Accurate and Efficient World Modeling with Masked Latent Transformers
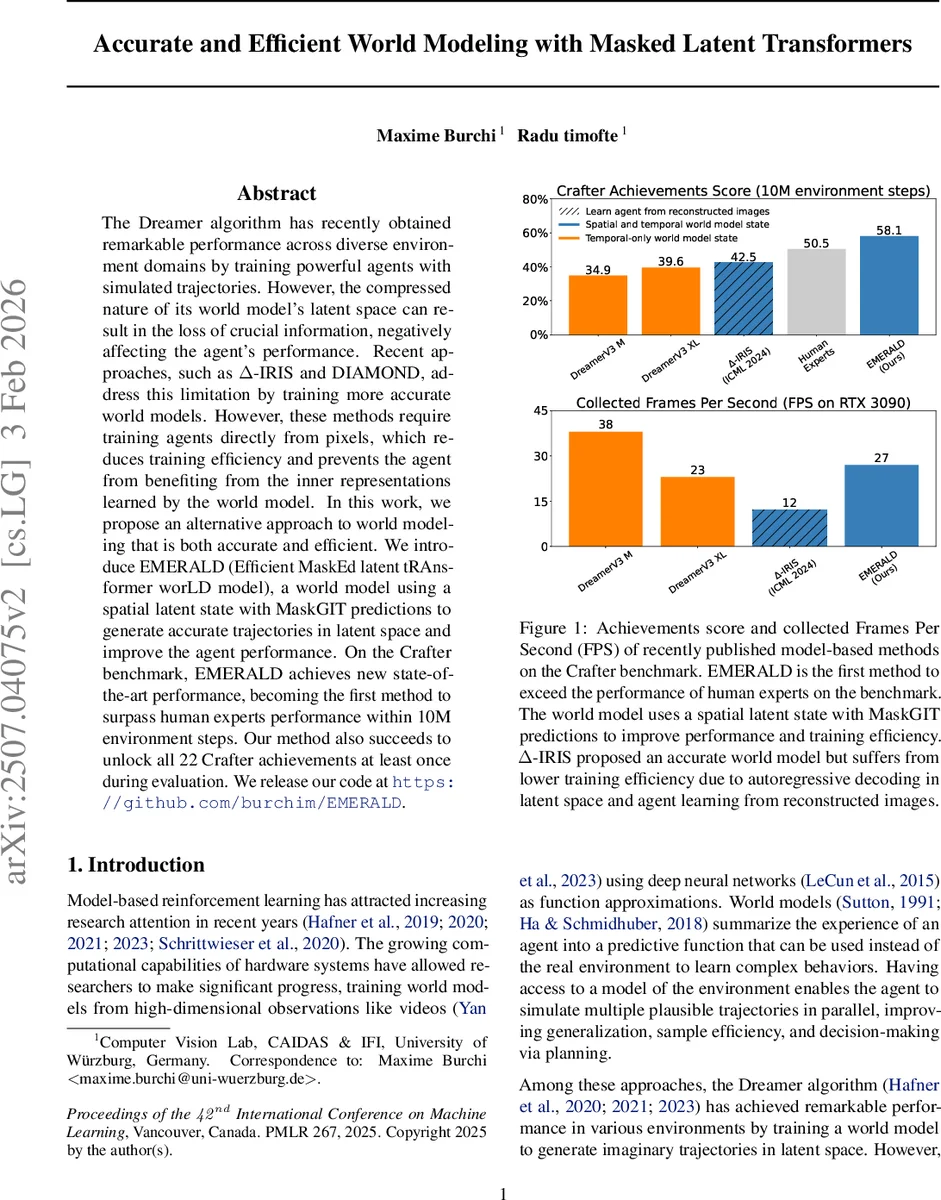
The Dreamer algorithm has recently obtained remarkable performance across diverse environment domains by training powerful agents with simulated trajectories. However, the compressed nature of its world model’s latent space can result in the loss of crucial information, negatively affecting the agent’s performance. Recent approaches, such as $Δ$-IRIS and DIAMOND, address this limitation by training more accurate world models. However, these methods require training agents directly from pixels, which reduces training efficiency and prevents the agent from benefiting from the inner representations learned by the world model. In this work, we propose an alternative approach to world modeling that is both accurate and efficient. We introduce EMERALD (Efficient MaskEd latent tRAnsformer worLD model), a world model using a spatial latent state with MaskGIT predictions to generate accurate trajectories in latent space and improve the agent performance. On the Crafter benchmark, EMERALD achieves new state-of-the-art performance, becoming the first method to surpass human experts performance within 10M environment steps. Our method also succeeds to unlock all 22 Crafter achievements at least once during evaluation.
💡 Research Summary
The paper introduces EMERALD (Efficient MaskEd latent tRAnsformer worLD model), a novel model‑based reinforcement learning (MBRL) architecture that simultaneously improves world‑model accuracy and training efficiency. Traditional Dreamer‑style agents learn a latent world model that compresses high‑dimensional observations into a compact latent space. While this enables fast imagination, the compression often discards crucial visual details, limiting performance on complex visual tasks such as Crafter. Recent attempts (Δ‑IRIS, DIAMOND) improve reconstruction quality by training agents directly on reconstructed pixels, but this incurs heavy computational costs and prevents the agent from exploiting the internal representations (e.g., long‑term memory) learned by the world model.
EMERALD addresses these shortcomings with three key innovations. First, it retains a spatial latent state zₜ (e.g., a 4×4 or 2×2 token grid) produced by a convolutional VAE with categorical latents, preserving spatial structure rather than collapsing everything into a single vector. Second, it replaces the sequential autoregressive decoder used in prior works with MaskGIT, a parallel masked‑token prediction scheme originally designed for vector‑quantized image generation. MaskGIT samples a masking ratio according to a cosine schedule, predicts the most confident tokens, fixes them, and iteratively refines the remaining ones. This yields orders‑of‑magnitude faster decoding while maintaining or improving reconstruction fidelity. Third, EMERALD trains the policy and value networks directly in latent space, allowing the agent to benefit from the world model’s hidden temporal state hₜ (produced by a temporal Transformer) and from the rich spatial information in zₜ.
The world model consists of a spatial Masked Transformer that predicts the next latent zₜ₊₁ given the current latent and action, and a temporal Transformer that updates the hidden state hₜ and predicts rewards and termination signals. By separating spatial and temporal processing, the model can specialize each component for its respective task, leading to higher accuracy on complex scenes. The actor‑critic learning loop imagines trajectories entirely in latent space, using the critic’s value estimates to guide the actor’s policy updates.
Empirical evaluation focuses on the Crafter benchmark and the Atari 100k suite. On Crafter, EMERALD achieves a score of 58.1 % within 10 million environment steps, surpassing human expert performance (≈55 %) and setting a new state‑of‑the‑art. It also unlocks all 22 Crafter achievements at least once, demonstrating robust perception of critical objects such as diamonds and arrows that previous models missed. Reconstruction error analysis shows near‑perfect recovery of original frames, with residual errors mainly due to player orientation or texture variations. In terms of efficiency, EMERALD runs at 38 FPS on an RTX 3090, roughly 2–3× faster than Δ‑IRIS and DIAMOND, thanks to the parallel MaskGIT decoding. On Atari 100k, where spatial latents are less critical, EMERALD still matches or exceeds prior model‑based methods, confirming that the architecture does not sacrifice generality.
The paper also situates EMERALD among related works: DreamerV3 (latent‑space world model with GRU), IRIS (token‑based autoregressive Transformer), TransDreamer/TWM (Transformer‑based state‑space models), and recent diffusion‑based approaches like DIAMOND. Unlike those, EMERALD combines spatial tokenization with MaskGIT’s efficient parallel decoding, and crucially keeps learning and acting in latent space rather than on reconstructed pixels.
In summary, EMERALD demonstrates that (i) preserving spatial structure in the latent representation mitigates information loss, (ii) MaskGIT‑style parallel decoding dramatically reduces imagination latency without compromising quality, and (iii) training agents directly on latent states enables them to exploit the world model’s internal memory. These contributions collectively push model‑based RL toward human‑level performance on visually rich, memory‑intensive tasks while maintaining practical training speeds, marking a significant step forward for the field.
Comments & Academic Discussion
Loading comments...
Leave a Comment