GPG: A Simple and Strong Reinforcement Learning Baseline for Model Reasoning
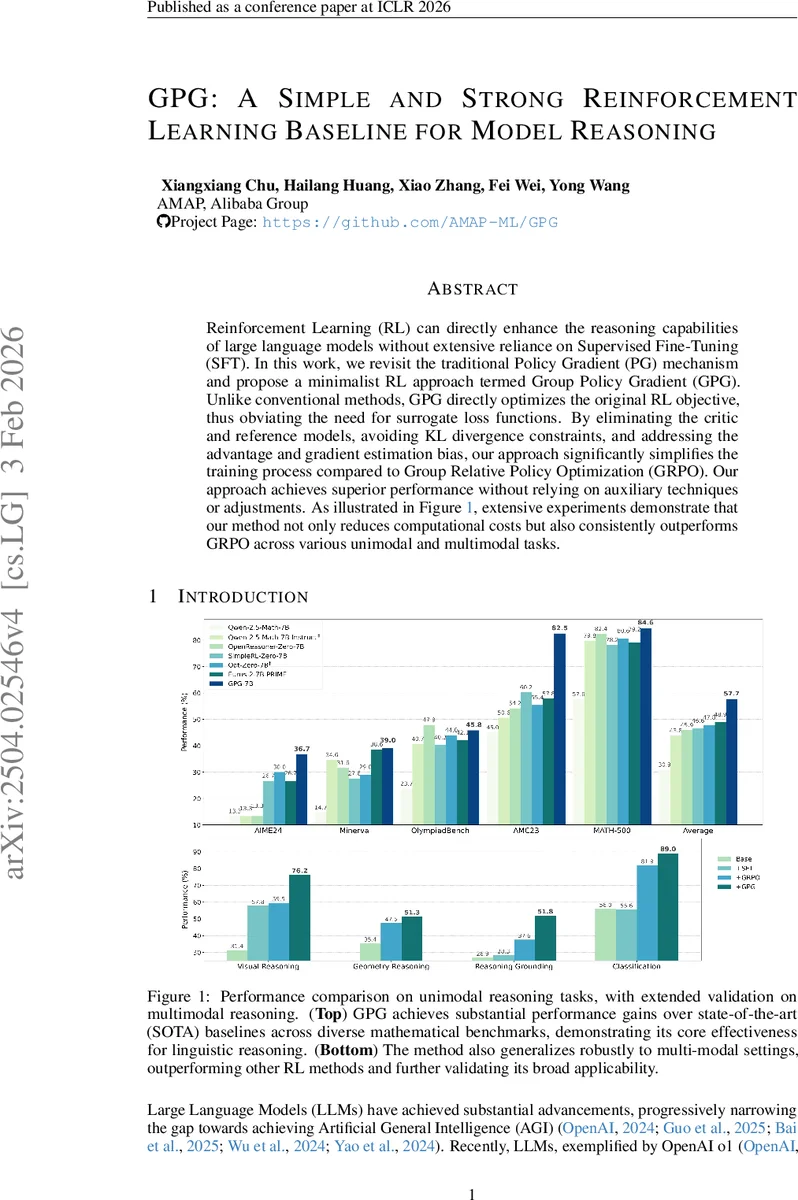
Reinforcement Learning (RL) can directly enhance the reasoning capabilities of large language models without extensive reliance on Supervised Fine-Tuning (SFT). In this work, we revisit the traditional Policy Gradient (PG) mechanism and propose a minimalist RL approach termed Group Policy Gradient (GPG). Unlike conventional methods, GPG directly optimize the original RL objective, thus obviating the need for surrogate loss functions. By eliminating the critic and reference models, avoiding KL divergence constraints, and addressing the advantage and gradient estimation bias, our approach significantly simplifies the training process compared to Group Relative Policy Optimization (GRPO). Our approach achieves superior performance without relying on auxiliary techniques or adjustments. As illustrated in Figure 1, extensive experiments demonstrate that our method not only reduces computational costs but also consistently outperforms GRPO across various unimodal and multimodal tasks. Our code is available at https://github.com/AMAP-ML/GPG.
💡 Research Summary
**
The paper revisits the classic policy‑gradient (PG) framework to address the growing need for efficient reinforcement‑learning (RL) methods that can improve the reasoning abilities of large language models (LLMs) without the heavy overhead of supervised fine‑tuning (SFT). The authors propose Group Policy Gradient (GPG), a minimalist RL algorithm that strips away all auxiliary components traditionally used in RL‑based fine‑tuning, such as a critic (value) model, a reference model, and KL‑divergence constraints.
Core Idea
GPG directly optimizes the original RL objective J(θ)=Eπθ
Comments & Academic Discussion
Loading comments...
Leave a Comment