HalluHard: A Hard Multi-Turn Hallucination Benchmark
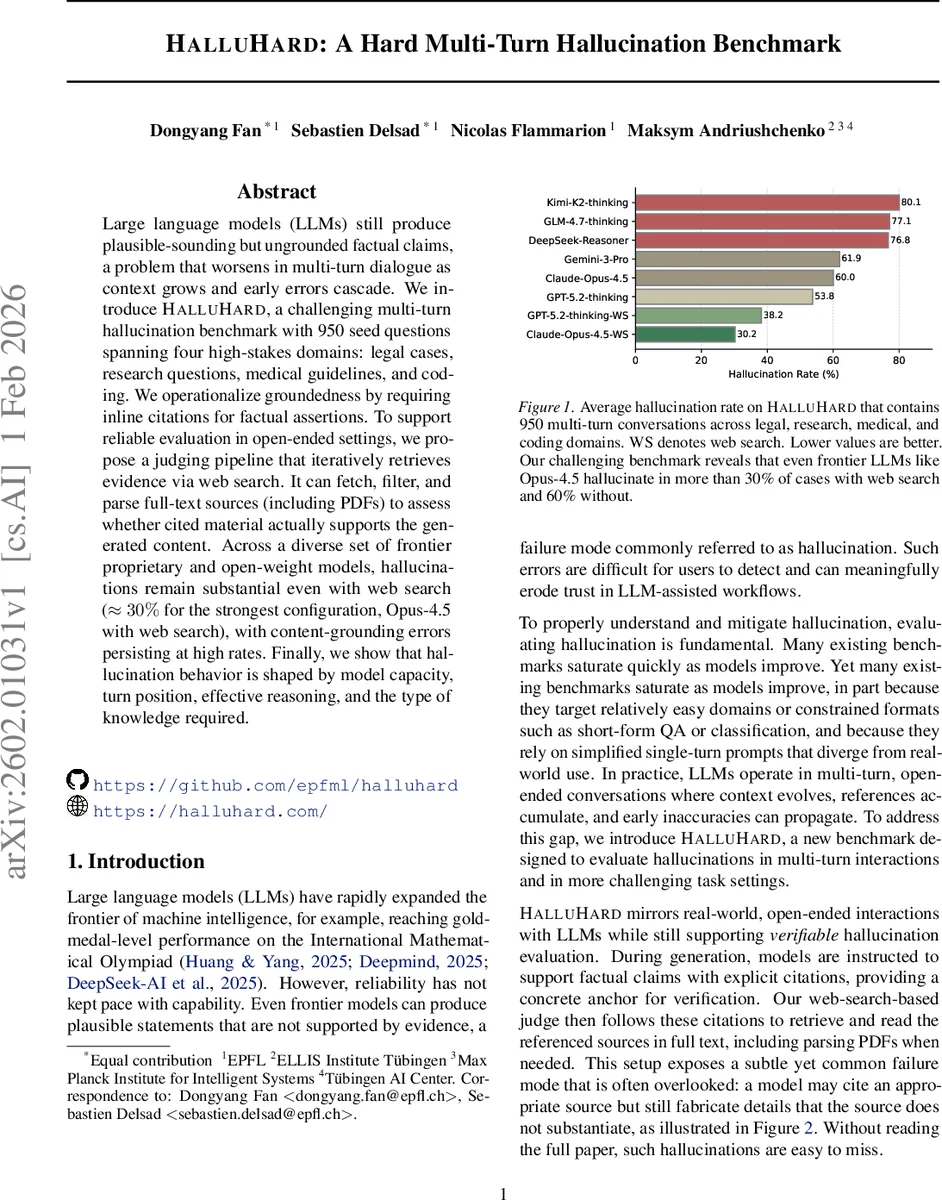
Large language models (LLMs) still produce plausible-sounding but ungrounded factual claims, a problem that worsens in multi-turn dialogue as context grows and early errors cascade. We introduce $\textbf{HalluHard}$, a challenging multi-turn hallucination benchmark with 950 seed questions spanning four high-stakes domains: legal cases, research questions, medical guidelines, and coding. We operationalize groundedness by requiring inline citations for factual assertions. To support reliable evaluation in open-ended settings, we propose a judging pipeline that iteratively retrieves evidence via web search. It can fetch, filter, and parse full-text sources (including PDFs) to assess whether cited material actually supports the generated content. Across a diverse set of frontier proprietary and open-weight models, hallucinations remain substantial even with web search ($\approx 30%$ for the strongest configuration, Opus-4.5 with web search), with content-grounding errors persisting at high rates. Finally, we show that hallucination behavior is shaped by model capacity, turn position, effective reasoning, and the type of knowledge required.
💡 Research Summary
The paper introduces HalluHard, a challenging multi‑turn hallucination benchmark designed to evaluate factual grounding failures of large language models (LLMs) in realistic, open‑ended dialogues. The benchmark covers four high‑stakes domains—legal cases, research questions, medical guidelines, and coding—providing 950 seed questions (250 each for the first three domains and 200 for coding). Each seed question initiates a conversation, and a user‑LLM generates natural follow‑up questions, creating multi‑turn interactions that mimic real user behavior. Crucially, models are instructed to include inline citations for every factual claim, turning the citation itself into a verifiable anchor.
To assess groundedness, the authors build a modular judging pipeline that goes beyond existing short‑snippet approaches like SAFE. The pipeline first extracts atomic claims from the model’s responses using an LLM‑based extractor. For each claim, it plans a web‑search query, invokes the Serper API, and retrieves full‑text documents—including PDFs—rather than just snippets. The retrieved sources are parsed, and the cited passages are matched against the claim content. A second LLM then decides whether the gathered evidence is sufficient; if not, it refines the query and triggers additional searches. This iterative process enables both reference verification (does the cited source exist and match the quotation?) and content verification (does the source actually support the claim?).
The authors evaluate a diverse set of frontier proprietary models (e.g., Opus‑4.5, Claude, Gemini‑3‑P, DeepSeek‑Reasoner) and open‑weight models across the benchmark. Without web search, hallucination rates exceed 60% on average. Even with web search enabled, the strongest configuration (Opus‑4.5 with web search) still hallucinates roughly 30% of the time. Error analysis reveals several systematic patterns: hallucinations increase in later turns, indicating error propagation from early mis‑citations; “effective reasoning” prompts that encourage the model to think before answering reduce hallucinations, whereas merely adding more reasoning steps does not yield further gains; and domain differences are pronounced, with medical and legal questions exhibiting the highest hallucination rates due to their reliance on precise, up‑to‑date technical knowledge.
Key contributions of the work are threefold. First, HalluHard itself—by combining multi‑turn dialogue, high‑stakes domains, and mandatory inline citations—offers a more demanding and realistic test of factuality than existing single‑turn or short‑answer benchmarks that are quickly saturated by modern models. Second, the authors present a robust, citation‑checkable judge that can fetch and parse full‑text evidence, allowing fine‑grained verification of both reference correctness and content grounding. Third, the extensive empirical study uncovers how model capacity, turn position, reasoning strategy, and knowledge type each influence hallucination behavior, challenging the common belief that web‑search augmentation alone can solve factuality problems.
The findings suggest that simply attaching a retrieval tool is insufficient for eliminating hallucinations in advanced LLMs. Future work should focus on improving the generation of accurate citations, developing mechanisms to prevent error propagation across turns, and constructing domain‑specific verification resources that can be integrated into the model’s reasoning loop. HalluHard provides a valuable platform for tracking progress on these fronts as LLMs continue to evolve.
Comments & Academic Discussion
Loading comments...
Leave a Comment