A2Eval: Agentic and Automated Evaluation for Embodied Brain
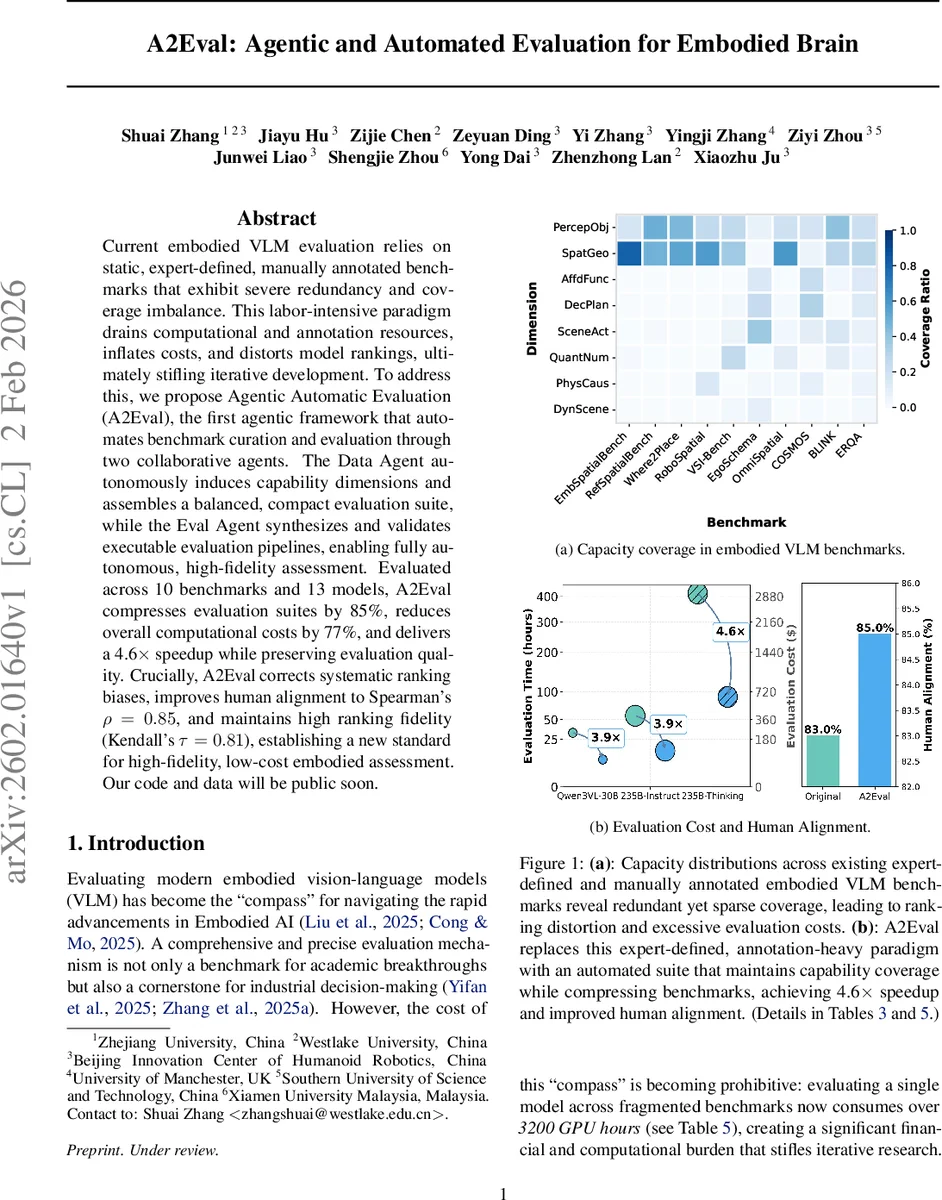
Current embodied VLM evaluation relies on static, expert-defined, manually annotated benchmarks that exhibit severe redundancy and coverage imbalance. This labor intensive paradigm drains computational and annotation resources, inflates costs, and distorts model rankings, ultimately stifling iterative development. To address this, we propose Agentic Automatic Evaluation (A2Eval), the first agentic framework that automates benchmark curation and evaluation through two collaborative agents. The Data Agent autonomously induces capability dimensions and assembles a balanced, compact evaluation suite, while the Eval Agent synthesizes and validates executable evaluation pipelines, enabling fully autonomous, high-fidelity assessment. Evaluated across 10 benchmarks and 13 models, A2Eval compresses evaluation suites by 85%, reduces overall computational costs by 77%, and delivers a 4.6x speedup while preserving evaluation quality. Crucially, A2Eval corrects systematic ranking biases, improves human alignment to Spearman’s rho=0.85, and maintains high ranking fidelity (Kendall’s tau=0.81), establishing a new standard for high-fidelity, low-cost embodied assessment. Our code and data will be public soon.
💡 Research Summary
A2Eval introduces a novel, fully automated framework for evaluating embodied vision‑language models (VLMs) that replaces the traditional static, expert‑defined, manually annotated benchmark paradigm. The system consists of two collaborative agents: a Data Agent that autonomously discovers capability dimensions and constructs a compact, balanced benchmark suite, and an Eval Agent that automatically synthesizes and validates executable inference and scoring pipelines.
Problem Context
Current embodied VLM evaluation suffers from three systemic issues: (1) coverage imbalance and massive redundancy across fragmented benchmarks, (2) ranking distortion where models overfit to over‑represented tasks, and (3) prohibitive computational and annotation costs—often exceeding 3,200 GPU hours for a single model. These problems hinder rapid iteration and mislead research directions.
Data Agent Mechanics
The Data Agent operates through three specialized LLM roles: Proposer, Reviewer, and Assigner. The Proposer generates candidate capability dimensions from benchmark metadata; the Reviewer critiques these candidates on redundancy, domain coverage, and balance; the Assigner assigns real examples to dimensions and performs diversity‑aware sampling. All interactions are stored in a shared memory M, enabling iterative refinement until the dimension set D stabilizes. The final taxonomy comprises eight dimensions: Perception & Object Grounding, Scene & Action Understanding, Spatial & Geometric Reasoning, Quantitative & Numerical Reasoning, Affordance & Function Reasoning, Physical & Causal Reasoning, Decision & Task Planning, and Dynamic Scene Reasoning.
Using an ensemble of voter agents, the Assigner first assigns each example to one or more dimensions via majority voting. Then, for each dimension, it embeds examples and applies K‑means clustering (fixed K=500) to retain only the example nearest each centroid, thereby eliminating intra‑dimension redundancy while preserving semantic diversity. This process reduces the original 24,519 examples to 3,781 (≈85 % compression) while maintaining a balanced representation across all dimensions.
Eval Agent Mechanics
The Eval Agent contains two roles: Evaluator and Scorer. The Evaluator synthesizes model‑specific inference code (Fe) that loads test inputs, calls the target model, and produces predictions. The code is executed in a sandbox executor X; failures return diagnostic feedback that the Evaluator uses to iteratively refine Fe until it runs reliably. The Scorer similarly generates scoring code (Fs) that consumes predictions and computes performance metrics. Both loops are bounded by a small iteration budget (e.g., five attempts). Once Fe and Fs are validated, the full pipeline runs automatically on the compressed benchmark, yielding per‑dimension performance scores.
Experimental Evaluation
A2Eval was evaluated on ten publicly available embodied benchmarks (e.g., Where2Place, VSI‑Bench, ERQA, COSMOS) and thirteen state‑of‑the‑art models (Qwen‑VL variants, InternVL series, GPT‑5, etc.). Key results include:
- Cost Reduction – Overall GPU consumption dropped by 77 % (from ~3,200 h to ~736 h per model) and evaluation throughput increased by 4.6×.
- Redundancy Elimination – 85 % of duplicate samples were removed without sacrificing coverage.
- Ranking Fidelity – Kendall’s τ between A2Eval rankings and full‑benchmark rankings remained high at 0.81; Spearman’s ρ improved to 0.85, indicating stronger alignment with human preference judgments.
- Human Alignment – Human‑based preference correlation rose from ~0.62 (baseline) to 0.85, demonstrating that the compressed suite better reflects human judgments of model behavior.
- Pipeline Accuracy – The automatically generated inference and scoring pipelines achieved 96.9 % fidelity compared to hand‑crafted baselines.
Contributions
- First Agentic Evaluation Framework – A2Eval decouples benchmark construction and execution from static expert labels, enabling fully autonomous, scalable assessment.
- Balanced, Compact Benchmark Construction – By inducing capability dimensions and applying diversity‑aware sampling, the Data Agent reduces redundancy, corrects ranking bias, and cuts evaluation cost dramatically.
- Autonomous Executable Pipelines – The Eval Agent’s code‑synthesis‑validation loop produces reliable inference and scoring scripts without human intervention, supporting rapid re‑evaluation of new models or tasks.
Limitations & Future Work
While A2Eval successfully automates existing benchmark consolidation, its dimension induction relies on the richness of current benchmark metadata; emerging capabilities (e.g., social interaction reasoning) may require additional prompting strategies. The code synthesis step depends on the underlying LLM’s programming competence; integrating formal verification or multi‑agent consensus could improve robustness. Finally, extending the framework to support multi‑modal, multi‑agent environments and to incorporate continual learning scenarios represents promising directions.
Conclusion
A2Eval demonstrates that a two‑agent, agentic approach can dramatically streamline embodied VLM evaluation, delivering substantial cost savings, higher human alignment, and unbiased model rankings while preserving comprehensive capability coverage. By automating both benchmark curation and execution, it paves the way for faster, more reliable iteration cycles in embodied AI research and industry deployments, establishing a new standard for high‑fidelity, low‑cost evaluation.
Comments & Academic Discussion
Loading comments...
Leave a Comment