Seeing Through the Chain: Mitigate Hallucination in Multimodal Reasoning Models via CoT Compression and Contrastive Preference Optimization
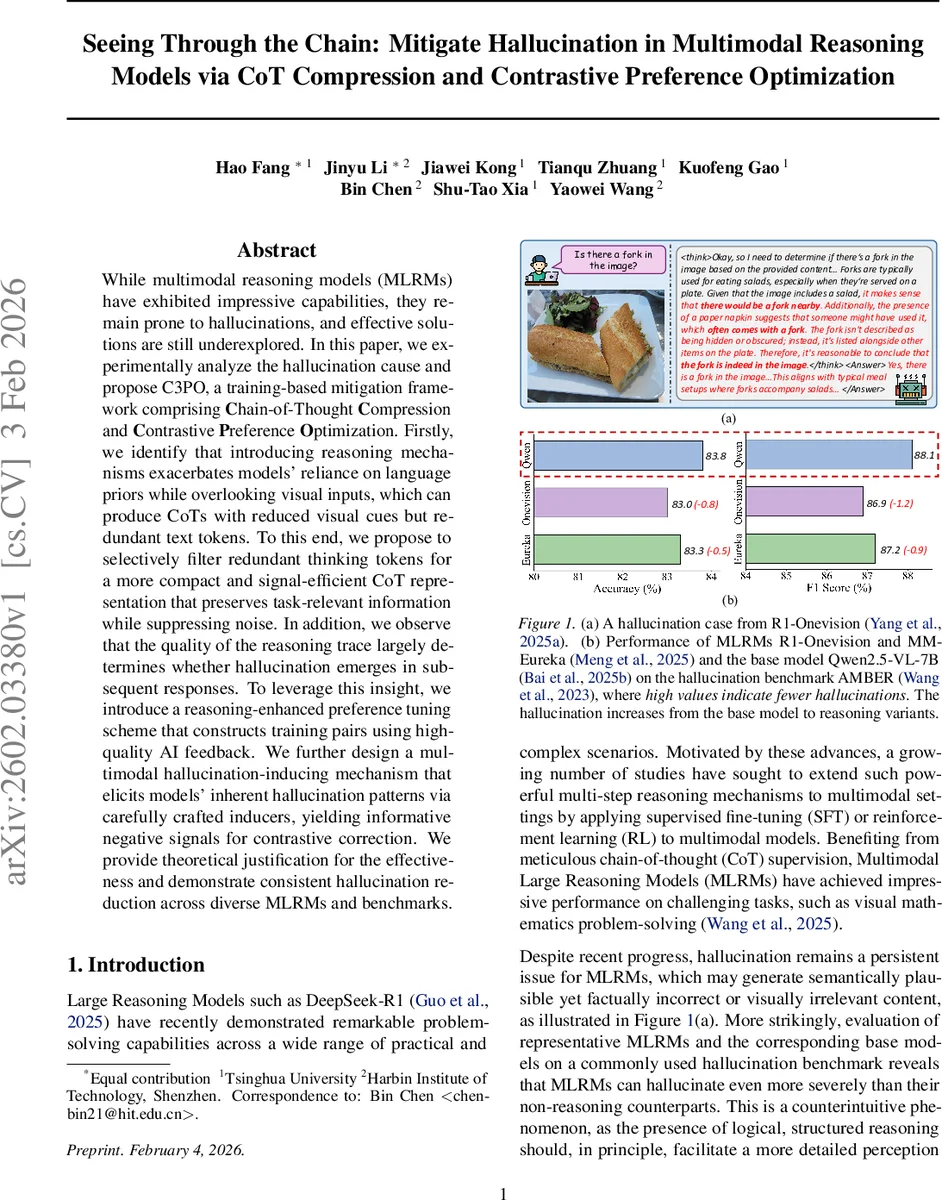
While multimodal reasoning models (MLRMs) have exhibited impressive capabilities, they remain prone to hallucinations, and effective solutions are still underexplored. In this paper, we experimentally analyze the hallucination cause and propose C3PO, a training-based mitigation framework comprising \textbf{C}hain-of-Thought \textbf{C}ompression and \textbf{C}ontrastive \textbf{P}reference \textbf{O}ptimization. Firstly, we identify that introducing reasoning mechanisms exacerbates models’ reliance on language priors while overlooking visual inputs, which can produce CoTs with reduced visual cues but redundant text tokens. To this end, we propose to selectively filter redundant thinking tokens for a more compact and signal-efficient CoT representation that preserves task-relevant information while suppressing noise. In addition, we observe that the quality of the reasoning trace largely determines whether hallucination emerges in subsequent responses. To leverage this insight, we introduce a reasoning-enhanced preference tuning scheme that constructs training pairs using high-quality AI feedback. We further design a multimodal hallucination-inducing mechanism that elicits models’ inherent hallucination patterns via carefully crafted inducers, yielding informative negative signals for contrastive correction. We provide theoretical justification for the effectiveness and demonstrate consistent hallucination reduction across diverse MLRMs and benchmarks.
💡 Research Summary
The paper tackles the persistent hallucination problem in Multimodal Reasoning Models (MLRMs), which becomes more severe when these models are equipped with explicit Chain‑of‑Thought (CoT) reasoning. Through two targeted analyses, the authors first show that adding a reasoning stage shifts attention away from visual tokens toward textual ones, amplifying reliance on language priors and producing CoTs that contain many redundant words with little visual grounding. Second, they demonstrate a causal link: hallucinated CoTs dramatically increase the likelihood that the final answer will also be hallucinated, whereas high‑quality CoTs almost guarantee hallucination‑free answers.
Motivated by these findings, the authors propose C3PO, a two‑stage training framework.
Stage 1 – CoT Compression. Inspired by the Information Bottleneck principle, the authors treat the CoT as an intermediate representation that should retain only visual‑relevant information. They employ LLMlingua‑2, a pretrained token‑importance model, to score each token in a generated CoT. Tokens below a chosen percentile (γ) are pruned, yielding a compact chain z′. The model is then fine‑tuned (LoRA‑based SFT) to generate answers conditioned on these compressed chains. This step alone already restores some visual attention and reduces hallucinations without any extra supervision.
Stage 2 – Contrastive Preference Optimization. The authors construct a preference dataset containing (a) positive samples: high‑quality, AI‑enhanced CoTs obtained by asking a strong multimodal LLM (Qwen‑3‑VL) to detect and correct hallucinated sentences, and (b) negative samples: deliberately hallucinated outputs generated via two mechanisms. Visual hallucinations are induced by masking parts of the input image, forcing the model to rely on language priors; textual hallucinations are induced by a prompt that explicitly tells the model to ignore visual evidence. Using Direct Preference Optimization (DPO), the model is trained to prefer the refined CoTs over the original, hallucinated ones. This contrastive learning explicitly penalizes the model’s intrinsic hallucination patterns while reinforcing faithful reasoning.
The authors provide a theoretical justification: compressed CoTs minimize unnecessary information flow (reducing the IB objective), and the contrastive loss adds a high cost to hallucination pathways, steering optimization toward visual grounding.
Empirically, C3PO is evaluated on several state‑of‑the‑art MLRMs (DeepSeek‑R1, R1‑OneVision, MM‑Eureka) across multiple benchmarks (AMBER, CHAIR). Results show a consistent 7–12 percentage‑point reduction in hallucination rates, with the compression‑only variant already achieving ~4 pp improvement and the full C3PO pipeline reaching up to 15 pp reduction. Importantly, answer accuracy is maintained or slightly improved, indicating that the mitigation does not sacrifice performance.
In summary, C3PO offers a principled, data‑efficient solution to multimodal hallucination: it first compresses reasoning chains to preserve essential visual cues, then uses contrastive preference learning with both high‑quality and deliberately induced low‑quality samples to teach the model to recognize and avoid hallucinations. This work advances the reliability of multimodal large‑scale reasoning systems and provides a clear roadmap for future research on grounding‑aware multimodal generation.
Comments & Academic Discussion
Loading comments...
Leave a Comment