Test-time Recursive Thinking: Self-Improvement without External Feedback
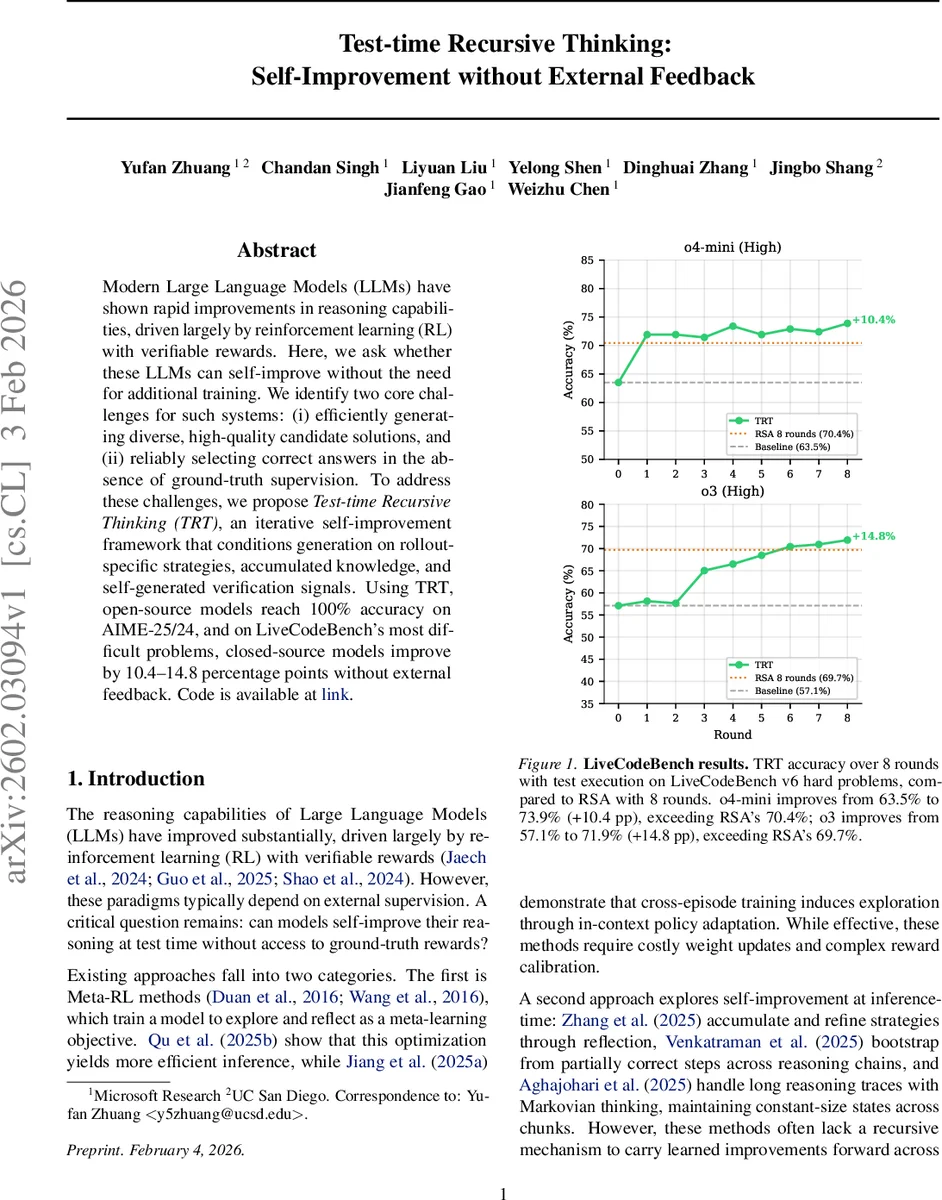
Modern Large Language Models (LLMs) have shown rapid improvements in reasoning capabilities, driven largely by reinforcement learning (RL) with verifiable rewards. Here, we ask whether these LLMs can self-improve without the need for additional training. We identify two core challenges for such systems: (i) efficiently generating diverse, high-quality candidate solutions, and (ii) reliably selecting correct answers in the absence of ground-truth supervision. To address these challenges, we propose Test-time Recursive Thinking (TRT), an iterative self-improvement framework that conditions generation on rollout-specific strategies, accumulated knowledge, and self-generated verification signals. Using TRT, open-source models reach 100% accuracy on AIME-25/24, and on LiveCodeBench’s most difficult problems, closed-source models improve by 10.4-14.8 percentage points without external feedback.
💡 Research Summary
The paper introduces Test‑time Recursive Thinking (TRT), a novel inference‑time self‑improvement framework for large language models (LLMs) that eliminates the need for external reward signals or weight updates. TRT tackles two fundamental obstacles to test‑time self‑improvement: (i) generating a diverse set of high‑quality candidate solutions, and (ii) reliably selecting the correct answer without ground‑truth supervision. The method proceeds in T iterative rounds, each consisting of three stages.
-
Generate – The model produces K rollouts conditioned on (a) an accumulated “knowledge list” that records failure patterns, bugs, and logical pitfalls, and (b) K rollout‑specific “strategies” that the model itself designs based on the current knowledge. Knowledge entries are phrased as negative constraints (“don’ts”) to prune known bad reasoning paths, and the list is kept compact by pruning outdated items each round. Strategy prompts guide each rollout toward a distinct region of the solution space, ensuring purposeful diversity rather than random variation.
-
Select – Without any external ground‑truth, the model evaluates the K candidates using self‑judgment. For mathematical problems (e.g., AIME) the authors exploit the mutual exclusivity of integer answers: previously self‑rejected answers are stored in the knowledge list, and the model checks whether a new answer conflicts with that list. For code generation, the model generates its own unit tests derived from the problem description, executes each candidate, and ranks them by the number of passed tests. Secondary tie‑breakers include code cleanliness, handling of edge cases, and consistency with accumulated knowledge.
-
Reflect – The model compares every non‑selected rollout against the chosen best solution, extracts concrete failure insights (e.g., “off‑by‑one index error”, “missing boundary condition”), and appends these insights to the knowledge list. These distilled insights become part of the context for the next round, preventing the model from repeating the same mistakes and steering future exploration toward unexplored, promising approaches.
The authors evaluate TRT on two challenging benchmarks. In the mathematical reasoning domain, they use the 30 problems from AIME‑2025 (and AIME‑2024 as a secondary set). Open‑source models gpt‑oss‑120b and Qwen3‑235B achieve 100 % accuracy after 64 refinement rounds (K = 1, total 64 rollouts), surpassing Parallel Thinking (majority voting over 64 independent traces) and Recursive Self‑Aggregation (RSA) by 2–7 percentage points in pass@k. The performance is stable across multiple runs and monotonic with the number of rounds.
In the code generation domain, they test on 203 “hard” problems from LiveCodeBench v6. Proprietary models o4‑mini‑high and o3‑high improve their accuracy by +10.4 pp and +14.8 pp respectively after 8 rounds (2 rollouts per round) compared with RSA under the same compute budget. An ablation study shows that the self‑generated test execution contributes roughly 7.4 pp of the gain, confirming the effectiveness of the execution‑based selection signal.
Key contributions of the work include:
- A unified framework that couples strategic exploration (knowledge‑driven, model‑generated strategies) with self‑verification (mutual exclusivity for math, execution tests for code).
- Demonstration that LLMs can perform meta‑learning at inference time purely through context manipulation, without any external reward model or parameter updates.
- Empirical evidence that TRT outperforms strong baselines (parallel sampling with majority vote, RSA) on both reasoning and programming tasks while using comparable computational resources.
The paper also discusses limitations: the knowledge list can grow large, requiring careful pruning; self‑generated tests may miss subtle edge cases, leading to occasional false positives; and the method’s efficiency on smaller models remains to be fully explored. Future directions suggested include automated compression of the knowledge list, hybrid selection that combines self‑verification with external verifiers, and extending TRT to other domains such as scientific literature summarization or legal reasoning.
Overall, Test‑time Recursive Thinking provides a compelling pathway for LLMs to self‑improve during deployment, turning each inference pass into a learning opportunity that refines both the model’s problem‑solving strategies and its internal knowledge base.
Comments & Academic Discussion
Loading comments...
Leave a Comment