Probing Memes in LLMs: A Paradigm for the Entangled Evaluation World
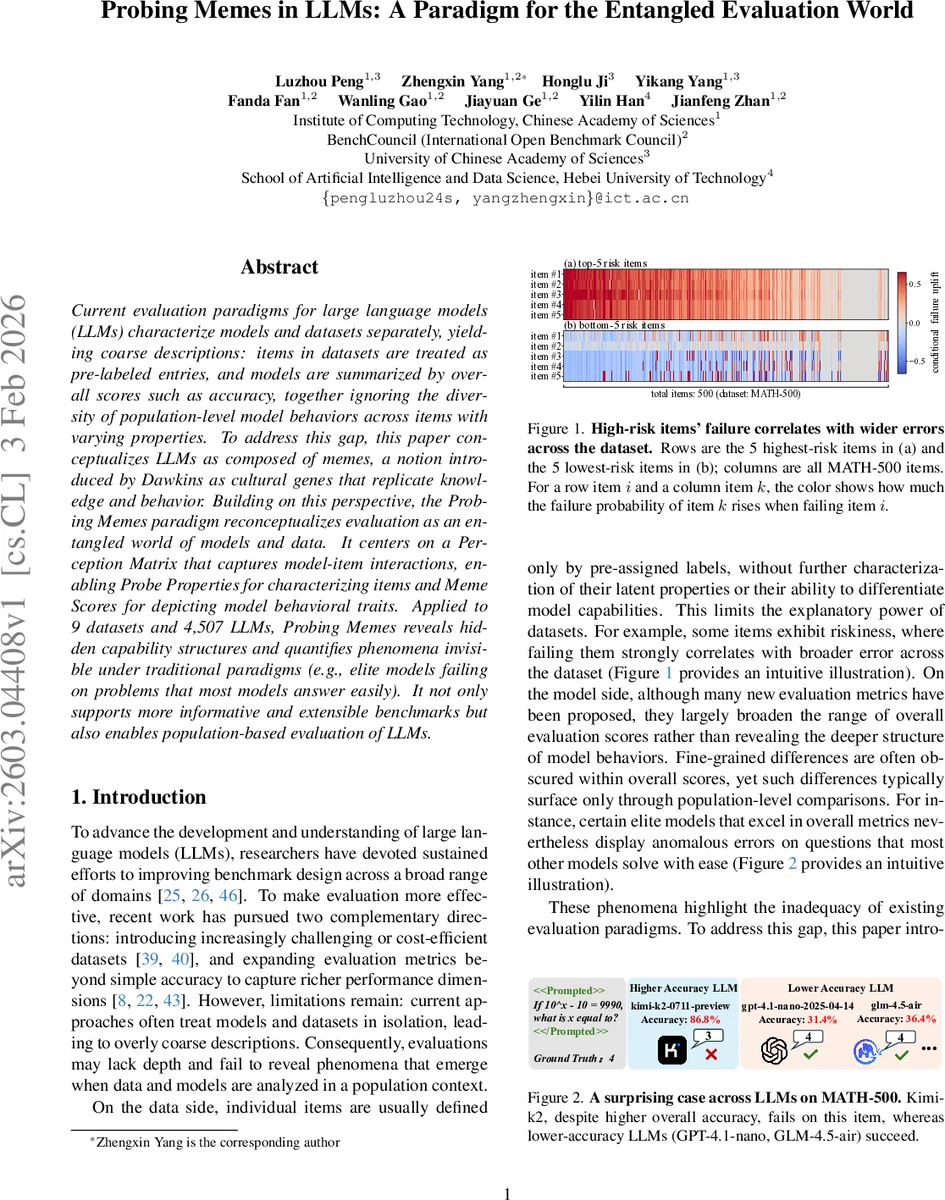
Current evaluation paradigms for large language models (LLMs) characterize models and datasets separately, yielding coarse descriptions: items in datasets are treated as pre-labeled entries, and models are summarized by overall scores such as accuracy, together ignoring the diversity of population-level model behaviors across items with varying properties. To address this gap, this paper conceptualizes LLMs as composed of memes, a notion introduced by Dawkins as cultural genes that replicate knowledge and behavior. Building on this perspective, the Probing Memes paradigm reconceptualizes evaluation as an entangled world of models and data. It centers on a Perception Matrix that captures model-item interactions, enabling Probe Properties for characterizing items and Meme Scores for depicting model behavioral traits. Applied to 9 datasets and 4,507 LLMs, Probing Memes reveals hidden capability structures and quantifies phenomena invisible under traditional paradigms (e.g., elite models failing on problems that most models answer easily). It not only supports more informative and extensible benchmarks but also enables population-based evaluation of LLMs.
💡 Research Summary
The paper introduces a novel evaluation framework for large language models (LLMs) called the “Probing Memes” paradigm, which reconceptualizes model assessment as an entangled world shaped jointly by data items and models. Traditional evaluation practices treat datasets as static collections of pre‑labeled examples and summarize model performance with a single overall metric such as accuracy. This approach obscures the diversity of model behaviors across items with varying properties and fails to reveal nuanced phenomena, such as elite models making systematic errors on questions that most other models solve easily.
The authors borrow Richard Dawkins’ notion of “memes” as cultural replicators and extend it metaphorically to LLM evaluation. In this view, each model is composed of a set of latent behavioral units—memes—while each data item acts as a “Meme Probe” designed to elicit specific memes. By running every model on every probe, they construct a binary Perception Matrix P (size n × m, where n is the number of probes and m the number of models). Each entry Pij indicates whether model j answered probe i correctly. This matrix captures the population‑level success/failure pattern for each item and serves as the empirical interface between unobserved memes and observable model behavior.
From the Perception Matrix, the authors derive six Probe Properties (MPPs) that quantify intrinsic characteristics of each probe:
- Difficulty – the proportion of models that fail the probe, providing a population‑based difficulty baseline.
- Risk – measures how failure on a probe raises the failure probability on many other probes, using a Certainty‑Factor‑style conditional association.
- Surprise – captures anomalous patterns where strong models fail easy probes or weak models succeed on hard probes; it combines log‑scaled difficulty with model ability.
- Uniqueness – the average Hamming dissimilarity of a probe’s perception span relative to all other probes; high values indicate a distinct failure/success pattern.
- Typicality – derived from hierarchical clustering of probes; probes that are central to a cluster (high intra‑cluster similarity) receive high typicality scores.
- Bridge – based on the Participation Coefficient, it quantifies how evenly a probe’s similarity mass is distributed across multiple clusters; high bridge values indicate cross‑cluster connectivity.
These six dimensions form a property space A. By selecting subsets of properties and applying a construction operator f, the framework defines “Meme Scores” (MS) for each model. Simple 1‑dimensional scores map directly from individual MPPs (e.g., a Difficulty score reflects how well a model performs on difficult probes). More expressive 2‑dimensional scores combine two properties (e.g., Mastery = f(typicality, difficulty)), and a 3‑dimensional score such as “Caution” combines typicality, the complement of difficulty, and risk to capture a model’s propensity to avoid easy yet risky items.
The authors validate the paradigm on two experimental settings:
-
Curated Population – nine publicly available datasets (including MA TH‑500, MMLU‑Redux, SimpleQA) and 28 models from 11 institutions. Analyses at the probe level reveal that certain datasets contain many “hard‑but‑solved‑by‑weak” items (high surprise), while risk items strongly correlate with broader error propagation across the dataset. Model‑level analyses show that models with similar overall accuracies can have markedly different Meme Scores, indicating distinct behavioral traits such as specialization on easy‑but‑risky items (captured by the Caution score).
-
Open LLM Population – data from the Open LLM Leaderboard covering six datasets and 4,479 models. Even at this massive scale, the Perception Matrix remains tractable, and the derived Meme Scores preserve interpretability. The authors demonstrate that Meme Scores can be used for principled model selection, clustering models by behavioral traits, and predicting performance on unseen tasks.
Key findings include:
- Hidden capability structures – Models that appear equivalent under traditional metrics diverge on specific meme dimensions, revealing latent strengths and weaknesses.
- Elite‑model anomalies – High‑performing models sometimes fail on high‑risk, low‑difficulty probes that weaker models answer correctly, a phenomenon invisible to aggregate accuracy.
- Benchmark design insights – By quantifying probe risk, uniqueness, and bridge properties, researchers can construct more discriminative benchmarks that surface model weaknesses rather than merely aggregating easy items.
The paper argues that moving from static, label‑centric evaluation to an interaction‑centric, population‑based paradigm yields richer, more actionable insights. Limitations are acknowledged: the current binary Perception Matrix does not capture graded correctness or generative quality, and some hyperparameters (e.g., scaling factors, clustering thresholds) require dataset‑specific tuning. Future work is suggested to extend the framework to multi‑label or partial‑credit settings, automate probe generation, and explore richer meme representations beyond binary correctness.
In summary, “Probing Memes” offers a systematic, extensible methodology for dissecting LLM behavior at a fine‑grained level, enabling researchers to understand not just how well a model performs overall, but why it performs that way across diverse item characteristics. This paradigm promises to guide more nuanced model development, benchmark construction, and ultimately a deeper scientific understanding of large language models.
Comments & Academic Discussion
Loading comments...
Leave a Comment