LDRNet: Large Deformation Registration Model for Chest CT Registration
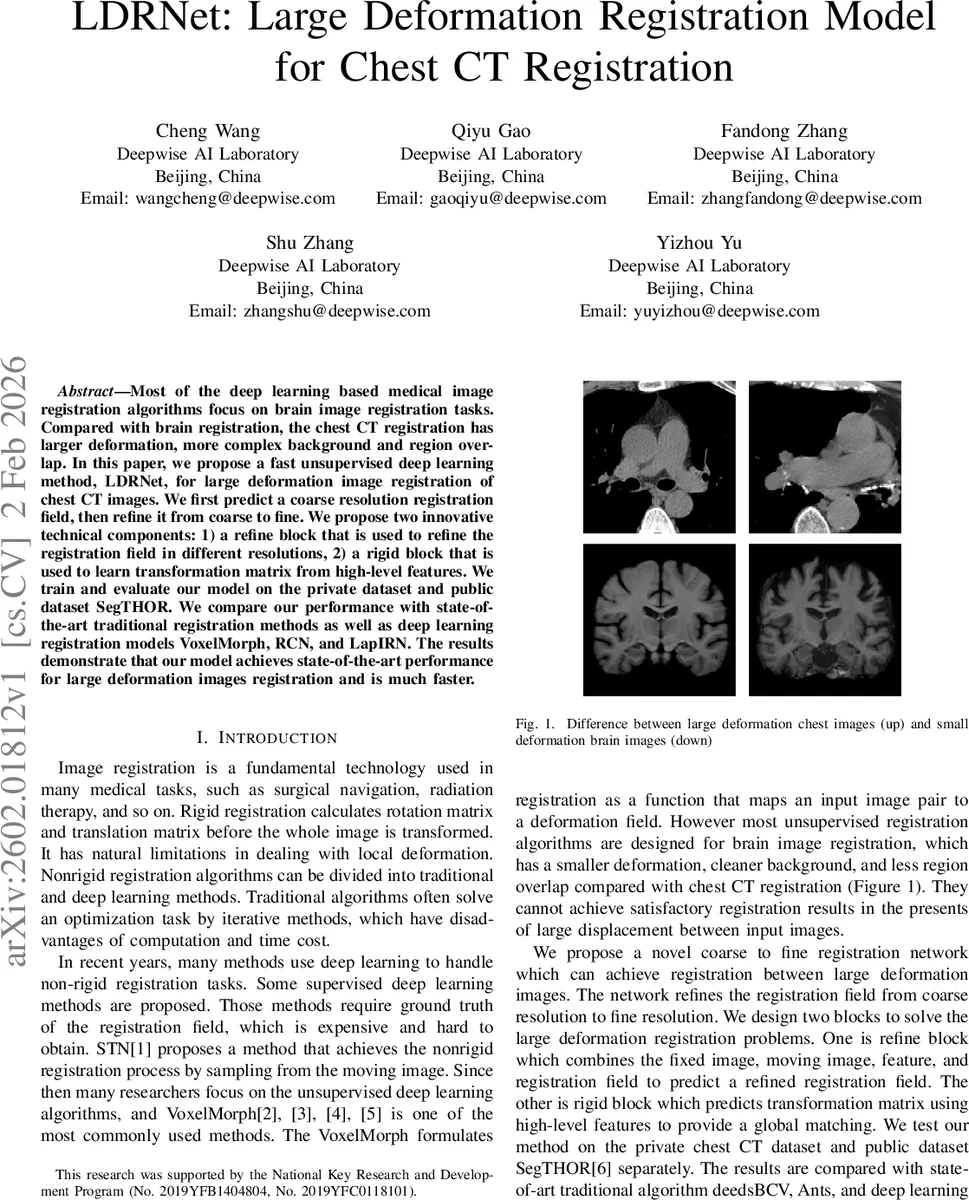
Most of the deep learning based medical image registration algorithms focus on brain image registration tasks.Compared with brain registration, the chest CT registration has larger deformation, more complex background and region over-lap. In this paper, we propose a fast unsupervised deep learning method, LDRNet, for large deformation image registration of chest CT images. We first predict a coarse resolution registration field, then refine it from coarse to fine. We propose two innovative technical components: 1) a refine block that is used to refine the registration field in different resolutions, 2) a rigid block that is used to learn transformation matrix from high-level features. We train and evaluate our model on the private dataset and public dataset SegTHOR. We compare our performance with state-of-the-art traditional registration methods as well as deep learning registration models VoxelMorph, RCN, and LapIRN. The results demonstrate that our model achieves state-of-the-art performance for large deformation images registration and is much faster.
💡 Research Summary
**
The paper introduces LDRNet, a novel unsupervised deep‑learning framework designed specifically for large‑deformation registration of chest CT scans. While most existing medical image registration networks (e.g., VoxelMorph, RCN, LapIRN) have been developed and evaluated on brain MRI where deformations are relatively modest, chest CT presents unique challenges: substantial organ displacement, complex bony structures, and significant overlap among anatomical regions. These factors render brain‑oriented models insufficient for accurate chest registration.
LDRNet adopts a coarse‑to‑fine strategy. First, the moving (M) and fixed (F) volumes are concatenated and passed through a multi‑scale encoder‑decoder (UNet‑like) to extract hierarchical features. At the deepest level, a dedicated Rigid Block predicts a global 3‑D rotation matrix R and translation vector t from the high‑level features. The predicted rigid transformation is applied to the lowest‑resolution deformation field ϕₙ, providing an initial global alignment that mimics traditional rigid pre‑registration but remains fully differentiable within the network.
Subsequently, a series of Refine Blocks operate at progressively finer resolutions. Each Refine Block receives four inputs: (1) the current‑resolution pooled fixed and moving images, (2) the corresponding feature map from the encoder, (3) the up‑sampled deformation field from the previous stage (˜ϕ₍i‑1₎), and (4) a warped moving image M(ϕ)₍i₎ obtained by applying ˜ϕ₍i‑1₎ to the moving volume. The difference tensor D₍i₎ = M(ϕ)₍i₎ – F₍i₎ is also concatenated, explicitly exposing the residual mis‑alignment. A small 3‑D convolutional core processes this concatenated tensor and predicts a correction Δϕ₍i₎, which is added to ˜ϕ₍i‑1₎ to produce the refined field ϕ₍i₎. By iteratively correcting the deformation at each scale, the network can handle very large displacements while preserving fine‑grained local accuracy.
The loss function combines a similarity term (Mean Squared Error between the warped moving image and the fixed image) with two regularization components: L_range, which penalizes large absolute displacement values to keep sampling coordinates within the normalized
Comments & Academic Discussion
Loading comments...
Leave a Comment