Reg4Pru: Regularisation Through Random Token Routing for Token Pruning
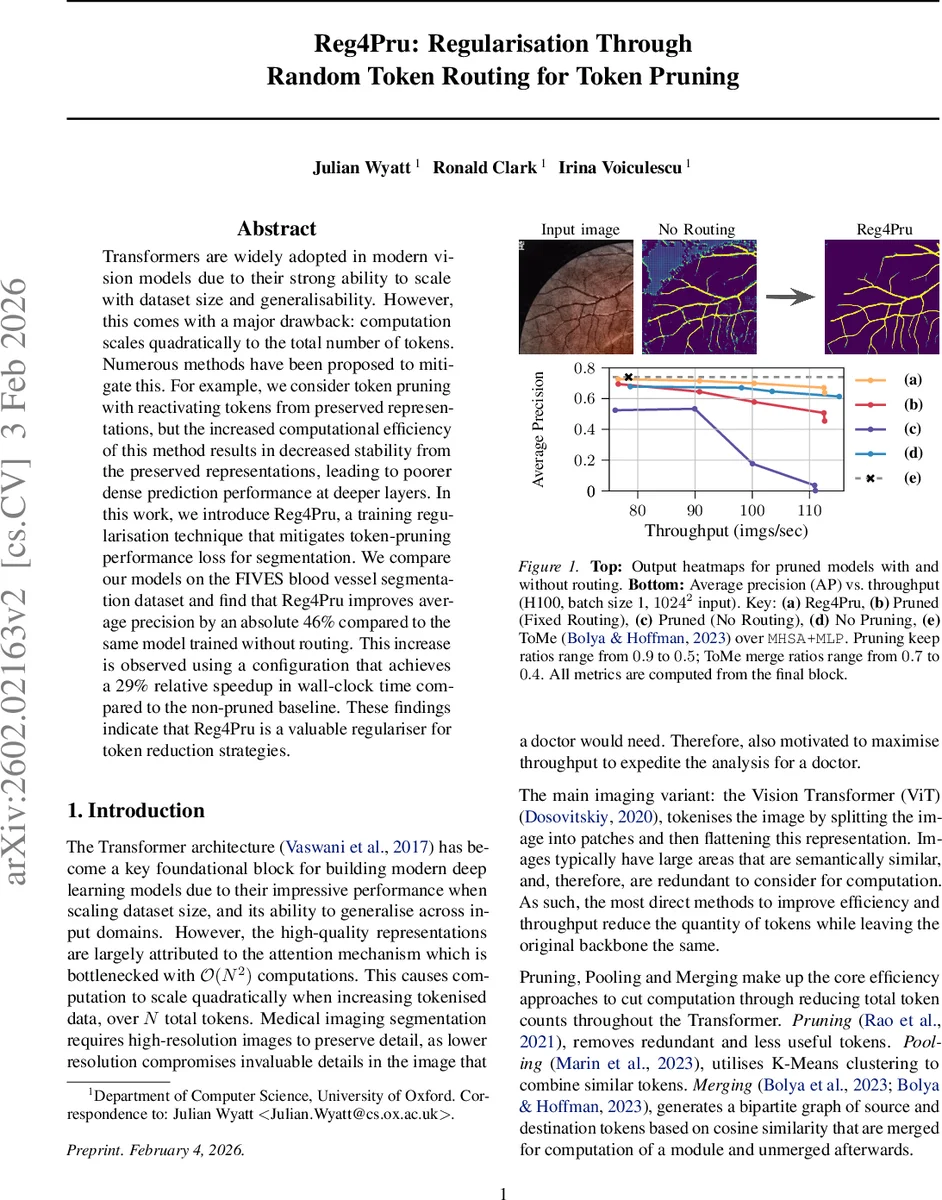
Transformers are widely adopted in modern vision models due to their strong ability to scale with dataset size and generalisability. However, this comes with a major drawback: computation scales quadratically to the total number of tokens. Numerous methods have been proposed to mitigate this. For example, we consider token pruning with reactivating tokens from preserved representations, but the increased computational efficiency of this method results in decreased stability from the preserved representations, leading to poorer dense prediction performance at deeper layers. In this work, we introduce Reg4Pru, a training regularisation technique that mitigates token-pruning performance loss for segmentation. We compare our models on the FIVES blood vessel segmentation dataset and find that Reg4Pru improves average precision by an absolute 46% compared to the same model trained without routing. This increase is observed using a configuration that achieves a 29% relative speedup in wall-clock time compared to the non-pruned baseline. These findings indicate that Reg4Pru is a valuable regulariser for token reduction strategies.
💡 Research Summary
Transformers have become the backbone of modern computer‑vision models, yet their self‑attention mechanism incurs a quadratic cost with respect to the number of input tokens. This makes high‑resolution dense‑prediction tasks such as medical‑image segmentation prohibitively expensive. Token‑pruning, which discards “unimportant” tokens during inference, is a natural way to cut FLOPs, but recent work has shown that when pruned tokens are later re‑activated for pixel‑wise predictions, their representations become unstable, especially in deeper layers. The authors call this phenomenon “depth‑wise instability” and demonstrate it on the FIVES retinal‑vessel segmentation benchmark, where performance drops sharply as pruning depth increases.
To address this, the paper introduces Reg4Pru, a training‑time regularisation technique that mimics pruning by randomly routing tokens through the network. At the start of each forward pass a random interval (
Comments & Academic Discussion
Loading comments...
Leave a Comment