EventNeuS: 3D Mesh Reconstruction from a Single Event Camera
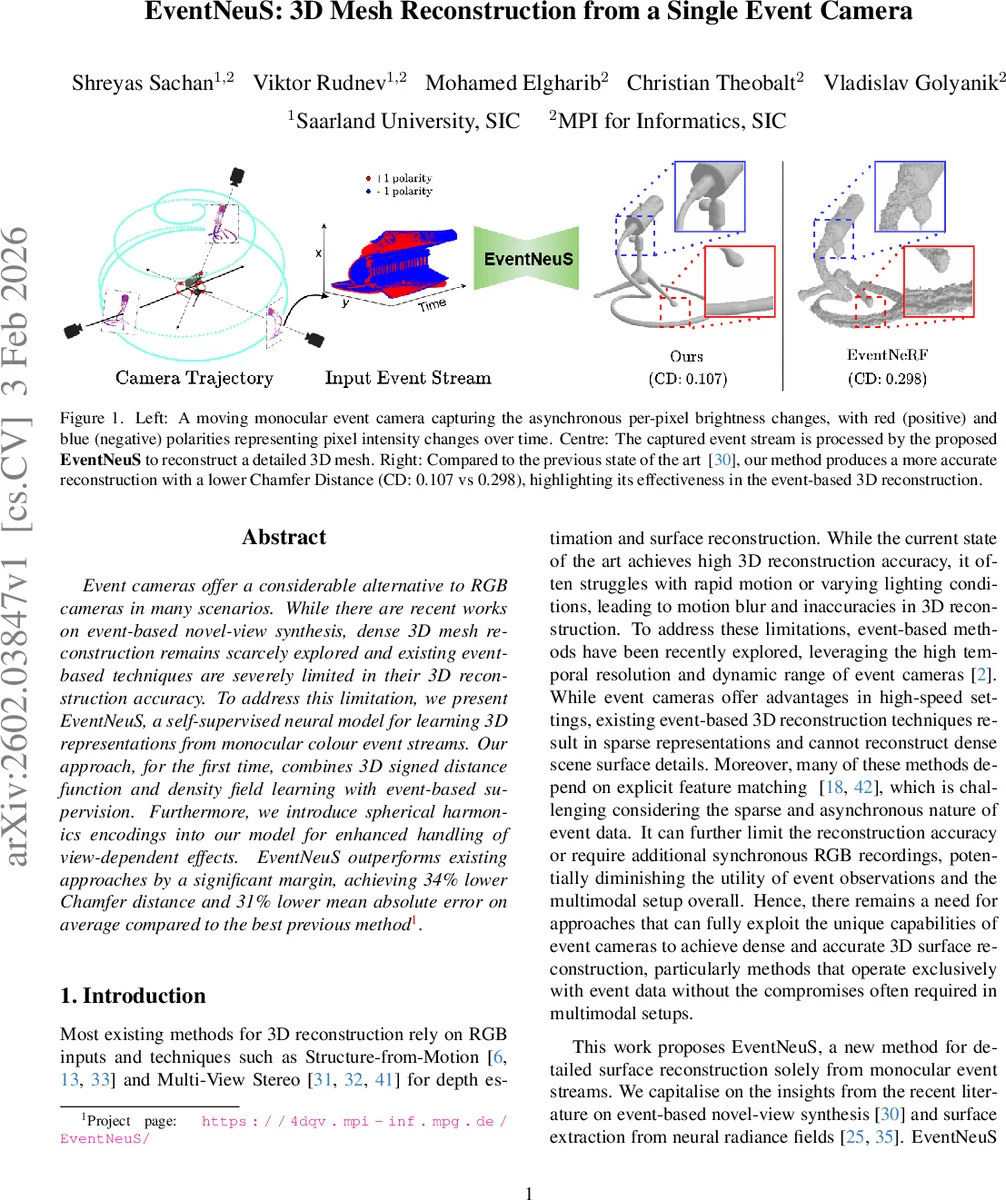
Event cameras offer a considerable alternative to RGB cameras in many scenarios. While there are recent works on event-based novel-view synthesis, dense 3D mesh reconstruction remains scarcely explored and existing event-based techniques are severely limited in their 3D reconstruction accuracy. To address this limitation, we present EventNeuS, a self-supervised neural model for learning 3D representations from monocular colour event streams. Our approach, for the first time, combines 3D signed distance function and density field learning with event-based supervision. Furthermore, we introduce spherical harmonics encodings into our model for enhanced handling of view-dependent effects. EventNeuS outperforms existing approaches by a significant margin, achieving 34% lower Chamfer distance and 31% lower mean absolute error on average compared to the best previous method.
💡 Research Summary
**
EventNeuS introduces a self‑supervised neural framework that reconstructs dense 3D meshes from a single monocular colour event camera, without any RGB frames or explicit feature matching. Building on the NeuS implicit surface representation, the method jointly learns a signed distance function (SDF) and a neural radiance field (NeRF) using only the asynchronous brightness‑change information recorded by the event sensor.
The core technical contribution is a novel event‑driven loss that aligns temporal differences between two rendered images with the accumulated event frame over the same interval. Specifically, the logarithmic intensity difference log Ċ(t₁) − log Ċ(t₀) is compared to the polarity‑weighted event map via a mean‑squared error, faithfully modelling the event camera’s response to logarithmic brightness changes. This loss provides direct supervision for geometry (through the SDF) and appearance (through the radiance field) while remaining fully self‑supervised.
To handle view‑dependent effects efficiently, EventNeuS replaces the standard high‑dimensional positional encoding of view directions with spherical harmonics (SH) encoding. SH compactly captures low‑frequency angular variations, reducing computational overhead and improving robustness against the sparse, noisy nature of event data. The SH‑encoded view direction is fused with SDF features and surface normals to predict view‑dependent colour.
Training proceeds with hierarchical importance sampling along each camera ray and a frequency‑annealing schedule for positional encodings. Early training focuses on low‑frequency geometry, preventing over‑fitting to noisy events; later stages progressively introduce higher‑frequency bands, allowing fine surface details to emerge. The SDF gradient is transformed into a density field via a logistic function, and volume rendering integrates colour and opacity to produce the final pixel values. An Eikonal regularisation term enforces unit‑norm gradients, ensuring a well‑behaved SDF and smooth surfaces.
The authors also contribute a synthetic dataset generated by a spherical‑spiral camera trajectory, providing ground‑truth meshes and event streams for quantitative evaluation. On both synthetic and real‑world sequences, EventNeuS achieves a 34 % reduction in Chamfer Distance and a 31 % reduction in mean absolute error compared with the strongest prior methods (e.g., EventNeRF, EvA‑C3D, Event‑ID). Qualitative results show markedly sharper edges, more accurate silhouettes, and faithful reconstruction of fine geometric structures, even under fast motion and low‑light conditions where traditional RGB‑based pipelines fail.
In summary, EventNeuS makes three pivotal advances: (1) a self‑supervised loss that directly ties event‑camera brightness changes to SDF‑based surface learning, (2) the first use of spherical harmonics encoding for view‑dependent modelling in event‑driven 3D reconstruction, and (3) a training strategy combining hierarchical sampling and frequency annealing to extract high‑frequency details from sparse event data. By demonstrating that a single event camera can produce high‑quality dense meshes comparable to or surpassing RGB‑centric approaches, the work opens new avenues for 3D perception in high‑speed, high‑dynamic‑range, and low‑light scenarios.
Comments & Academic Discussion
Loading comments...
Leave a Comment