DiscoverLLM: From Executing Intents to Discovering Them
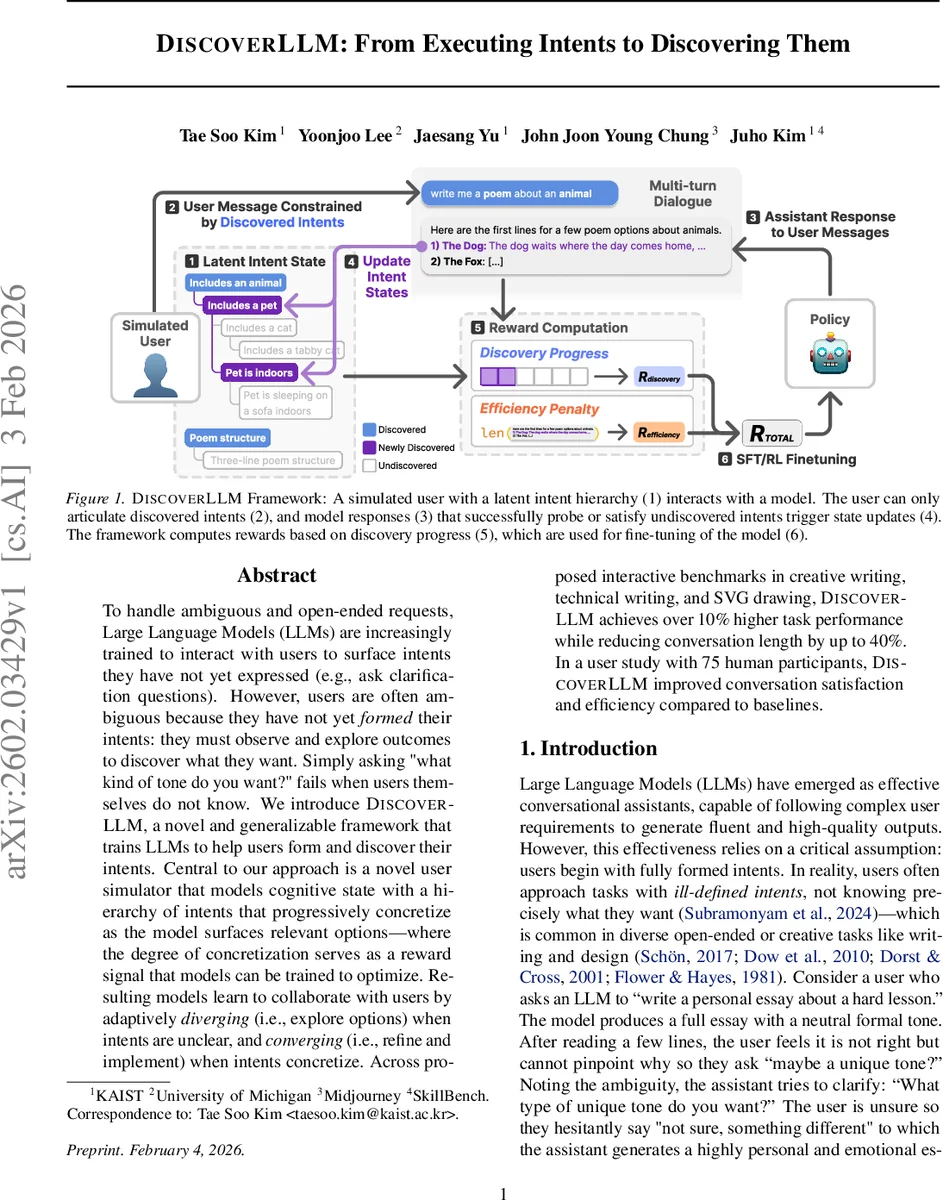
To handle ambiguous and open-ended requests, Large Language Models (LLMs) are increasingly trained to interact with users to surface intents they have not yet expressed (e.g., ask clarification questions). However, users are often ambiguous because they have not yet formed their intents: they must observe and explore outcomes to discover what they want. Simply asking “what kind of tone do you want?” fails when users themselves do not know. We introduce DiscoverLLM, a novel and generalizable framework that trains LLMs to help users form and discover their intents. Central to our approach is a novel user simulator that models cognitive state with a hierarchy of intents that progressively concretize as the model surfaces relevant options – where the degree of concretization serves as a reward signal that models can be trained to optimize. Resulting models learn to collaborate with users by adaptively diverging (i.e., explore options) when intents are unclear, and converging (i.e., refine and implement) when intents concretize. Across proposed interactive benchmarks in creative writing, technical writing, and SVG drawing, DiscoverLLM achieves over 10% higher task performance while reducing conversation length by up to 40%. In a user study with 75 human participants, DiscoverLLM improved conversation satisfaction and efficiency compared to baselines.
💡 Research Summary
DiscoverLLM tackles a fundamental limitation of current conversational large language models (LLMs): they assume that users begin a dialogue with fully formed intents. In many open‑ended tasks—creative writing, design, technical documentation—users often do not know exactly what they want until they see concrete examples. The paper therefore reframes the problem as “intent discovery” rather than “intent elicitation.”
The core contribution is a user simulator that encodes a latent intent hierarchy. Each intent is a node in a tree, ranging from abstract high‑level goals (e.g., “write a poem”) to concrete specifications (e.g., “three‑line haiku about a tabby cat indoors”). At turn t the simulated user possesses a set Iₜ of discovered nodes and a refinement set R(Iₜ) consisting of undiscovered children of those nodes. The user can only articulate intents that are already in Iₜ; they cannot answer a question about an intent they have not yet recognized. When the assistant’s response rₜ either directly asks about a refinement or indirectly exposes it through sample outputs, the corresponding node transitions from “undiscovered → emerging → discovered.”
A reward function is built on two axes: (1) Intent‑Discovery Reward, which measures how many new concrete intents the model surfaces, and (2) Intent‑Satisfaction Reward, which evaluates whether the final artifact fulfills the full set I_T. The reward is computed automatically from the simulator’s state, enabling large‑scale generation of training data.
Training proceeds in two stages. First, supervised fine‑tuning (SFT) on dialogues generated by the simulator gives the model a basic ability to propose options and ask probing questions. Second, reinforcement learning from human feedback (RLHF) optimizes the dual‑objective reward, encouraging the model to balance exploration (divergence) with convergence (refinement). The framework is applied to two base models—Llama‑3.1‑8B‑Instruct and Qwen‑3‑8B—and evaluated on three multi‑turn benchmarks: (a) creative writing (animal‑themed poems), (b) technical writing (instruction manuals), and (c) SVG drawing (icon design).
Across all tasks DiscoverLLM outperforms strong baselines (standard multi‑turn prompting, prior RLHF models) by roughly 10 % in task success rate, reduces conversation length by 30‑40 %, and achieves an 83 % increase in “interactivity” scores judged by auxiliary LLM evaluators. A user study with 75 crowd‑workers further confirms practical benefits: participants using DiscoverLLM complete tasks 22 % faster and report a 1.4‑point increase in satisfaction on a 5‑point Likert scale. Qualitative feedback highlights the model’s ability to “anticipate latent preferences” by presenting diverse options that help users crystallize their goals.
The paper also discusses limitations. The intent hierarchy is assumed monotonic—once an intent is discovered it is never abandoned—so the framework does not model intent revision or abandonment. The simulator’s latent intents are pre‑specified, which may not capture the full richness of human cognition, and the tree structure may be insufficient for non‑hierarchical or multi‑relational intent spaces. Future work is suggested on non‑monotonic intent dynamics, richer cognitive models, and zero‑shot generalization to entirely new domains.
In summary, DiscoverLLM introduces a principled method for training LLMs to act as collaborative explorers that help users discover and refine their own goals. By embedding a hierarchical intent model into a reward‑driven training loop, it enables more efficient, user‑centric dialogues and opens a new research direction for intent‑discovery‑oriented conversational AI.
Comments & Academic Discussion
Loading comments...
Leave a Comment