Staircase Cascaded Fusion of Lightweight Local Pattern Recognition and Long-Range Dependencies for Structural Crack Segmentation
Accurately segmenting structural cracks at the pixel level remains a major hurdle, as existing methods fail to integrate local textures with pixel dependencies, often leading to fragmented and incomplete predictions. Moreover, their high parameter counts and substantial computational demands hinder practical deployment on resource-constrained edge devices. To address these challenges, we propose CrackSCF, a Lightweight Cascaded Fusion Crack Segmentation Network designed to achieve robust crack segmentation with exceptional computational efficiency. We design a lightweight convolutional block (LRDS) to replace all standard convolutions. This approach efficiently captures local patterns while operating with a minimal computational footprint. For a holistic perception of crack structures, a lightweight Long-range Dependency Extractor (LDE) captures global dependencies. These are then intelligently unified with local patterns by our Staircase Cascaded Fusion Module (SCFM), ensuring the final segmentation maps are both seamless in continuity and rich in fine-grained detail. To comprehensively evaluate our method, this paper created the challenging TUT benchmark dataset and evaluated it alongside five other public datasets. The experimental results show that the CrackSCF method consistently outperforms the existing methods, and it demonstrates greater robustness in dealing with complex background noise. On the TUT dataset, CrackSCF achieved 0.8382 on F1 score and 0.8473 on mIoU, and it only required 4.79M parameters.
💡 Research Summary
The paper addresses two fundamental challenges in pixel‑level structural crack segmentation: the lack of effective integration between local texture cues and long‑range pixel dependencies, and the prohibitive computational cost of existing high‑performance models. To solve these problems, the authors propose CrackSCF, a lightweight cascaded‑fusion network composed of three novel components.
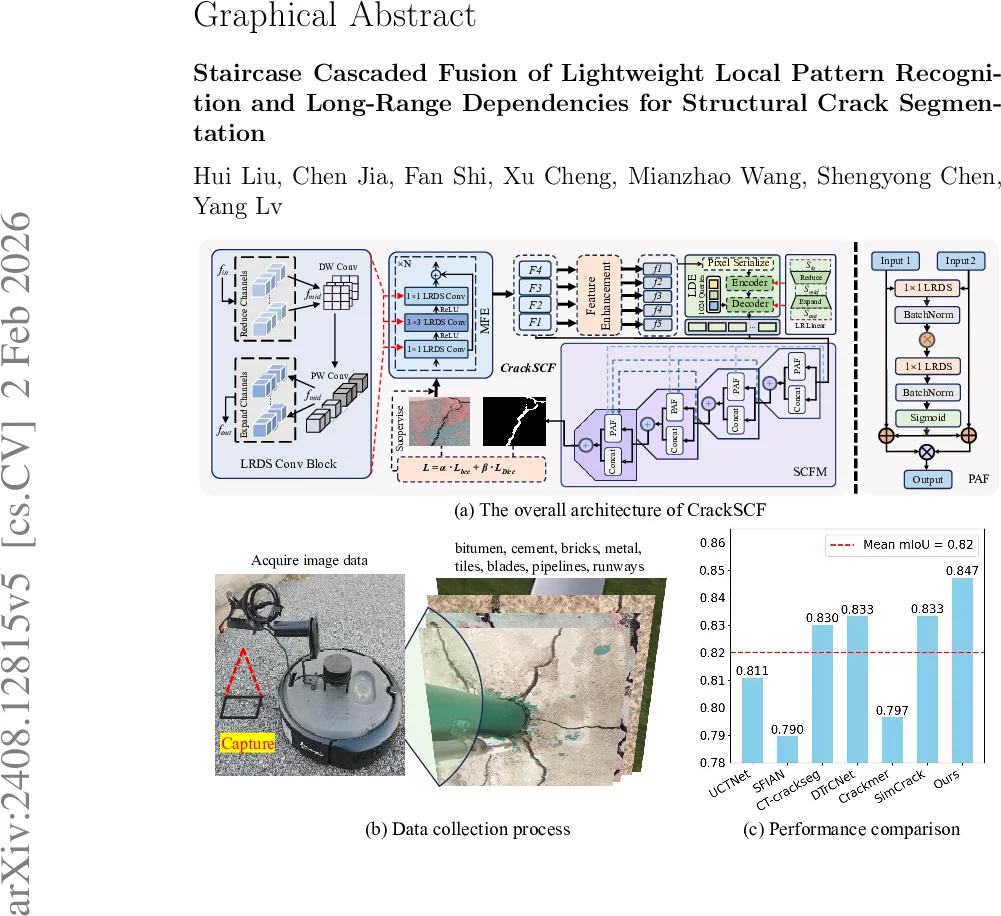
First, the Low‑Rank Depthwise Separable (LRDS) block replaces every standard convolution in a ResNet‑50 backbone with a bottleneck‑style module that reduces input channels, applies depthwise and pointwise convolutions within a low‑rank subspace, and then expands the channels back. By factorising the convolutional weight matrix into low‑rank components, LRDS dramatically cuts FLOPs and parameters while preserving spatial detail.
Second, the Lightweight Long‑Range Dependency Extractor (LDE) captures global relationships among crack pixels using a deformable attention mechanism. The authors further reduce the cost of the linear projections inside the attention by applying low‑rank matrix decomposition (E≈ABᵀ), which accounts for 90 % of the FLOPs and 67 % of the parameters in the original LDE. This design enables efficient modeling of irregular, elongated crack structures.
Third, the Staircase Cascaded Fusion Module (SCFM) merges the multi‑scale feature maps produced by the Multi‑scale Feature Extractor (MFE) with the pixel sequences generated by LDE. SCFM operates in four stages, each consisting of channel concatenation, pixel‑level attention, and a 1×1 LRDS convolution. At each stage the spatial resolution is doubled while the channel dimension is halved, forming a “staircase” progression that progressively fuses local and global information. This deep interaction between texture and dependency features mitigates the fragmentation and background noise issues that plague simpler concatenation or channel‑attention schemes.
To evaluate the method, the authors introduce the TUT benchmark, a new dataset of 1,408 high‑resolution images covering eight material categories (bitumen, cement, bricks, tiles, metal, blades, pipelines, runways) and diverse lighting and occlusion conditions. Compared with five public crack datasets, CrackSCF consistently outperforms state‑of‑the‑art CNN‑Transformer hybrids such as CATransUNet, DT‑rCNet, and Crackmer. On the TUT set, CrackSCF achieves an F1 score of 0.8382 and a mean IoU of 0.8473, using only 4.79 M parameters and approximately 3.2 G FLOPs—far less than the 9–12 M parameters and >70 G FLOPs required by competing methods.
In summary, CrackSCF demonstrates that a carefully engineered combination of low‑rank convolution, lightweight deformable attention, and staircase‑style fusion can deliver high‑accuracy crack segmentation with a computational footprint suitable for edge devices such as smartphones and drones. This makes real‑time, on‑site structural health monitoring more practical and scalable.
Comments & Academic Discussion
Loading comments...
Leave a Comment