State Rank Dynamics in Linear Attention LLMs
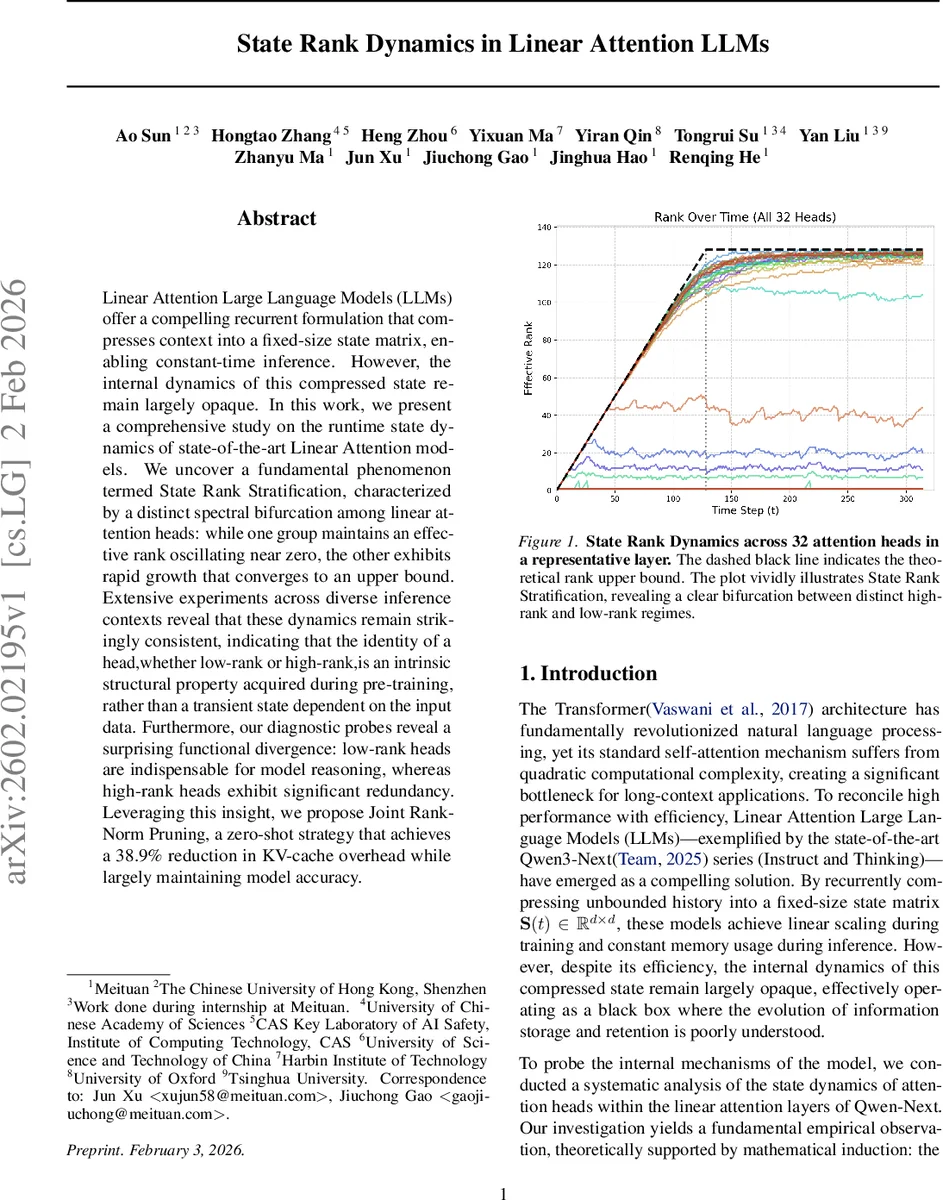
Linear Attention Large Language Models (LLMs) offer a compelling recurrent formulation that compresses context into a fixed-size state matrix, enabling constant-time inference. However, the internal dynamics of this compressed state remain largely opaque. In this work, we present a comprehensive study on the runtime state dynamics of state-of-the-art Linear Attention models. We uncover a fundamental phenomenon termed State Rank Stratification, characterized by a distinct spectral bifurcation among linear attention heads: while one group maintains an effective rank oscillating near zero, the other exhibits rapid growth that converges to an upper bound. Extensive experiments across diverse inference contexts reveal that these dynamics remain strikingly consistent, indicating that the identity of a head,whether low-rank or high-rank,is an intrinsic structural property acquired during pre-training, rather than a transient state dependent on the input data. Furthermore, our diagnostic probes reveal a surprising functional divergence: low-rank heads are indispensable for model reasoning, whereas high-rank heads exhibit significant redundancy. Leveraging this insight, we propose Joint Rank-Norm Pruning, a zero-shot strategy that achieves a 38.9% reduction in KV-cache overhead while largely maintaining model accuracy.
💡 Research Summary
This paper investigates the internal dynamics of linear‑attention large language models (LLMs), focusing on the recurrent state matrix S(t) that compresses all past key‑value pairs into a fixed‑size d × d tensor. The authors first establish a theoretical upper bound on the effective rank of S(t): rank(S(t)) ≤ min(t, d). Consequently, during the early phase (t < d) the rank can grow linearly, but once the sequence length exceeds the model dimension the state matrix enters a “rank‑saturation” regime where additional updates must lie within the existing subspace.
Empirically, the authors track the singular‑value spectra of each linear‑attention head in the state‑of‑the‑art Qwen‑Next model. They discover a striking bifurcation, termed State Rank Stratification, where heads separate into two stable groups: (1) Low‑rank heads whose effective rank stays near zero throughout generation, and (2) High‑rank heads that quickly rise and track the theoretical upper bound.
To assess the permanence of this split, the paper measures two consistency metrics across widely separated time steps (e.g., t = 128 vs. t = 2048). Rank vectors r(t) show Spearman correlations above 0.90, while nuclear‑norm vectors n(t) exhibit cosine similarities above 0.98. These results indicate that a head’s relative capacity (high vs. low rank) is determined early and remains invariant during inference.
The authors further test data independence by repeating the spectral analysis on heterogeneous corpora: natural‑language text (WikiText), source code (GitHub), and mathematical papers (arXiv). Although the absolute values of S(t) vary with domain, the allocation of heads to the high‑rank or low‑rank clusters does not change, suggesting that the stratification is encoded in the pretrained weight matrices W_K and W_V rather than being a reaction to input complexity.
Adversarial “looping” inputs (repeated rare characters or numbers) break the usual pattern: the effective rank oscillates and fails to reach the upper bound, demonstrating that highly repetitive sequences prevent the state matrix from accumulating new dimensions.
Building on these observations, the paper provides a rigorous theoretical framework. Assuming non‑decreasing rank for each head (a natural consequence of rank‑one updates), the authors prove that if the cosine similarity between consecutive rank vectors exceeds a threshold, it will be preserved in subsequent steps (Theorem 4.2). A parallel analysis shows that the nuclear‑norm direction is similarly stable, formalizing the empirical “Rank Consistency” and “Norm Consistency.”
Armed with the insight that high‑rank heads often become redundant, the authors propose Joint Rank‑Norm Pruning, a zero‑shot pruning strategy that removes high‑rank heads with relatively low nuclear norm while preserving all low‑rank heads. This method reduces KV‑cache memory usage by 38.9 % and maintains perplexity and downstream task performance comparable to the unpruned baseline, without any fine‑tuning or auxiliary predictors.
In summary, the work makes three major contributions: (1) the first systematic spectral analysis of linear‑attention state dynamics, revealing a universal rank stratification; (2) a theoretical justification for the observed temporal and data‑invariant stability of rank and norm vectors; and (3) a practical, data‑free pruning technique that leverages these insights to achieve substantial inference efficiency gains. The findings deepen our understanding of how linear‑attention LLMs store and forget information and open avenues for further research on dynamic memory management and model compression across diverse transformer architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment