An Optimization Method for Autoregressive Time Series Forecasting
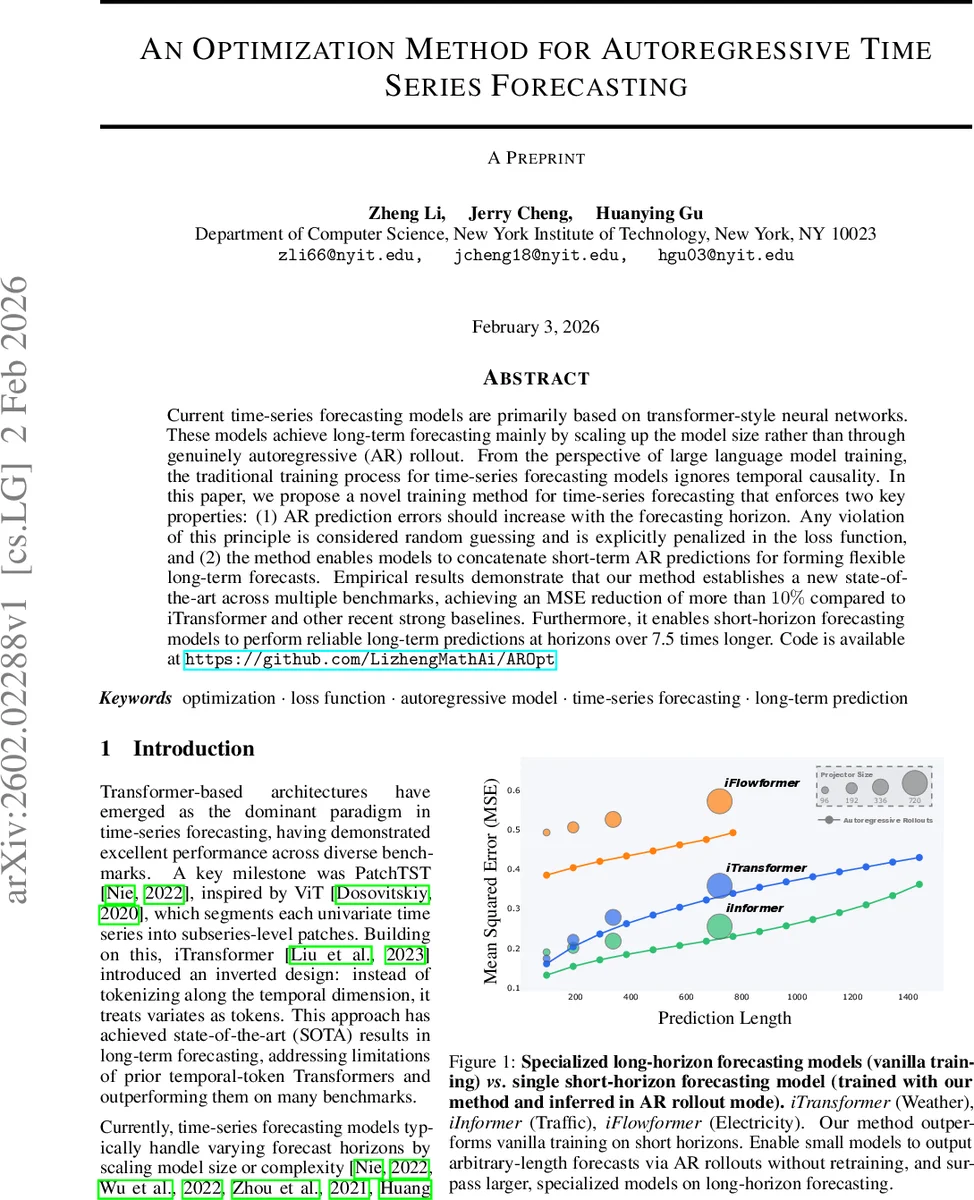
Current time-series forecasting models are primarily based on transformer-style neural networks. These models achieve long-term forecasting mainly by scaling up the model size rather than through genuinely autoregressive (AR) rollout. From the perspective of large language model training, the traditional training process for time-series forecasting models ignores temporal causality. In this paper, we propose a novel training method for time-series forecasting that enforces two key properties: (1) AR prediction errors should increase with the forecasting horizon. Any violation of this principle is considered random guessing and is explicitly penalized in the loss function, and (2) the method enables models to concatenate short-term AR predictions for forming flexible long-term forecasts. Empirical results demonstrate that our method establishes a new state-of-the-art across multiple benchmarks, achieving an MSE reduction of more than 10% compared to iTransformer and other recent strong baselines. Furthermore, it enables short-horizon forecasting models to perform reliable long-term predictions at horizons over 7.5 times longer. Code is available at https://github.com/LizhengMathAi/AROpt
💡 Research Summary
The paper “An Optimization Method for Autoregressive Time Series Forecasting” tackles a fundamental weakness in modern transformer‑based time‑series forecasting models: their reliance on scaling model size to achieve long‑horizon performance while largely ignoring temporal causality during training. Conventional approaches either train a single model for a fixed forecast length or enlarge the decoder/projector to directly predict longer horizons. Both strategies suffer from a paradoxical error pattern—early predictions often have larger errors that do not propagate, while later predictions appear artificially accurate, indicating random guessing rather than genuine forecasting ability.
To remedy this, the authors propose a training framework that enforces two principled constraints via a novel loss function. First, in an autoregressive (AR) rollout the prediction error must increase monotonically with the forecast step. Any violation (i.e., a later step being more accurate than an earlier one) is treated as random guessing and penalized. Second, short‑term AR predictions are concatenated sequentially to construct forecasts of arbitrary length, allowing a model trained on a modest horizon (e.g., 96 steps) to generate reliable forecasts at horizons many times larger (e.g., 720 steps) without any architectural changes.
Algorithm 1 details the procedure. Given a historical context of length S and a rollout stride T, the model f(·;θ) first predicts the initial T‑step block, computes its MSE e₁, and then iteratively feeds its own predictions back as input to generate subsequent blocks. For each step k the loss contribution is a discounted combination of the raw error (1−β)·e_k and a smoothing term β·|e_k−sg(e_{k−1})|, where sg denotes a stop‑gradient operator. The discount factor γ (default 0.5) down‑weights later steps, while β (default 0.1) controls the strength of the monotonicity penalty. The total objective ℓ = Σ_{k=0}^{n−1} γ^k
Comments & Academic Discussion
Loading comments...
Leave a Comment