Global Geometry Is Not Enough for Vision Representations
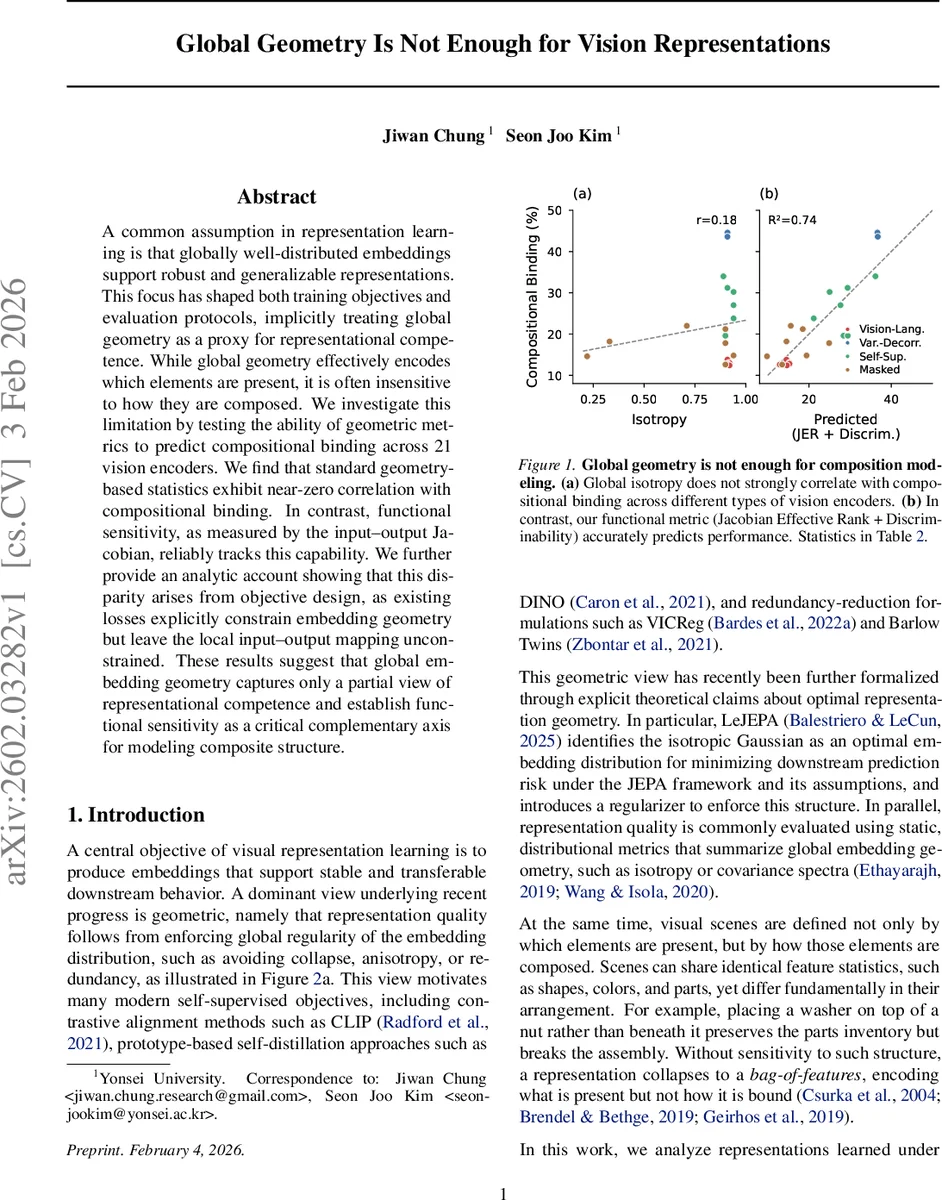
A common assumption in representation learning is that globally well-distributed embeddings support robust and generalizable representations. This focus has shaped both training objectives and evaluation protocols, implicitly treating global geometry as a proxy for representational competence. While global geometry effectively encodes which elements are present, it is often insensitive to how they are composed. We investigate this limitation by testing the ability of geometric metrics to predict compositional binding across 21 vision encoders. We find that standard geometry-based statistics exhibit near-zero correlation with compositional binding. In contrast, functional sensitivity, as measured by the input-output Jacobian, reliably tracks this capability. We further provide an analytic account showing that this disparity arises from objective design, as existing losses explicitly constrain embedding geometry but leave the local input-output mapping unconstrained. These results suggest that global embedding geometry captures only a partial view of representational competence and establish functional sensitivity as a critical complementary axis for modeling composite structure.
💡 Research Summary
The paper challenges the prevailing assumption in visual representation learning that globally well‑distributed embeddings guarantee robust, generalizable representations. While many self‑supervised and supervised objectives explicitly regularize the global geometry of the embedding space—promoting isotropy, uniformity, high participation ratio, or variance decorrelation—this work asks whether such geometric regularity also predicts a model’s ability to encode compositional structure, i.e., how visual elements are bound together.
To answer this, the authors devise a synthetic “Attribute Binding” benchmark that isolates compositional binding from confounding factors such as object detection, texture, or semantics. In this task, a model must match a query to a target based on shape‑position bindings while the colors of the query and target are disjoint, forcing the representation to capture abstract relational information rather than simple feature co‑occurrence. A secondary “Structural Discrimination” probe measures basic sensitivity to whether two images share the same spatial configuration.
The study evaluates 21 pretrained vision encoders spanning eight objective families: contrastive (SimCLR), variance‑decorrelation (Barlow Twins, VICReg), clustering (SwAV), self‑distillation (DINO, DINOv2), masked prediction (MAE, BEiT, I‑JEPA), vision‑language (CLIP, SigLIP, EVA‑CLIP), and supervised (ConvNeXt). These models cover a range of architectures (ResNet‑50, ViT‑S/B/L) and scales, allowing the authors to disentangle effects of objective design from model size.
Three classic global‑geometry metrics are computed on ImageNet‑1k embeddings: Global Participation Ratio (G.PR), Global Isotropy (G.Iso), and Local Isotropy (L.Iso). Their Pearson correlations with binding accuracy are essentially zero (r≈‑0.00, +0.18, +0.05 respectively) and statistically insignificant. In stark contrast, functional sensitivity measured by the effective rank of the input‑output Jacobian (JER) shows a strong positive correlation (r≈0.65, p≈0.001) and explains a substantial portion of variance (R²≈0.43). Moreover, JER also correlates with the structural discrimination probe, indicating that models with richer local input‑output mappings are better at both basic structural detection and higher‑order compositional binding.
The authors provide an analytic account: most existing losses constrain only distribution‑level statistics (e.g., pairwise similarity, variance penalties) and thus shape the embedding cloud but leave the Jacobian—i.e., the mapping from infinitesimal input changes to representation changes—unconstrained. Consequently, two models can exhibit identical isotropy yet differ dramatically in how sensitively they respond to structured input variations, leading to divergent compositional abilities.
To test whether compositional information might be recoverable from a well‑structured embedding via alternative readouts, the paper experiments with k‑nearest‑neighbor retrieval and local PCA projections on frozen representations. Neither method improves binding performance; in many cases they degrade accuracy, suggesting that compositional signals are not concentrated in local neighborhoods or aligned with dominant variance directions.
In summary, the work demonstrates that global embedding geometry captures only a partial view of representational competence: it reflects “what is present” but not “how elements are bound.” Functional sensitivity, quantified by Jacobian effective rank, emerges as a critical complementary axis for evaluating and ultimately designing visual representations that support compositional reasoning. The findings motivate future research to incorporate explicit Jacobian‑based regularizers or functional‑sensitivity‑aware objectives, moving beyond purely geometric diagnostics toward representations that are both globally well‑behaved and locally expressive.
Comments & Academic Discussion
Loading comments...
Leave a Comment