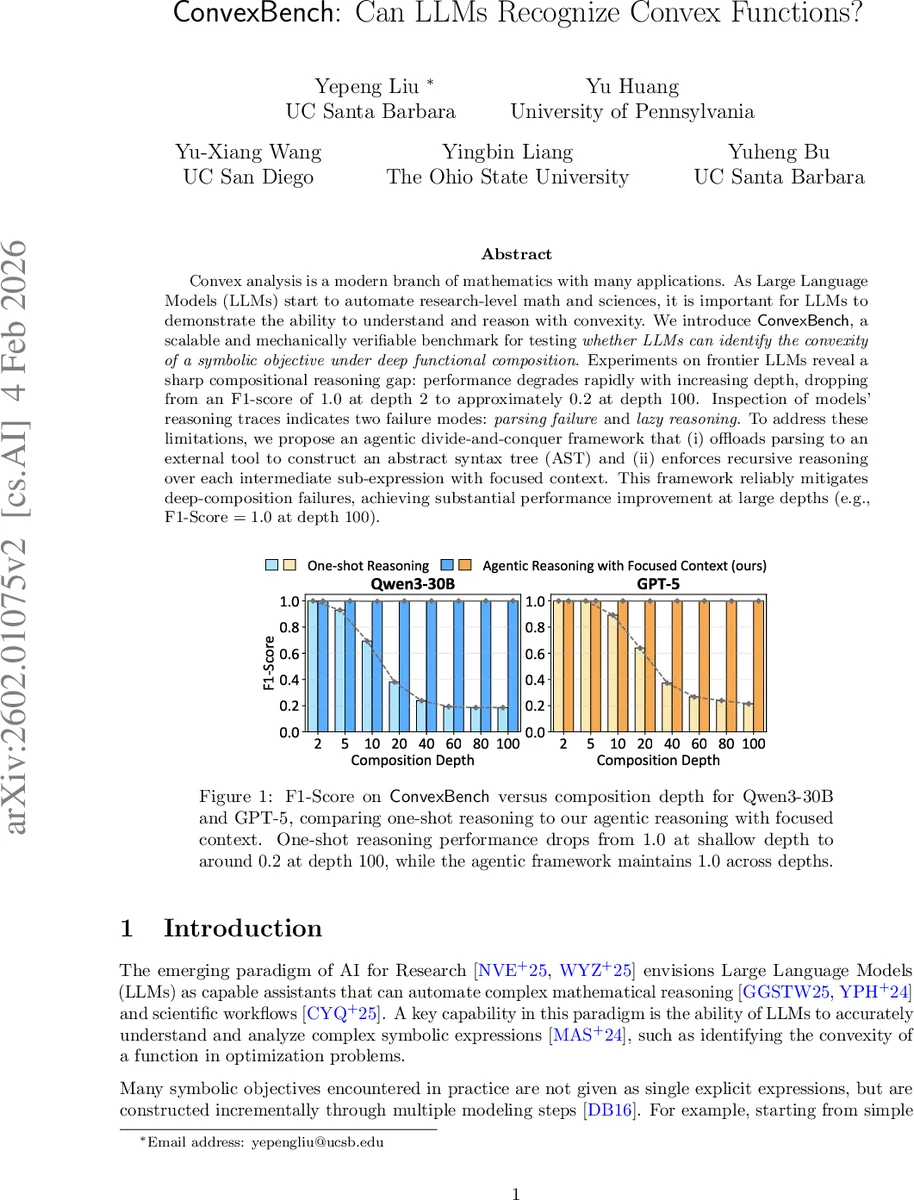
Convex analysis is a modern branch of mathematics with many applications. As Large Language Models (LLMs) start to automate research-level math and sciences, it is important for LLMs to demonstrate the ability to understand and reason with convexity. We introduce \cb, a scalable and mechanically verifiable benchmark for testing \textit{whether LLMs can identify the convexity of a symbolic objective under deep functional composition.} Experiments on frontier LLMs reveal a sharp compositional reasoning gap: performance degrades rapidly with increasing depth, dropping from an F1-score of $1.0$ at depth $2$ to approximately $0.2$ at depth $100$. Inspection of models’ reasoning traces indicates two failure modes: \textit{parsing failure} and \textit{lazy reasoning}. To address these limitations, we propose an agentic divide-and-conquer framework that (i) offloads parsing to an external tool to construct an abstract syntax tree (AST) and (ii) enforces recursive reasoning over each intermediate sub-expression with focused context. This framework reliably mitigates deep-composition failures, achieving substantial performance improvement at large depths (e.g., F1-Score $= 1.0$ at depth $100$).
💡 Research Summary
The paper “ConvexBench: Can LLMs Recognize Convex Functions?” introduces a novel, mechanically verifiable benchmark designed to probe large language models’ (LLMs) ability to determine the convexity of symbolic objective functions that are built through deep functional composition. The authors construct ConvexBench by first defining a library of elementary “atom” functions (exponential, logarithmic, affine, etc.), each annotated with its curvature (convex, concave, affine, or neither), monotonicity, domain, and range. Using disciplined convex programming (DCP) composition rules, they recursively wrap these atoms to generate composite functions F(D) of controlled depth D (ranging from 2 to 100) and a target curvature label (convex, concave, or neither). Because every composition step respects DCP constraints, the ground‑truth label for each generated expression can be derived automatically; for the “neither” class a Jensen‑inequality counter‑example test is applied to ensure the function truly violates both convexity and concavity.
The benchmark is used to evaluate several state‑of‑the‑art LLMs (e.g., Qwen‑3‑30B, GPT‑5) under a one‑shot setting where the raw symbolic expression is fed to the model and it must output the curvature label. Results show a dramatic compositional reasoning gap: models achieve perfect F1 = 1.0 at depth 2, but performance collapses as depth increases, reaching roughly F1 ≈ 0.2 at depth 100. Error analysis reveals two dominant failure modes. First, parsing failures: long expressions cause the model to lose track of parentheses, operator scopes, and sub‑expression boundaries, leading to incorrect structural interpretations. Second, lazy reasoning: the model often relies on shallow heuristics, assumes properties without verification, or focuses on a small part of the expression while ignoring the rest, causing rule propagation errors that cascade through the composition tree.
To address these shortcomings, the authors propose an “agentic divide‑and‑conquer” framework consisting of two key components. (i) External parsing: a dedicated tool parses the raw expression into an abstract syntax tree (AST) and supplies the AST to the LLM, eliminating structural ambiguity. (ii) Recursive, focused‑context reasoning: the AST is traversed recursively; each node (sub‑expression) is treated as an independent sub‑task, and the model is prompted with a context that contains only the relevant sub‑expression and its immediate dependencies. This forces the model to apply DCP rules step‑by‑step, verify intermediate curvature and monotonicity, and propagate the results upward. The framework can be implemented as a multi‑agent system where a “planner” decomposes the task, a “parser” builds the AST, and a “verifier” performs the recursive checks.
Empirical evaluation shows that the agentic framework completely closes the compositional gap: both Qwen‑3‑30B and GPT‑5 achieve F1 = 1.0 even at depth 100, matching their shallow‑depth performance. The authors also conduct ablations demonstrating that (a) providing the AST alone yields substantial gains, but (b) without recursive focused reasoning the models still falter on very deep compositions, confirming the necessity of both components.
The paper’s contributions are threefold: (1) a scalable, mechanically verified dataset of convex, concave, and non‑convex symbolic functions with controllable depth; (2) a systematic evaluation of modern LLMs that uncovers a sharp degradation in structural parsing and long‑horizon reasoning; (3) an agentic, divide‑and‑conquer methodology that leverages external parsing and recursive focused context to achieve perfect accuracy on deep compositions. By exposing and remedying the limitations of current LLMs in a mathematically rigorous setting, the work provides valuable insights for deploying LLMs in research‑level mathematics, optimization, and scientific workflows where reliable symbolic reasoning is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment