RMFlow: Refined Mean Flow by a Noise-Injection Step for Multimodal Generation
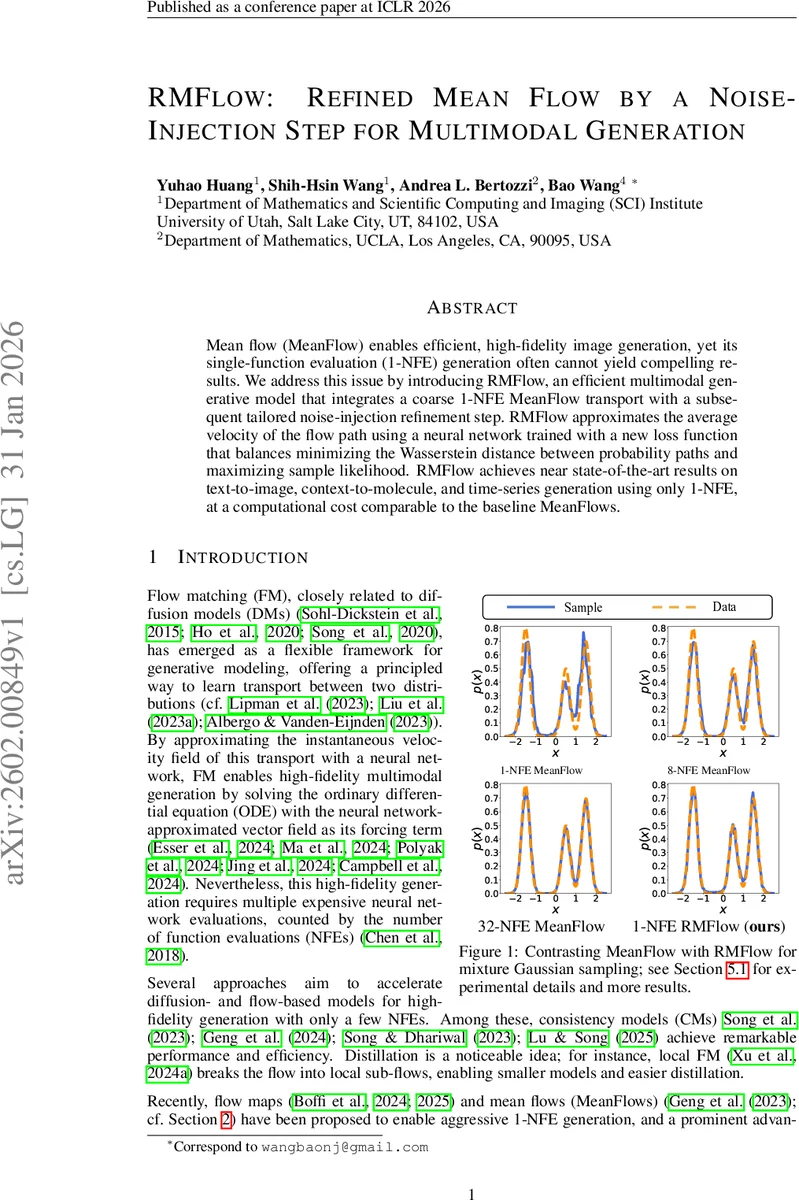
Mean flow (MeanFlow) enables efficient, high-fidelity image generation, yet its single-function evaluation (1-NFE) generation often cannot yield compelling results. We address this issue by introducing RMFlow, an efficient multimodal generative model that integrates a coarse 1-NFE MeanFlow transport with a subsequent tailored noise-injection refinement step. RMFlow approximates the average velocity of the flow path using a neural network trained with a new loss function that balances minimizing the Wasserstein distance between probability paths and maximizing sample likelihood. RMFlow achieves near state-of-the-art results on text-to-image, context-to-molecule, and time-series generation using only 1-NFE, at a computational cost comparable to the baseline MeanFlows.
💡 Research Summary
RMFlow (Refined Mean Flow by a Noise‑Injection Step for Multimodal Generation) tackles the well‑known degradation of quality that occurs when MeanFlow—a recent 1‑NFE (single function evaluation) generative approach—is forced to operate with only a single evaluation step. Classical MeanFlow transports a prior sample directly to the target distribution by learning an average velocity field ˆu₀,₁(x₀;θ) and applying it once (x₁ = x₀ + ˆu₀,₁). While this yields impressive results with multiple NFEs, collapsing to 1‑NFE typically produces blurry images, invalid molecular graphs, or poor density estimates.
RMFlow augments this coarse transport with a carefully designed noise‑injection refinement. After the 1‑NFE MeanFlow step, an additional Gaussian perturbation is added:
x̂_tgt = x₀ + ˆu₀,₁(x₀;θ) + √(σ_min² – σ²)·ε₂, ε₂ ∼ N(0, I).
This step mirrors the decoder of a Variational Auto‑Encoder and enables a principled likelihood maximization. The conditional distribution of the final sample given the prior becomes a Gaussian with mean x₀ + ˆu₀,₁ and variance (σ_min² – σ²)I, allowing the authors to introduce a negative log‑likelihood loss L_NLL that directly penalizes the squared distance between the noisy target (x_data + σ_min ε) and the generated mean.
The training objective combines three components:
- L_CMFM – the original Conditional Mean Flow Matching loss, which bounds the Wasserstein‑2 distance between the learned and true probability flows.
- λ₁ L_NLL – the likelihood term that drives KL divergence reduction, formally proven in Theorem 4.1 to provide a lower bound on the expected log‑likelihood of the target distribution.
- **λ₂ E
Comments & Academic Discussion
Loading comments...
Leave a Comment