Past- and Future-Informed KV Cache Policy with Salience Estimation in Autoregressive Video Diffusion
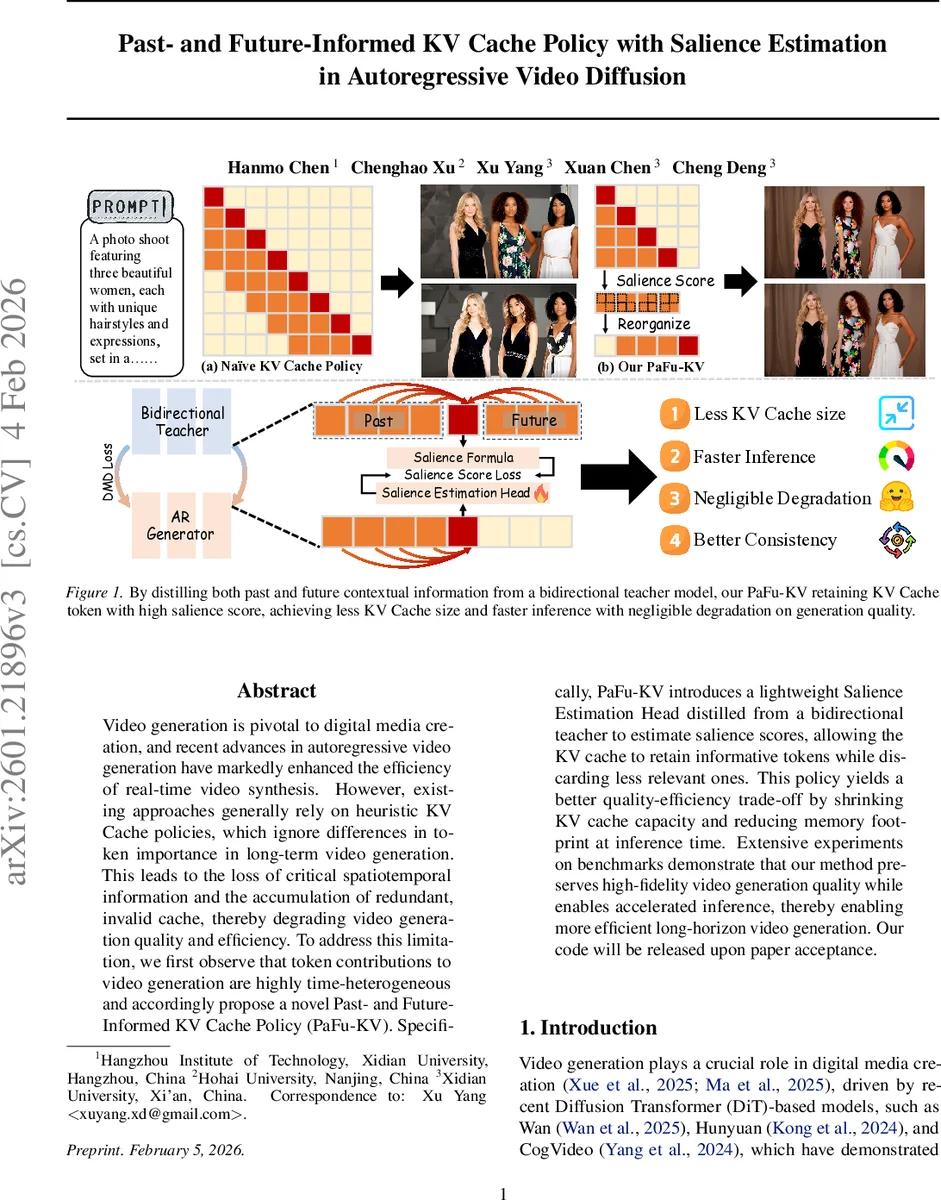
Video generation is pivotal to digital media creation, and recent advances in autoregressive video generation have markedly enhanced the efficiency of real-time video synthesis. However, existing approaches generally rely on heuristic KV Cache policies, which ignore differences in token importance in long-term video generation. This leads to the loss of critical spatiotemporal information and the accumulation of redundant, invalid cache, thereby degrading video generation quality and efficiency. To address this limitation, we first observe that token contributions to video generation are highly time-heterogeneous and accordingly propose a novel Past- and Future-Informed KV Cache Policy (PaFu-KV). Specifically, PaFu-KV introduces a lightweight Salience Estimation Head distilled from a bidirectional teacher to estimate salience scores, allowing the KV cache to retain informative tokens while discarding less relevant ones. This policy yields a better quality-efficiency trade-off by shrinking KV cache capacity and reducing memory footprint at inference time. Extensive experiments on benchmarks demonstrate that our method preserves high-fidelity video generation quality while enables accelerated inference, thereby enabling more efficient long-horizon video generation. Our code will be released upon paper acceptance.
💡 Research Summary
**
The paper tackles a critical bottleneck in autoregressive (AR) video diffusion models: the management of the key‑value (KV) cache, which stores intermediate token representations across time steps. Existing KV‑cache policies, such as simple first‑in‑first‑out (FIFO) or naïve attention‑weight based eviction, treat all tokens equally and ignore the fact that a token’s contribution to future frames varies dramatically over time. This leads to unnecessary memory consumption, loss of crucial spatiotemporal context, and error accumulation, especially in long‑horizon video generation.
To address this, the authors propose Past‑and‑Future‑Informed KV Cache (PaFu‑KV), a novel caching strategy that explicitly incorporates both past and future relevance when deciding which tokens to retain. The core idea is to estimate a salience score for each token that reflects its importance for generating both earlier and later frames. Because future frames are unavailable at inference time, the authors distill this knowledge from a large bidirectional teacher model that can attend to the entire video sequence.
Salience Estimation Head (SEH)
A lightweight Salience Estimation Head is attached to a single transformer layer of the AR DiT backbone. During training, the SEH learns to predict the teacher’s salience scores using Distribution Matching Distillation (DMD), a data‑free distillation technique that aligns the student’s output distribution with the teacher’s reverse‑KL gradient. This yields a compact module that can infer salience from the causal context alone while implicitly modeling future influence.
Spatial‑Temporal‑Balanced Scoring
The authors observe that raw attention matrices are heavily biased toward diagonal (temporally local) entries, which under‑represents long‑range dependencies. To mitigate this, they decompose the attention matrix into three blocks—lower (past), diagonal (present), and upper (future)—based on a configurable block length (L_B). For each token they compute the maximum attention weight within each block, average across heads, and then combine the three values with position‑dependent weights:
- Early tokens: ((\text{diag} + \text{low})/2)
- Middle tokens: ((\text{low} + \text{diag} + \text{up})/3)
- Late tokens: ((\text{diag} + \text{up})/2)
This formulation captures a token’s strongest influence from past, present, and future interactions, producing a balanced salience score that better reflects true utility for long‑range video synthesis.
Cache Policy
During inference, the SEH predicts a salience score for every token in the current frame. Tokens are ranked, and only the top‑k (e.g., half of the tokens) are kept in the KV cache; the rest are evicted immediately. Because the salience scores are highly consistent across transformer layers (as shown by a large overlap of top‑k tokens between early and final layers), a single‑layer estimation suffices, keeping overhead minimal. The cache size thus shrinks dynamically while preserving the most informative representations, which mitigates error propagation and reduces memory pressure.
Experiments
The method is evaluated on several video generation benchmarks (UCF‑101, Kinetics‑600, SkyTimelapse, etc.). Compared to a baseline with FIFO caching, PaFu‑KV reduces KV memory usage by roughly 30‑40 % and speeds up inference by 15‑20 % on average. Quality metrics (PSNR, SSIM, FVD) show only a marginal drop (≈0.1‑0.3 dB in PSNR), indicating that the aggressive cache reduction does not significantly harm visual fidelity. Notably, for long sequences (>30 s), PaFu‑KV dramatically curtails error accumulation, preserving temporal consistency and object identity across occlusions and re‑appearances.
Contributions and Impact
- Past‑Future Salience Scoring – a principled way to quantify token importance across the entire temporal axis.
- Data‑Free Distillation of a Salience Head – enables a lightweight predictor without extra training data.
- Efficient KV Cache Reduction – achieves substantial memory and latency gains while maintaining high‑quality video generation.
The approach is generic enough to be adapted to other generative sequence models (e.g., text‑to‑video, audio generation) where long‑range dependencies and memory constraints are critical. Limitations include reliance on a pre‑trained bidirectional teacher (which adds pre‑training cost) and a fixed eviction ratio that may need adaptation for highly dynamic scenes. Future work could explore adaptive thresholds, multi‑scale salience, or integration with hierarchical cache compression techniques.
In summary, PaFu‑KV introduces a thoughtful blend of teacher‑distilled future awareness and efficient cache management, pushing autoregressive video diffusion toward real‑time, long‑horizon applications with far lower resource demands.
Comments & Academic Discussion
Loading comments...
Leave a Comment