Rethinking LoRA for Data Heterogeneous Federated Learning: Subspace and State Alignment
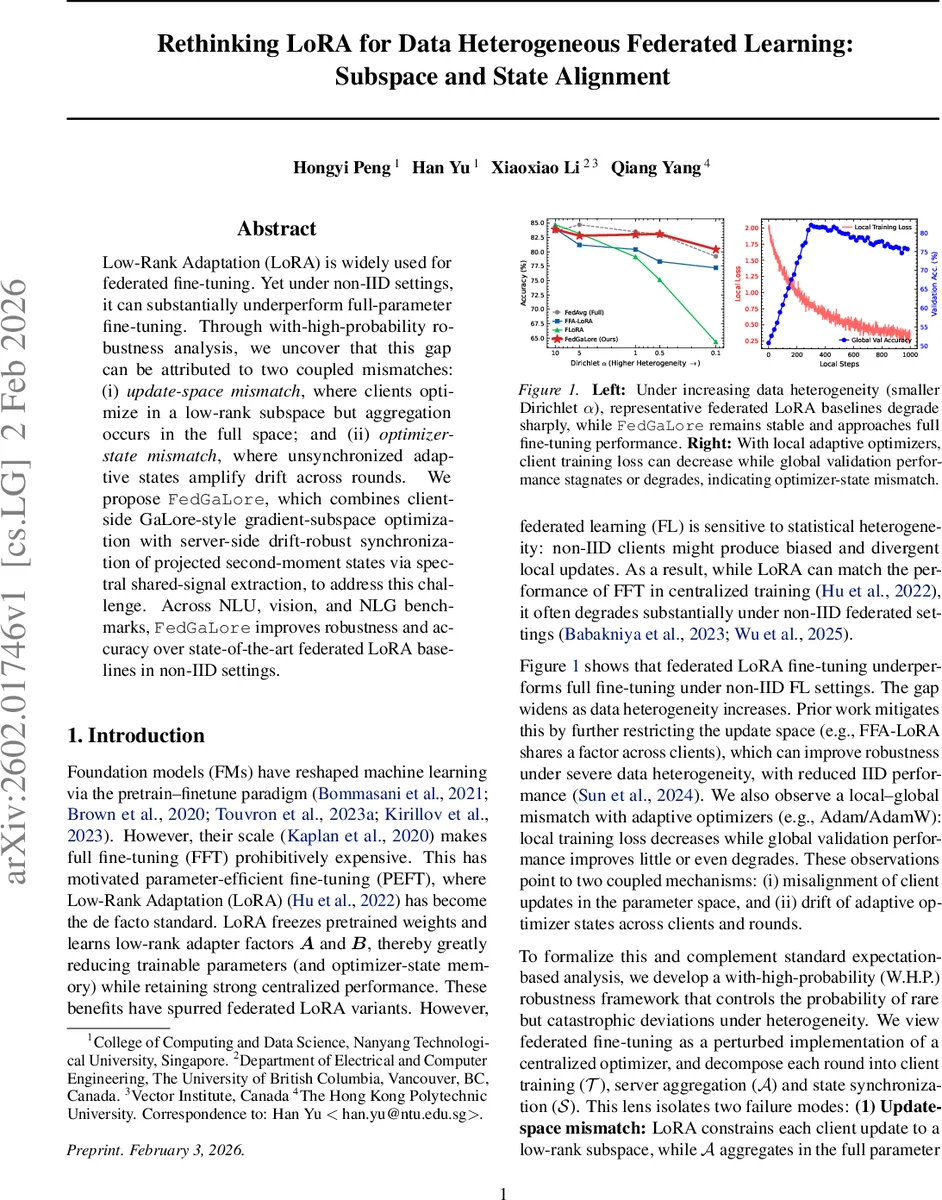
Low-Rank Adaptation (LoRA) is widely used for federated fine-tuning. Yet under non-IID settings, it can substantially underperform full-parameter fine-tuning. Through with-high-probability robustness analysis, we uncover that this gap can be attributed to two coupled mismatches: (i) update-space mismatch, where clients optimize in a low-rank subspace but aggregation occurs in the full space; and (ii) optimizer-state mismatch, where unsynchronized adaptive states amplify drift across rounds. We propose FedGaLore, which combines client-side GaLore-style gradient-subspace optimization with server-side drift-robust synchronization of projected second-moment states via spectral shared-signal extraction, to address this challenge. Across NLU, vision, and NLG benchmarks, FedGaLore improves robustness and accuracy over state-of-the-art federated LoRA baselines in non-IID settings.
💡 Research Summary
This paper investigates why Low‑Rank Adaptation (LoRA), a popular parameter‑efficient fine‑tuning technique, underperforms full‑parameter fine‑tuning (FFT) in federated learning (FL) when client data are non‑IID. The authors identify two coupled sources of degradation: (i) update‑space mismatch, where each client’s LoRA update lives in a low‑rank subspace but the server aggregates these updates in the full‑parameter space, and (ii) optimizer‑state mismatch, where adaptive optimizer states (e.g., Adam’s first‑ and second‑moment estimates) drift independently across clients and are not synchronized, amplifying client drift.
To rigorously capture these phenomena, the paper adopts a with‑high‑probability (W.H.P.) robustness framework. Instead of relying on expectation‑based convergence, the authors bound the probability that any client trajectory leaves a well‑behaved region Q (local containment) and that the aggregated model exits Q (aggregation stability). By union‑bounding these events, they guarantee that the global trajectory stays inside Q with probability at least 1‑δ, enabling standard contraction arguments throughout training.
The geometric analysis of the update‑space mismatch leverages Weil’s tube formula to show that the manifold of rank‑r updates has a large codimension; consequently, the volume of an R‑tube around this manifold is vanishingly small compared to the ambient parameter space. When low‑rank LoRA updates are lifted to the full space for averaging, the resulting aggregate can easily leave the low‑rank manifold, destabilizing training.
For the optimizer‑state mismatch, the paper notes that local adaptive optimizers accumulate client‑specific first‑moment (m) and second‑moment (v) statistics. Without synchronization, these statistics cause each client’s preconditioner to diverge, leading to amplified drift and poor global performance.
FedGaLore is proposed to resolve both mismatches. On the client side, it replaces the fixed LoRA parameter subspace with GaLore‑style gradient‑subspace optimization: each client projects its gradients onto an adaptively estimated low‑rank subspace and updates within that subspace, preserving LoRA’s parameter efficiency while allowing updates to align better with the full‑parameter space. Clients also employ a GaLore‑adapted AdamW to keep local adaptivity.
On the server side, only the projected second‑moment (v) matrices are uploaded. The server applies an AJIVE (Alternating Joint and Individual Variation Explained) filter to extract the shared component across clients, which is then broadcast as the synchronized second‑moment initialization for the next round. This spectral shared‑signal extraction provides drift‑robust synchronization with minimal communication overhead.
Experiments span natural language understanding (GLUE/SuperGLUE), computer vision (CIFAR‑10/100, ImageNet‑mini), and natural language generation (GPT‑2‑based text generation). Data heterogeneity is simulated via Dirichlet α values ranging from 0.1 (highly non‑IID) to 1.0 (near‑IID). FedGaLore is compared against FedAvg, FedAvg+Adam, and several recent federated LoRA variants (FedIT, FF‑A‑LoRA, LoRA‑Fair, FLoRA, FR‑LoRA). Results show that as α decreases, baseline LoRA methods suffer steep accuracy drops (often >10 % absolute), whereas FedGaLore’s performance degrades only marginally (≈2–3 % absolute) and remains close to FFT. Moreover, the typical phenomenon where local training loss decreases while global validation accuracy stagnates—observed with local AdamW—is eliminated under FedGaLore, confirming that synchronizing the projected second‑moment state mitigates drift. Communication cost remains comparable to existing LoRA approaches, while the overall training time is reduced due to faster convergence.
In conclusion, the paper demonstrates that subspace alignment (via gradient‑subspace optimization) and state alignment (via spectral second‑moment synchronization) are essential to make LoRA viable for heterogeneous federated learning. The proposed FedGaLore achieves strong robustness and accuracy without sacrificing the parameter‑efficiency that makes LoRA attractive. Future directions include extending the approach to other adaptive optimizers, handling asynchronous client participation, and integrating privacy‑preserving mechanisms into the shared‑signal extraction process.
Comments & Academic Discussion
Loading comments...
Leave a Comment